This post is the third in a series on Autonomous Driving at Scale, developed with Tata Consultancy Services (TCS). The previous posts provided a general overview of deep learning inference for object detection and covered the object detection inference process and object detection metrics. In this post, we conclude with a brief look at the optimization techniques and deployment of an end-to-end inference pipeline.
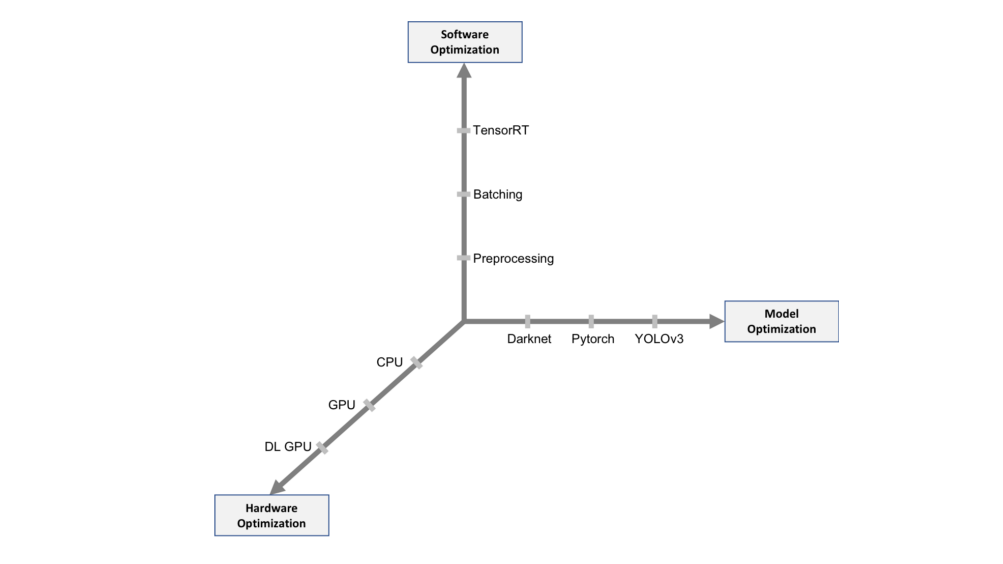
In this post, we look at the inference optimization process in three dimensions: hardware optimization, software optimization, and model optimization with the help of the following framework. The critical metrics for inference optimization are as follows:
- Throughput (no of images inferred/second)
- Hardware cost
- Memory
- Energy consumption
- Quality
Model optimization
The YOLOv3-416 model, when used as a pr-trained model, performs optimally with a compatible dataset. When used as a base model, the hyperparameters need to be tuned to fit a custom dataset better. The architectural choices and configurations available in YOLOv3 to consider are listed below:
- The 106 layers of fully convolutional underlying architecture are more layers than YOLOv2, and the more layers, the slower the performance.
- Deep residual layers, which use skip connections, are implemented to address the degradation problem and accuracy saturation, which is a typical symptom of deeper networks reaching convergence.
- We use a total of nine anchor boxes, three for each scale. The context of the anchor boxes, carefully chosen based on the analysis of the size of objects in the MS COCO dataset defines the predicted bounding boxes. The anchor boxes are configurable. The detector works at three different scales ranging from scale 1, picking up larger objects, to scale 3, picking up the smaller objects.
- The bounding boxes predictions happen at three different scales; at each scale, every grid can predict three boxes using three anchors. For an input image of 416 x 416, the number of predicted boxes is 10,647.
- Object confidence and class predictions happen through logistic regression. When training the detector, for each ground truth box, a bounding box, whose anchor has the maximum overlap with the ground truth box, is assigned.
- Prediction of hierarchical classes like “Person” and “Women” in a dataset use the logistic regression with a threshold applied to handle multiple labels for objects detected in images, and the classes with scores higher than the threshold assigned to the bounding box.
- The model performance is optimal at 416 x 416 input resolution. Fewer detections occur at lower resolutions. At larger input resolutions, the performance misses detection or sometimes detects false positives. Also, larger input resolutions add to inference time and the resolutions should be a multiple of 32.
- Other configurable parameters can be tuned as needed, such as the batch size, objectness confidence, and non-max suppression threshold.
- Post-processing NMS runs only on the CPU and takes up the bulk of the running time.
- The choices to balance accuracy and speed that impact the performance also include output strides for the extractor, IOU threshold, data augmentation, localization loss function, deep learning framework used, and such.
Hardware optimization
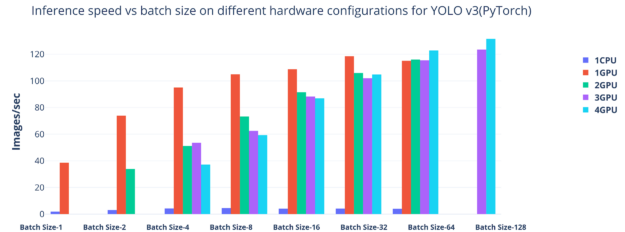
We ran the inference server on a single CPU, single GPU, and multi-GPUs with different batch sizes. As observed, the inference performance was superior when running in a GPU environment. With smaller batch sizes, we underutilized the multi-GPUs, and with a maximum batch size of 128, the throughput was highest with four GPUs.
Tensor Cores introduced initially with NVIDIA Volta architecture are the workhorse of mixed-precision training. PyTorch supports mixed-precision using FP32 and FP16 data types, maximizing Volta and Turing Tensor Core usage effectively. Performing multiplication in 16-bit and then summation in 32-bit accumulation results in energy and area cost optimization.
Software optimization
PyTorch provides high-level features such as tensor computation with strong GPU acceleration, whether it is putting a model on a GPU or copying tensors to GPU. We use the PyTorch container available on NVIDIA NGC, a hub of GPU-optimized software, optimized for scalable performance with support for multi-GPU and multi-node systems. The containerized environment makes the entire object detection stack built on top of the PyTorch framework portable and hassle-free. It is a deployment capable of running anywhere across the range of Pascal, Volta, or Turing-powered NVIDIA DGX, workstations, servers, and leading cloud platforms.
We used DataParallel to maximize the utilization across four GPUs. It splits the data automatically and distributes them among multiple models on several GPUs, and the output consolidated. With four NVIDIA V100 GPUs, we were able to increase inference throughput per iteration, and the batch size increased to 128 images with four GPUs and one GPU. The number of CPUs needs to be high enough to avoid bottlenecks in data pre- and post-processing. Eight CPUs are required to achieve 131 FPS inferencing speed.
Several techniques, such as pruning, weight sharing, and quantization, are additional optimization methods that can be applied to enhance the performance of the algorithm.
Tensor RT optimization
Frameworks such as PyTorch are flexible, to express the prescribed network architecture, and fast, because they are preconfigured with libraries like cuDNN. The cuDNN library efficiently implements the low-level atomic operations to perform convolutions, matrix multiplications, and such in CUDA. The flexibility offered by frameworks like PyTorch, however, does add an overhead affecting the overall inference performance after deployment.
TensorRT is a library designed to optimize the inference performance. TensorRT is composed of an optimizer and the runtime engine. The optimizer is a one-time operation responsible for optimizing the model graph by specifying the inference batch size and the FP-32, FP-16, or 8-bit INT precision to output an optimized model or the plan serialized onto storage. The TensorRT runtime engine loads the optimized model from storage to execute inference at runtime. Among support for other frameworks, the model importer supports the import of PyTorch-based models through ONNX format into TensorRT. torch2trt is a PyTorch-to-TensorRT converter that uses the TensorRT Python API.
Deployment at scale: Dockerzing the inference code
The rise of Docker as a containerization platform has hugely simplified the process of creating, deploying, and managing distributed applications. Docker containers allow the software packaging along with their core components and dependencies as a standard unit, which can then be reliably run in any computing environment.
Using PyTorch-YOLOv3 systems
The PyTorch container pulled from NGC serves as the framework for the object detection applications stack. NGC is home to the following resources:
- Highly optimized containers for frameworks such as TensorFlow, RAPIDS, and PyTorch.
- Pretrained models and model scripts such as BERT, ResNet50, and Net.
- Kubernetes-ready Helm charts for applications such as NVIDIA Clara and NVIDIADeepStream.
Building the application involves installing a few Python dependency packages like libopencv-dev. This package helps in real-time image processing. Other Python-based packages are needed to run this application, such as NumPy, Matplotlib, Pillow, Tqdm, and OpenCV-python. The PyTorch container hosted on NGC includes all of these packages.
Prerequisites for running NGC GPU containers
NGC containers run out of the box on NGC-ready systems such as NVIDIA DGX systems, workstations, and virtualized environments with NVIDIA compute server.
Most cloud service providers (CSPs) provide machine images that come baked in with the necessary NVIDIA drivers, Docker versions, and container toolkits. Here are the NVIDIA machine images corresponding to some of the most common CSPs:
- Amazon Web Services: NVIDIA Volta AMI, accessible through the marketplace
- Microsoft Azure: NGC Image
- Google Cloud: NVIDIA Cloud Image for Deep Learning and HPC
As an alternate, the following packages must be installed in the VM running on systems equipped with NVIDIA GPUs:
- NVIDIA Container Toolkit: The CUDA Toolkit provides the development environment and includes GPU-accelerated libraries, debugging and optimization tools, a C/C++ compiler, and a runtime library to deploy the application.
- NVIDIA-driver: Downloading the driver corresponding to the GPUs from NVIDIA makes the OS and other applications “GPU-aware”.
Running the PyTorch-YOLOv3 container
You can run the containerized PyTorch-YOLOv3 application. Host paths can be mounted with a bind mount and the container paths to input the source data directly from the host machine and to store its output in the host machine.
To use all the GPUs available in the machine while running a container, mention --gpus all as shown in the following command. You can run the container with a limited number of GPUs by replacing the highlighted part in the following command with --gpus=<no-of-gpus>. You can even run this container using only CPUs by removing the highlighted portion in the command.
$ sudo docker run -it --gpus all -v (input-host-path):(input-container-path) -v (output-host-paths):(output-container-paths) <PyTorch-YOLOv3-image>
Conclusion
The autonomous vehicle industry is continuously looking at the technology innovation needed to move from the current state to deployable safe, self-driving vehicles. An array of neural networks forms a base for the perception and decision-making abilities of autonomous vehicles. AI annotation models inference ease the process of labeling new training data for developing neural networks that form the core of the autonomous vehicles’ software development stack, saving valuable time and resources.
In this series, we covered a lot of ground detailing the data annotation pipeline in the autonomous driving context, including setup, inferencing, performance metrics, optimization, deployment, and runtime of the end-to-end object detection pipeline running on GPUs using NVIDIA Docker from NGC and leveraging TensorRT.
Tata Consultancy Services (TCS) is an IT services, consulting and business solutions organization that has partnered with many of the world’s largest businesses in their transformation journeys for the last 50 years. TCS offers a consulting-led, cognitive- powered, integrated portfolio of IT, business and technology services, and engineering. This is delivered through its unique Location Independent Agile delivery model, recognized as a benchmark of excellence in software development. TCS has more than 448,000 employees in 46 countries with $22 billion in revenues as of March 31, 2020.
TCS Automotive Industry Group focuses on delivering solutions and services to address the CASE ( Connected, Autonomous, Shared and Electric) ecosystem and partners with industry-leading players to address the opportunities evolving from disruption in the automotive industry.
To stay up-to-date on TCS news in North America, follow us on Twitter @TCS_NA and LinkedIn @Tata Consultancy Services – North America. For TCS global news, follow @TCS_News.
