
Today’s large language models (LLMs) achieve unprecedented results across many use cases. Yet, application developers often need to customize and tune these models to work specifically for their use cases, due to the general nature of foundation models.
Full fine-tuning requires a large amount of data and compute infrastructure, resulting in model weights being updated. This method requires multiple instances of a model being hosted and run on GPU memory to serve many use cases on a single device.
Example use cases include a multilingual translation assistant, where a user needs results simultaneously and in multiple languages. This can be a challenge for on-device AI, due to memory constraints.
Hosting multiple LLMs on device memory simultaneously is nearly impossible, especially when considering running suitable latency and throughput requirements to engage with users. On the other hand, users often run multiple apps and tasks at any given time, sharing system resources across applications.
Parameter-efficient fine-tuning techniques such as low-rank adaptation (LoRA) help developers attach custom adapters to a single LLM to serve multiple use cases. This requires minimal additional memory, while still providing capabilities for task-specific AI. The technique makes it easy for developers to scale the number of use cases and applications that can be served on-device.
Multi-LoRA support is now available in NVIDIA TensorRT-LLM, part of the NVIDIA RTX AI Toolkit. This new feature enables RTX AI PCs and workstations to handle various use cases during inference time.
Introduction to LoRA
LoRA emerged as a popular parameter-efficient fine-tuning technique that tunes a small amount of parameters. The additional parameters are called LoRA adapters, representing the low-rank decomposition of the changes in the dense layers of the network.
Only these low-rank additional adapters are customized, while the remaining parameters of the model are held frozen during the process. Once trained, these adapters are deployed by merging into the foundation model during inference time, adding minimal to no overhead on inference latencies and throughput.

(credit: LoRA: Low-Rank Adaptation of Large Language Models)
Figure 1 showcases additional details on the LoRA technique:
- The weights (W) of the pretrained model are frozen during customization.
- Instead of updating W, two smaller trainable matrices, A and B are injected, which learn task-specific information. The matrix multiplication B*A forms a matrix with the same dimensions as W, thus it can be added to W (= W + BA).
The ranks of A and B matrices are small values like 8, 16, and so on. This rank (r) parameter is customizable at training time. A larger rank value enables the model to capture more nuances relevant to the downstream task, approaching the capacity of fully supervised fine-tuning by updating all the parameters in the model.
On the downside, larger ranks are also more expensive for training and inference, in terms of memory and compute requirements. In practice, LoRA fine-tuning with a rank value as small as eight is already very effective and is a good starting point for many downstream tasks.
Today, within the RTX AI Toolkit there’s support for quantization and low-rank adaptation (QLoRA), a variation of the LoRA technique, to perform parameter-efficient fine-tuning on RTX systems. This technique is an adaptation that reduces memory usage.
During backpropagation, gradients are passed through a frozen, 4-bit quantized pretrained model into low-rank adapters. Effectively, the QLoRA algorithm saves memory, without sacrificing model performance. Refer to the following paper for additional information on QLoRA.
Multi-LoRA support in TensorRT-LLM
With the latest updates in TensorRT-LLM, RTX AI Toolkit now natively supports the ability to serve multiple LoRA adapters with a single quantized base checkpoint at inference time. This new technique enables serving multiple FP16 LoRA adapters with INT4 quantized base-model checkpoints.
Mixed-precision deployments can be useful in Windows PC environments as they have limited memory that must be shared across apps. Mixed-precision deployments can help by reducing the memory needed for model storage and inference, without sacrificing model quality or the ability to serve multiple clients with custom models.
There are several ways in which a developer can deploy multiple LoRA adapters in their application and they include the following.
Single LoRA adapter deployment
In this setup, developers choose which LoRA adapter to activate for each request best for serving specialized content. For example, a language learning app can switch between adapters fine-tuned for different languages, offering focused practice based on the user’s current needs.
Concurrent LoRA adapters for a single request (batch mode)
In this method, a single input prompt generates multiple different responses, with each response produced by a different LoRA adapter in batch mode. This is useful for complex applications like a multilingual virtual assistant, where one query can simultaneously yield responses in English, Spanish, and Japanese, each tailored by a specific adapter.
Concurrent LoRA adapters for multiple requests (batch mode)
This approach processes several input prompts at the same time. Each prompt is paired with a different LoRA adapter and generates multiple output prompts. For example, multiple PC applications send inference requests to the same model, and depending on the request, a different adapter is selected, ensuring that each application receives a tailored response specific to its needs.
Learn more about TensorRT-LLM support for multiple LoRA adapter checkpoints.
Showcasing the power of multi-LoRA on RTX PCs
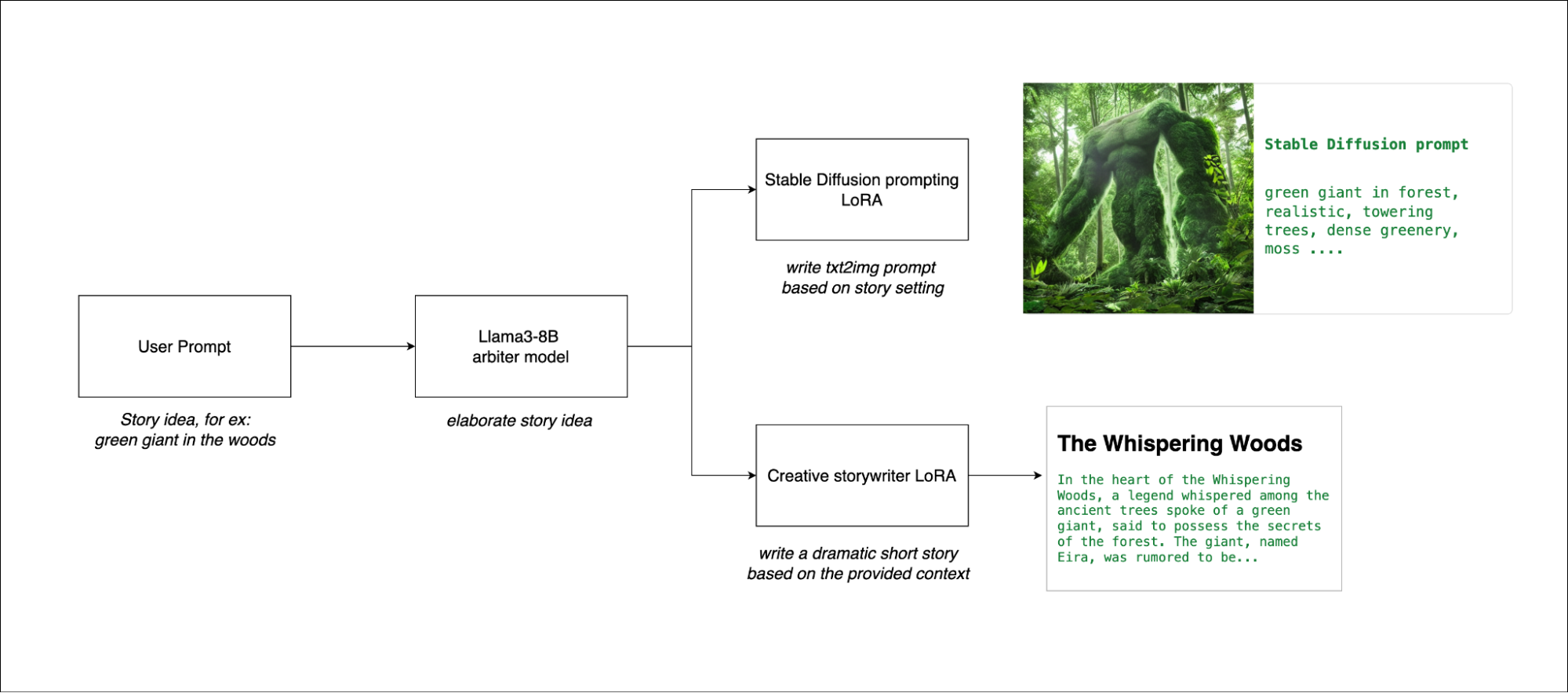
To demonstrate the power of multi-LoRA support, we’ve developed a sample application designed for story creation and illustration driven by a single prompt. The process unfolds in two key steps.
- The user inputs a basic idea for a story, and the Llama 3 model fleshes out this concept, expanding on the initial idea to provide a detailed foundation.
- The application uses the same Llama 3 model, now enhanced with two distinct LoRA adapters, to further refine the story and generate corresponding imagery. One LoRA adapter generates a Stable Diffusion prompt, which is used to illustrate the story visually through a locally deployed Stable Diffusion XL model. The other is fine-tuned for story writing, and crafts a well-structured and engaging narrative.
This approach ensures that the space required for the process doesn’t increase significantly, as the same model is used for both passes. The second pass, which involves text and image generation, is performed using batched inference, making the process fast and efficient. Users can rapidly iterate through different versions of their stories, refining the narrative and illustrations easily.
By using multi-LoRA support in this streamlined two-step process, we showcase how creative and computational efficiency can be maximized, all from a single prompt. The following is a sample set of input-output pairs.
User Prompt:
Generated Story:
*The Whispering Woods*
In the heart of the Whispering Woods, a legend whispered among the ancient trees spoke of a green giant, said to possess the secrets of the forest. The giant, named Eira, was rumored to be able to communicate with the trees themselves, and its presence was said to bring balance and harmony to the forest. One day, a young adventurer named Lyra stumbled upon the clearing where Eira was said to reside. As she approached the giant, she felt an eerie silence fall over the clearing, as if the trees themselves were holding their breath in anticipation. Eira's massive form loomed before her, its skin a deep, mossy green that seemed to blend seamlessly into the surrounding foliage. The giant's eyes, like ancient pools of wisdom, gazed down at Lyra with a gentle intensity.
As she drew closer, Lyra noticed that the trees around her were indeed communicating with Eira, their leaves rustling softly to convey ancient secrets and whispers of the forest. The air was thick with the scent of damp earth and decaying leaves, and Lyra felt the weight of the forest's history bearing down upon her.
Eira's voice, like a gentle breeze, whispered secrets to the trees, and they responded with soft murmurs and creaks. Lyra felt a sense of wonder wash over her as she realized that the giant was indeed the keeper of the forest's secrets. She reached out a trembling hand, and to her surprise, Eira's massive fingers wrapped around hers, like a gentle giant's grasp.
In that moment, Lyra felt the forest's balance and harmony flow through her, and she knew that she had stumbled upon something much greater than a mere legend. As she stood there, surrounded by the ancient trees and the whispers of the forest, Lyra felt a sense of belonging wash over her, as if she had finally found her true home.
Accelerating multi-LoRA use cases on Windows PCs with TensorRT-LLM
The following figure shows NVIDIA internal measurements showcasing throughput performance on the NVIDIA GeForce RTX 4090 using a Llama-3-8B model, with the foundation model and multiple LoRA adapters at varying batch sizes using TensorRT-LLM.
The results show throughput at an input sequence length of 43 and an output sequence length of 100 tokens. At batch sizes larger than 1, each sample uses a unique LoRA adapter with a maximum engine rank of 64.
Higher throughput is better and we see about a 3% performance degradation when running multiple LoRA adapters.
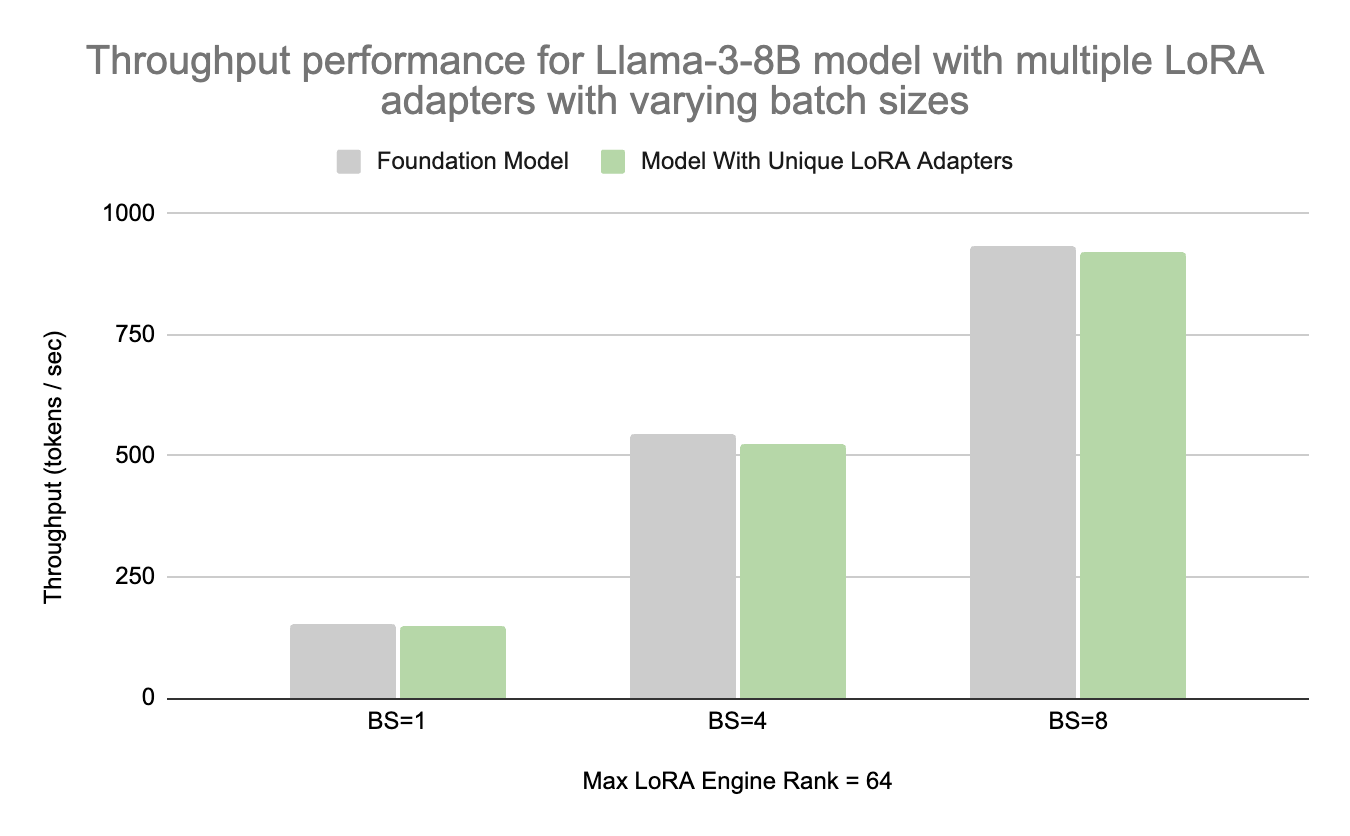
Figure 5 shows NVIDIA latency performance measurements on an RTX 4090 PC using a Llama-3-8B model with both the pre-trained foundation model and multiple LoRA adapters at varying batch sizes using TensorRT-LLM 0.11.
The results showcase latency at an input sequence length of 43, and an output sequence length of 100 tokens. At batch sizes larger than 1, each sample uses a unique LoRA adapter with a maximum engine rank of 64. Lower latency is better and we see about a 3% performance degradation when running multiple LoRA adapters.

Figures 4 and 5 show that TensorRT-LLM 0.11 delivers great performance with minimal throughput and latency degradation across batch sizes when using multiple LoRA adapters at inference time. On average, we see about a 3% reduction in throughput and latency performance across batch sizes compared to running the foundation model, when using multiple unique LoRA adapters with TensorRT-LLM 0.11.
Next steps
With the latest updates, developers can customize models with LoRA techniques on device, and deploy models to serve multiple use cases using multi-LoRA support on RTX AI PCs and workstations.
Get started with multi-LoRA on TensorRT-LLM.
