
Fortran developers have long been able to accelerate their programs using CUDA Fortran or OpenACC.
For more up-to-date information, please read Using Fortran Standard Parallel Programming for GPU Acceleration, which aims to instruct developers on the advantages of using parallelism in standard languages for accelerated computing.
Now with the latest 20.11 release of the NVIDIA HPC SDK, the included NVFORTRAN compiler automatically accelerates DO CONCURRENT, allowing you to get the benefit of the full power of NVIDIA GPUs using ISO Standard Fortran without any extensions, directives, or non-standard libraries.
For more up-to-date information, please read Using Fortran Standard Parallel Programming for GPU Acceleration, which aims to instruct developers on the advantages of using parallelism in standard languages for accelerated computing.
You can now write standard Fortran, remaining fully portable to other compilers and systems, and still benefit from the full power of NVIDIA GPUs. NVFORTRAN was built so that you can spend less time porting and more time on what really matters—solving the world’s problems with computational science.
ISO Standard Fortran 2008 introduced the DO CONCURRENT construct to allow you to express loop-level parallelism, one of the various mechanisms for expressing parallelism directly in the Fortran language. In this post, we focus on DO CONCURRENT. For more information about how the NVIDIA HPC SDK automatically accelerates Fortran array intrinsics on NVIDIA GPUs, see Bringing Tensor Cores to Standard Fortran.
NVIDIA HPC SDK
The NVIDIA HPC SDK is a comprehensive suite of compilers, libraries, and tools used to GPU-accelerate HPC applications. With support for NVIDIA GPUs and x86-64, OpenPOWER, or Arm CPUs running Linux, the NVIDIA HPC SDK provides proven tools and technologies for building cross-platform, performance-portable, and scalable HPC applications.
The NVIDIA HPC SDK includes the NVIDIA HPC Fortran compiler, NVFORTRAN. NVFORTRAN supports Fortran 2008, CUDA Fortran, OpenACC, and OpenMP.
Enabling Standard Parallelism
GPU acceleration of DO CONCURRENT is enabled with the -stdpar command-line option to NVFORTRAN. If -stdpar is specified, the compiler does the parallelization of the DO CONCURRENT loops and offloads them to the GPU. All data movement between host memory and GPU device memory is performed implicitly and automatically under the control of CUDA Unified Memory.
A program can be compiled and linked with the following command:
nvfortran -stdpar program.f90 -o program
It is also possible to target a multi-core CPU with the following command:
nvfortran -stdpar=multicore program.f90 -o program
You can also compile a program to run on either a CPU or GPU using the following command. If your system has a GPU, the program runs on the GPU. If not, the program runs on the CPU.
nvfortran -stdpar=gpu,multicore program.f90 -o program
Start accelerating Fortran DO CONCURRENT with NVIDIA GPUs
To get started with GPU acceleration of Standard Fortran, all that’s required is expressing parallelism with DO CONCURRENT. The NVFORTRAN compiler generates code to run the iterations across GPU threads and thread blocks, or run them across host threads. The compiler can choose different mappings depending on the underlying hardware.
SAXPY
SAXPY is a simple vector operation that computes a vector-scalar multiplication with a scalar addition: y = a*x + y. A Fortran subroutine that does this might look like the following:
1 subroutine saxpy(x,y,n,a) 2 real :: a, x(:), y(:) 3 integer :: n, i 4 do i = 1, n 5 y(i) = a*x(i)+y(i) 6 enddo 7 end subroutine saxpy
For this code, the compiler generates n iterations of line 5, y(i) = a*x(i) + y(i). The n loop iterations are executed sequentially when the program runs.
However, this algorithm can be parallelized to improve performance. Given enough resources, each of the n iterations can be executed simultaneously. In ISO Standard Fortran, you can express this by rewriting the SAXPY example with DO CONCURRENT:
1 subroutine saxpy(x,y,n,a) 2 real :: a, x(:), y(:) 3 integer :: n, i 4 do concurrent (i = 1: n) 5 y(i) = a*x(i)+y(i) 6 enddo 7 end subroutine saxpy
By changing the DO loop to DO CONCURRENT, you are telling the compiler that there are no data dependencies between the n loop iterations. This leaves the compiler free to generate instructions that the iterations can be executed in any order and simultaneously. The compiler parallelizes the loop even if there are data dependencies, resulting in race conditions and likely incorrect results. It’s your responsibility to ensure that the loop is safe to be parallelized.
Now, compile this program with -stdpar, which enables parallelism on an NVIDIA GPU. To see more information about the parallelization that the compiler enables, use the -Minfo flag with NVFORTRAN:
nvfortran -stdpar -Minfo=accel saxpy.f90 -o saxpy
NVFORTRAN prints the following -Minfo message, which indicates that the compiler parallelizes the DO CONCURRENT loop. For the NVIDIA GPU target, the compiler applies fine-grained parallelism. It distributes DO CONCURRENT iterations across the thread blocks and threads of the GPU kernel. As a result, the code takes advantage of the massive parallelism available in the GPU automatically.
saxpy:
4, Offloading Do concurrent
Generating Tesla code
4, Loop parallelized across CUDA thread blocks, CUDA threads(128) blockidx%x threadidx%x
You can find the full SAXPY example included with the NVIDIA HPC SDK. After downloading, the code is located at /path/to/nvhpc/<platform>/<version>/examples/stdpar/saxpy/saxpy.f90.
Coding guidelines
In this section, we make some recommendations for getting optimal results when expressing parallelism in standard Fortran using DO CONCURRENT.
Express more parallelism
Nested loops are a common code pattern encountered in HPC applications. A simple example might look like the following:
24 do i=2, n-1 25 do j=2, m-1 26 a(i,j) = w0 * b(i,j) 27 enddo 28 enddo
It is straightforward to write such patterns with a single DO CONCURRENT statement, as in the following example. It is easier to read, and the compiler has more information available for optimization.
25 do concurrent(i=2 : n-1, j=2 : m-1) 26 a(i,j) = w0 * b(i,j) 27 enddo
If you compile this code with -stdpar -Minfo, youcan see how the compiler performs the parallelization. It first collapses the two loops as expressed by DO CONCURRENT and parallelizes them together across the thread blocks and threads of the GPU kernel.
25, Offloading Do concurrent
Generating Tesla code
25, Loop parallelized across CUDA thread blocks, CUDA threads(128) collapse(2) ! blockidx%x threadidx%x collapsed-innermost
Loop parallelized across ! blockidx%x threadidx%x auto-collapsed
Array assignments
Fortran has syntax for array assignments that are commonly used. The compiler can automatically detect and parallelize the array assignments in the DO CONCURRENT loop. Here’s is an example:
4 do concurrent(i=1:N) 5 i0 = max(i-1,1) 6 i1 = min(i+1,N) 7 b(:,:,i) = 0.5 * (a(:,:,i0) + a(:,:,i1)) ! array assignment 8 end do
Look at the following parallelization message. The compiler first parallelizes the DO CONCURRENT loop across the thread blocks and then parallelizes the array assignment across the threads. In doing so, it uses a multi-dimensional kernel and makes use of massive parallelism to the fullest.
4, Offloading Do concurrent4, Generating Tesla code 4, Loop parallelized across CUDA thread blocks ! blockidx%x 7, Loop parallelized across CUDA threads(128) collapse(2) ! threadidx%x
Using localities with DO CONCURRENT
Another requirement in HPC programs is data privatization. This can be expressed with the standard Fortran DO CONCURRENT statement:
DO CONCURRENT (concurrent-header) [locality-spec]
In that statement, the locality-spec value is one of the following:
local(variable-name-list) local_init(variable-name-list) share*d*(variable-name-list) default(none)
Each thread of the DO CONCURRENT loop can have its own array by use of the local clause. If you also want its first value, then you can use local_init. Look at the following example:
2 real::vals(100) ... 5 do concurrent(i=0:n) local(vals) 6 do j=0, 100 7 vals(...) = ... 8 enddo 9 ... = vals(...) 10 enddo
The compiler created vals for each processing unit on the outer loop and located vals into the faster CUDA shared memory.
5, Generating Tesla code 5, Loop parallelized across CUDA thread blocks ! blockidx%x 6, Loop parallelized across CUDA threads(128) ! threadidx%x 5, CUDA shared memory used for vals
However, you should be careful when privatizing variables. If the compiler cannot locate them in the shared memory, they would be created in the GPU’s global memory, which can sometimes hurt performance. For this reason, it is important to pay attention to the -Minfo output when privatizing variables.
Limitations
There are a few limitations for the usage of DO CONCURRENT when using NVFORTRAN. First, procedure calls inside of a DO CONCURRENT loop are not permitted in the 20.11 release of NVFORTRAN. Secondly, there is no support for reductions in the Fortran 2018 standard specification that can be used with DO CONCURRENT. However, as this feature makes it into the working draft of the Fortran standard, NVFORTRAN will provide a preview implementation so that you can use standard parallelism features in your Fortran programs that also need to perform a reduction.
Jacobi example
Here’s a look at a slightly larger example, using the Jacobi method to solve the two-dimensional heat equation. A simple application of this equation is to predict the steady-state temperature distribution in a square plate that is heated on one side or corner. The Jacobi method consists of approximating the square plate with a two-dimensional grid of points where a two-dimensional array is used to store the temperature at each of these points. Each iteration updates the elements of the array from the values computed at the previous step.
In the following code example, you see the main computational kernel that updates the temperature on a 2D grid of points. It uses DO CONCURRENT loops to step through the 2D iteration space using the combined indexing capability of DO CONCURRENT as described earlier. This expresses more parallelism and allows the compiler to easily collapse the loops for greater optimization opportunities.
21 subroutine smooth( a, b, w0, w1, w2, n, m, niters ) 22 real, dimension(:,:) :: a,b 23 real :: w0, w1, w2 24 integer :: n, m, niters 25 integer :: i, j, iter 26 do iter = 1,niters 27 do concurrent(i=2 : n-1, j=2 : m-1) 28 a(i,j) = w0 * b(i,j) + & 29 w1 * (b(i-1,j) + b(i,j-1) + b(i+1,j) + b(i,j+1)) + & 30 w2 * (b(i-1,j-1) + b(i-1,j+1) + b(i+1,j-1) + b(i+1,j+1)) 31 enddo 32 do concurrent(i=2 : n-1, j=2 : m-1) 33 b(i,j) = w0 * a(i,j) + & 34 w1 * (a(i-1,j) + a(i,j-1) + a(i+1,j) + a(i,j+1)) + & 35 w2 * (a(i-1,j-1) + a(i-1,j+1) + a(i+1,j-1) + a(i+1,j+1)) 36 enddo 37 enddo 38 end subroutine
If you compile this code with -stdpar -Minfo, you can see how the compiler parallelizes the loops:
smooth:
27, Offloading Do concurrent
Generating Tesla code
27, Loop parallelized across CUDA thread blocks, CUDA threads(128) collapse(2) ! blockidx%x threadidx%x collapsed-innermost
Loop parallelized across ! blockidx%x threadidx%x auto-collapsed
32, Offloading Do concurrent
Generating Tesla code
32, Loop parallelized across CUDA thread blocks, CUDA threads(128) collapse(2) ! blockidx%x threadidx%x collapsed-innermost
Loop parallelized across ! blockidx%x threadidx%x auto-collapsed
Jacobi performance
Figure 1 shows an almost 13x improvement in performance by running your completely ISO Standard Fortran code on a GPU compared to all 40 cores of a CPU. This means that you don’t have to “port” your code to run on the GPU. Recompile using NVFORTRAN and standard Fortran DO CONCURRENT, and you are ready to gain the acceleration benefits of an NVIDIA GPU. Because the parallelism is expressed in Fortran with no other additional languages or hints, the same code can be compiled with multiple compilers and run efficiently on both multicore CPUs and NVIDIA GPUs.
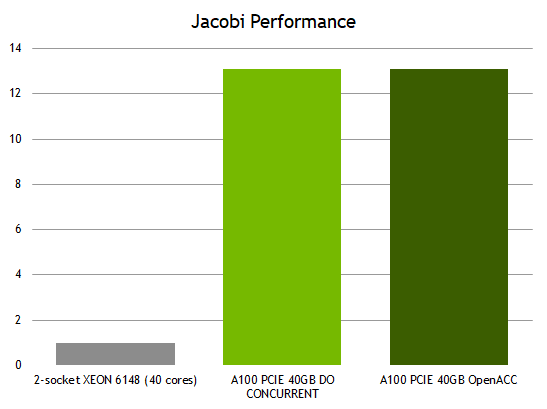
In this case, the ISO Fortran implementation can show nearly the same performance as the OpenACC implementation, which targeted heterogeneous systems explicitly. While performance varies depending on application characteristics, this shows the power of ISO language parallelism leveraging CUDA Unified Memory, allowing you to program in a single, familiar, parallel programming language.
You can find the full example included with the HPC SDK at /path/to/nvhpc/<platform>/<version>/examples/stdpar/jacobi/jacobi.f90.
Start running your Fortran programs on GPUs using DO CONCURRENT
You can start using DO CONCURRENT to get parallelism in your ISO Standard Fortran programs today on all NVIDIA GPUs, starting from the Pascal architecture and newer. To get started, download and install the NVIDIA HPC SDK on your x86-64, OpenPOWER, or Arm CPU-based system running a supported version of Linux.
The NVIDIA HPC SDK is freely available. After you have the NVIDIA HPC SDK installed on your system, the NVFORTRAN compiler is available under the /opt/nvidia/hpc_sdk directory structure.
- To use the 20.11 version of the compilers including NVFORTRAN on a Linux/x86-64 system, add the directory
/opt/nvidia/hpc_sdk/Linux_x86_64/20.11/compilers/binto your path. - On an OpenPOWER or Arm CPU-based system, replace
Linux_x86_64withLinux_ppc64leorLinux_aarch64, respectively.
Supported NVIDIA GPUs
The NVFORTRAN compiler can automatically offload DO CONCURRENT loops to all NVIDIA GPUs starting from the Pascal architecture and newer. By default, NVFORTRAN auto-detects and generates GPU code for the type of GPU that is installed on the system on which the compiler is running.
To generate code for a specific GPU architecture, which may be necessary when the application is compiled and run on different systems, add the -gpu=ccXX command-line option to specify the desired compute capability. In addition, the compiler can generate executables targeted for multiple GPU architectures. For example, you can use the -gpu=cc70,cc80 option to generate code for Volta and Ampere architectures in a single binary.
The NVFORTRAN compiler can use CUDA libraries and technologies, so the NVIDIA HPC SDK compilers ship with an integrated CUDA toolchain, header files, and libraries to use during compilation. You don’t have to have the CUDA Toolkit installed on the system to use NVFORTRAN or the other HPC compilers from the HPC SDK.
When -stdpar is specified, NVFORTRAN uses the CUDA toolchain version that matches the CUDA driver installed on the system where the compilation is performed. To compile using a different version of the CUDA toolchain, use the -gpu=cudaX.Y option. For example, use the -gpu=cuda11.0 option to specify that your program should be compiled for a CUDA 11.0 system using the 11.0 toolchain.
Summary
Parallel programming using standard language constructs offers clear benefits to HPC programmers. Using standard languages, you can compile your code to run on GPUs with no changes to your underlying source code, and have them perform at a level comparable to code using other programming models. Codes written using standard language constructs can be compiled today to run on all HPC platforms. Finally, standard languages enhance code efficiency and aid programmer productivity so that you can maximize your throughput and minimize your coding time.
The Fortran standard allows you to write code that expresses parallelism using DO CONCURRENT. Starting with the 20.11 release, NVFORTRAN enables truly performance-portable parallel programs across multicore CPUs and NVIDIA GPUs. In this post, we showed you how to get an almost 13x performance improvement when moving a Jacobi solver from all 40 cores of a CPU to an NVIDIA A100 GPU, all without any changes to the standard Fortran code.
