
As of March 18, 2025, NVIDIA Triton Inference Server is now part of the NVIDIA Dynamo Platform and has been renamed to NVIDIA Dynamo Triton, accordingly.
The demand for AI-enabled services continues to grow rapidly, placing increasing pressure on IT and infrastructure teams. These teams are tasked with provisioning the necessary hardware and software to meet that demand while simultaneously balancing cost efficiency with optimal user experience. This challenge was faced by the inference team at Perplexity AI, an AI-powered search engine that handles more than 435 million queries each month. Each query represents multiple AI inference requests.
To meet this demand, the Perplexity inference team turned to NVIDIA H100 Tensor Core GPUs, NVIDIA Triton Inference Server, and NVIDIA TensorRT-LLM for cost-effective large language model (LLM) deployment. This post details some of the deployment best practices and TCO savings based on their hands-on experience.
Serving multiple AI models simultaneously
To support its extensive user base and serve a wide range of requests—spanning search, summarization, and question answering, among others—the inference team at Perplexity serves over 20 AI models simultaneously. This includes different variations of the popular open source Llama 3.1 models like 8B, 70B, and 405B.
To match each user request with the appropriate model, the company relies on smaller classifier models that help determine user intent. User tasks detected by the classifiers, like text completion, are then routed to specific models deployed on GPU pods. Each pod consists of one or more NVIDIA H100 GPUs and is managed by an NVIDIA Triton Inference Server instance. The pods operate under strict service-level agreements (SLAs) for both cost efficiency and user interactivity.

To accommodate the large Perplexity user base and fluctuating traffic throughout the day, the pods are hosted within a Kubernetes cluster. They feature a front-end scheduler built in-house that routes traffic to the appropriate pod based on their load and usage, ensuring that the SLAs are consistently met.
The scheduling algorithm used by the front-end scheduler can affect inter-token latency, particularly in improving the worst percentile of performance (Figure 2). The team at Perplexity constantly looks for new scheduler optimizations, including how to better account for sequence length variations across requests.

Triton Inference Server is a critical component of Perplexity’s deployment architecture. It serves optimized models across various backends, batches incoming user requests, and provides GPU utilization metrics to the scheduler. This supports scaling up or down the number of deployments and GPUs based on the amount of the inference requests.
For a detailed guide on how to deploy NVIDIA Triton with Kubernetes, see Scaling LLMs with NVIDIA Triton and NVIDIA TensorRT-LLM Using Kubernetes.
Meeting strict service-level agreements
To define the right SLAs for the company’s diverse use cases, Perplexity’s inference team conducts comprehensive A/B testing, evaluating different configurations and their impact on user experience. Their goal is to maximize GPU utilization while consistently meeting the target SLA for each specific use case. By improving batching while meeting target SLAs, inference serving cost is optimized.
For smaller models, such as embedding models under 1 billion parameters used in real-time retrieval, the focus is on achieving the lowest possible latency. These are typically hidden from the user and are part of a broader workflow. As a result, configurations for these queries typically have low batch sizes. Given the smaller memory footprints of these models, the team runs multiple models concurrently on the NVIDIA H100 GPU to maintain high resource utilization.
For user-facing models such as Llama 8B, 70B, and 405B, which have a greater impact on user experience and deployment costs, the team conducts a deeper performance analysis and evaluates key metrics such as time to first token, tokens per second per user, and cost per million queries.
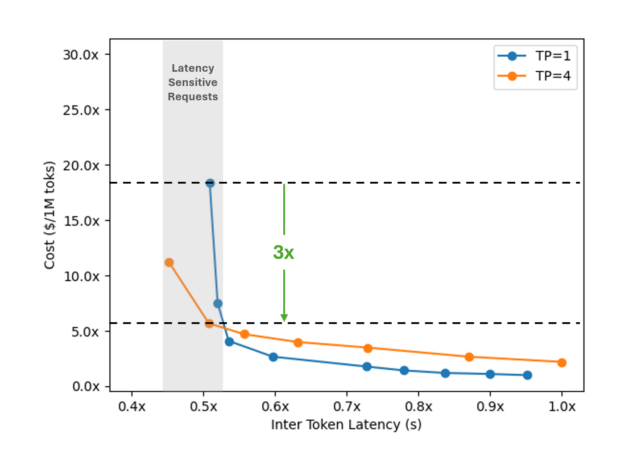
To optimize performance while controlling costs, Perplexity parallelizes their deployment of these models across multiple GPUs. Due to the strict SLAs, the team opted to increase tensor parallelism to four and eight GPUs, which they found yields lower serving costs for very latency-sensitive requests within a fixed GPU budget. Data or pipeline parallelism was useful for maximizing throughput in less latency-sensitive settings.
The Perplexity team now uses TensorRT-LLM in combination with proprietary LLM runtimes built with optimized CUDA kernels to successfully serve the Llama-based models within their strict SLAs at minimal costs.
Ultimately, the Perplexity inference team’s decision to host models depends on their ability to serve these models at a lower cost while still meeting their strict SLAs, compared to using third-party LLM provider APIs. For example, the team estimated that they were able to save approximately $1 million annually by serving models that power their Related-Questions feature on cloud-hosted NVIDIA GPUs. The Related-Questions feature offers Perplexity users suggested follow-up questions to facilitate deeper dives after a search query.
Delivering new levels of performance
The inference team at Perplexity adopts a comprehensive, full-stack approach to their road map, consistently optimizing and enhancing every layer of the stack—from applications and use cases to inference serving middleware and hardware accelerators.
In terms of inference serving middleware, the team is actively collaborating with the NVIDIA Triton engineering team to deploy disaggregating serving, a groundbreaking technique that separates the prefill and decode inference phases of an LLM workflow onto separate NVIDIA GPUs. This technique significantly boosts overall system throughput while meeting SLAs, translating to lower cost per token. Additionally, this technique gives Perplexity the flexibility to use different NVIDIA GPU products for each inference phase given its specific hardware resource requirements.
The Perplexity team understands that optimizing the software stack can only drive performance improvements to a certain extent. To deliver new levels of performance, hardware innovations are crucial. This is why they are eager to assess the NVIDIA Blackwell platform.
NVIDIA Blackwell delivers significant performance leaps enabled by numerous technology innovations, including the second-generation Transformer Engine with support for the FP4 data format, fifth-generation NVLink and NVSwitch enabling significantly larger NVLink domains, and more. Collectively these innovations deliver 30x improvement in inference performance for trillion parameter LLMs.
Get started
NVIDIA Triton Inference Server and NVIDIA TensorRT are open-source projects available on GitHub. They are also available as Docker containers that can be pulled from NVIDIA NGC. They are part of NVIDIA AI Enterprise, which offers enterprise-grade security, stability, and support. Enterprises seeking the fastest time to value can use NVIDIA NIM, a set of easy-to-use microservices for accelerated inference on a wide range of AI models, including open-source community and NVIDIA AI Foundation models.
To learn more, check out these resources:
