When building a large language model (LLM) agent application, there are four key components you need: an agent core, a memory module, agent tools, and a planning module. Whether you are designing a question-answering agent, multi-modal agent, or swarm of agents, you can consider many implementation frameworks—from open-source to production-ready. For more information, see Introduction to LLM Agents.
For those experimenting with developing an LLM agent for the first time, this post provides the following:
- An overview of the developer ecosystem, including available frameworks and recommended readings to get up-to-speed on LLM agents
- A beginner-level tutorial for building your first LLM-powered agent
Developer ecosystem overview for agents
Most of you have probably read articles about LangChain or LLaMa-Index agents. Here are a few of the implementation frameworks available today:
So, which one do I recommend? The answer is, “It depends.”
Single-agent frameworks
There are several frameworks built by the community to further the LLM application development ecosystem, offering you an easy path to develop agents. Some examples of popular frameworks include LangChain, LlamaIndex, and Haystack. These frameworks provide a generic agent class, connectors, and features for memory modules, access to third-party tools, as well as data retrieval and ingestion mechanisms.
A choice of which framework to choose largely comes down to the specifics of your pipeline and your requirements. In cases where you must build complex agents that have a directed acyclic graph (DAG), like logical flow, or which have unique properties, these frameworks offer a good reference point for prompts and general architecture for your own custom implementation.
Multi-agent frameworks
You might ask, “What’s different in a multi-agent framework?” The short answer is a “world” class. To manage multiple agents, you must architect the world, or rather the environment in which they interact with each other, the user, and the tools in the environment.
The challenge here is that for every application, the world will be different. What you need is a toolkit custom-made to build simulation environments and one that can manage world states and has generic classes for agents. You also need a communication protocol established for managing traffic amongst the agents. The choice of OSS frameworks depends on the type of application that you are building and the level of customization required.
Recommended reading list for building agents
There are plenty of resources and materials that you can use to stimulate your thinking around what is possible with agents, but the following resources are an excellent starting point to cover the overall ethos of agents:
- AutoGPT: This GitHub project was one of the first true agents that was built to showcase the capabilities that agents can provide. Looking at the general architecture and the prompting techniques used in the project can be quite helpful.
- Voyager: This project from NVIDIA Research touches upon the concept of self-improving agents that learn to use new tools or build tools without any external intervention.
- OlaGPT: Conceptual frameworks for agents, like OlaGPT, are a great starting point to stimulate ideas on how to go beyond simple agents, which have the basic four modules.
- MRKL Systems: A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning: This paper first suggested the core mechanism for using tools with language models to execute complex tasks.
- Generative Agents: Interactive Simulacra of Human Behavior: This was one of the first projects to build a true swarm of agents: a solution made up of multiple agents interacting with each other in a decentralized manner.
If you are looking for more reading material, I find the Awesome LLM-Powered Agent list to be useful. If you have specific queries, drop a comment on this post.
Tutorial: Build a question-answering agent
For this tutorial, you build a question-answering (QA) agent that can help you talk to your data.
To show that a fairly simple agent can tackle fairly hard challenges, you build an agent that can mine information from earnings calls. You can view the earnings call transcripts. Figure 1 shows the general structure of the earnings call so that you can understand the files used for this tutorial.

By the end of this post, the agent you build will answer complex and layered questions like the following:
- How much did revenue grow between Q1 of 2024 and Q2 of 2024?
- What were the key takeaways from Q2 of FY24?
As described in part 1 of this series, there are four agent components:
- Tools
- Planning module
- Memory
- Agent core
Tools
To build an LLM agent, you need the following tools:
- Retrieval-augmented generation (RAG) pipeline: You can’t solve the talk-to-your-data problem without RAG. So, one of the tools that you need is a RAG pipeline. For more information about how to build a production-grade RAG pipeline, refer to the GitHub repo.
- Mathematical tool: You also require a mathematical tool for performing any type of analysis. To keep it simple for this post, I use an LLM to answer math questions, but tools like WolframAlpha are the ones that I recommend for production applications.
Planning module
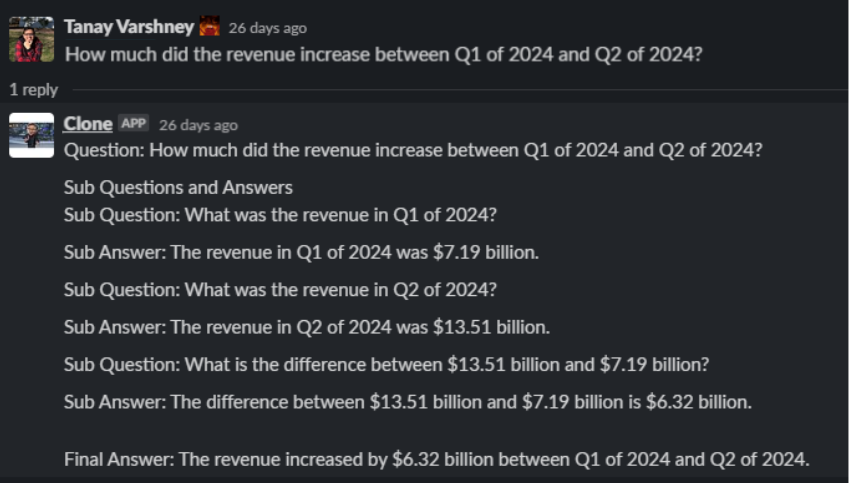
With this LLM agent, you will be able to answer questions such as: “How much did the revenue grow between Q1 of 2024 and Q2 of 2024?” Fundamentally, these are three questions rolled into one:
- What was the revenue in Q1?
- What was the revenue in Q2?
- And, what’s the difference between the two?
The answer is that you must build a question decomposition module:
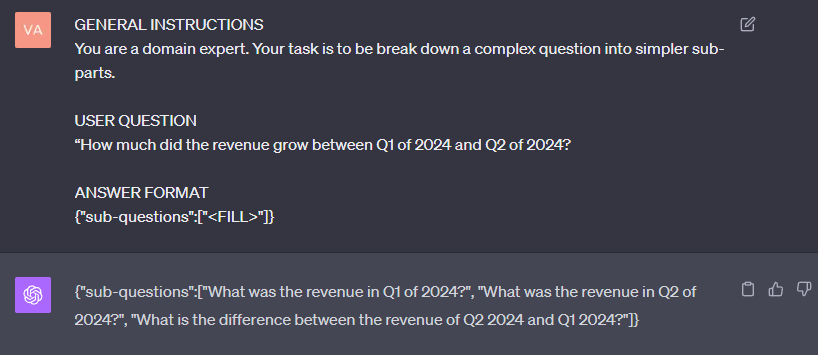
decomp_template = """GENERAL INSTRUCTIONS
You are a domain expert. Your task is to break down a complex question into simpler sub-parts.
USER QUESTION
{{user_question}}
ANSWER FORMAT
{"sub-questions":["<FILL>"]}""
As you can see, the decomposition module is prompting the LLM to break the question down into less complex parts. Figure 3 shows what an answer looks like.
Memory
Next, you must build a memory module to keep track of all the questions being asked or just to keep a list of all the sub-questions and the answers for said questions.
class Ledger:
def __init__(self):
self.question_trace = []
self.answer_trace = []
You do this with a simple ledger made up of two lists: one to keep track of all the questions and one to keep track of all the answers. This helps the agent remember the questions it has answered and has yet to answer.
Evaluate the mental model
Before you build an agent core, evaluate what you have right now:
- Tools to search and do mathematical calculations
- A planner to break down the question
- A memory module to keep track of questions asked.
At this point, you can tie these together to see if it works as a mental model (Figure 4).
template = """GENERAL INSTRUCTIONS
Your task is to answer questions. If you cannot answer the question, request a helper or use a tool. Fill with Nil where no tool or helper is required.
AVAILABLE TOOLS
- Search Tool
- Math Tool
AVAILABLE HELPERS
- Decomposition: Breaks Complex Questions down into simpler subparts
CONTEXTUAL INFORMATION
<No previous questions asked>
QUESTION
How much did the revenue grow between Q1 of 2024 and Q2 of 2024?
ANSWER FORMAT
{"Tool_Request": "<Fill>", "Helper_Request "<Fill>"}"""
Figure 4 shows the answer received for the LLM.
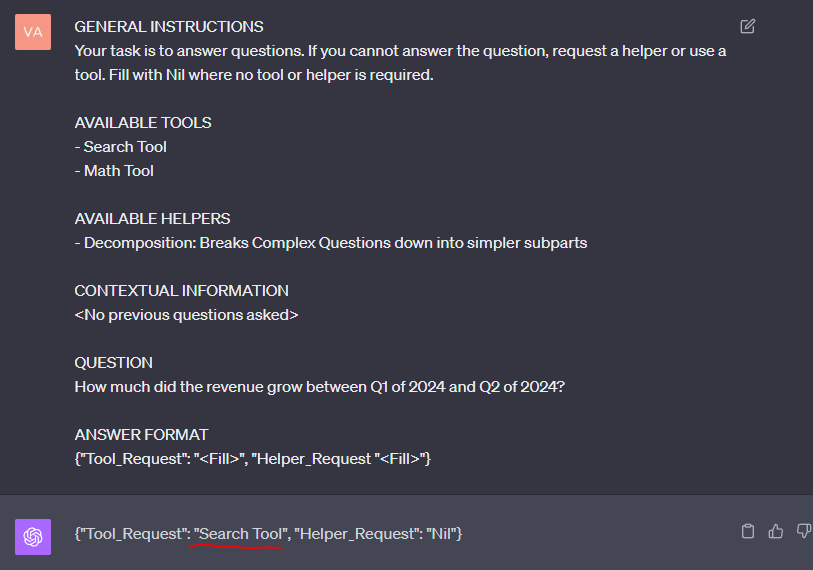
You can see that the LLM requested the use of a search tool, which is a logical step as the answer may well be in the corpus. That said, you know that none of the transcripts contain the answer. In the next step (Figure 5), you provide the input from the RAG pipeline that the answer wasn’t available, so the agent then decides to decompose the question into simpler sub-parts.
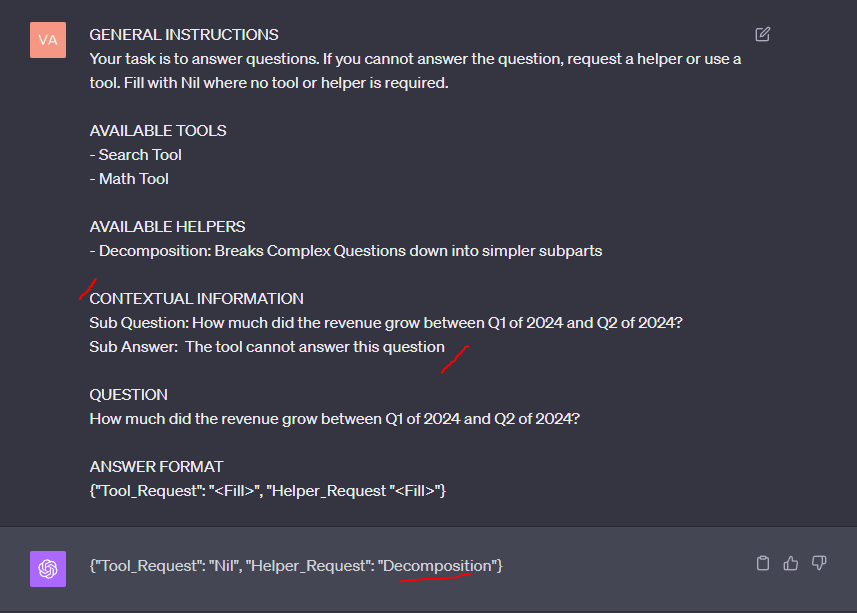
With this exercise, you validated that the core mechanism of logic is sound. The LLM is selecting tools and helpers as and when required.
Now, all that is left is to neatly wrap this in a Python function, which would look something like the following code example:
def agent_core(question):
answer_dict = prompt_core_llm(question, memory)
update_memory()
if answer_dict[tools]:
execute_tool()
update_memory()
if answer_dict[planner]:
questions = execute_planner()
update_memory()
if no_new_questions and no tool request:
return generate_final_answer(memory)
Agent core
You just saw the example of an agent core, so what’s left? Well, there is a bit more to an agent core than just stitching all the pieces together. You must define the mechanism by which the agent is supposed to execute its flow. There are essentially three major choices:
- Linear solver
- Single-thread recursive solver
- Multi-thread recursive solver
Linear solver
This is the type of execution that I discussed earlier. There is a single linear chain of solutions where the agent can use tools and do one level of planning. While this is a simple setup, true complex and nuanced questions often require layered thinking.
Single-thread recursive solver
You can also build a recursive solver that constructs a tree of questions and answers till the original question is answered. This tree is solved in a depth-first traversal. The following code example shows the logic:
def Agent_Core(Question, Context):
Action = LLM(Context + Question)
if Action == "Decomposition":
Sub Questions = LLM(Question)
Agent_Core(Sub Question, Context)
if Action == "Search Tool":
Answer = RAG_Pipeline(Question)
Context = Context + Answer
Agent_Core(Question, Context)
if Action == "Gen Final Answer”:
return LLM(Context)
if Action == "<Another Tool>":
<Execute Another Tool>
Multi-thread recursive solver
Instead of iteratively solving the tree, you can spin off parallel execution threads for each node on the tree. This method adds execution complexity but yields massive latency benefits as the LLM calls can be processed in parallel.
Summary
LLM-powered agents differ from typical chatbot applications in that they have complex reasoning skills. Made up of an agent core, memory module, set of tools, and planning module, agents can generate highly personalized answers and content in a variety of enterprise settings—from data curation to advanced e-commerce recommendation systems.
Ready for more? To build a production-grade RAG pipeline, visit NVIDIA/GenerativeAIExamples on GitHub.
To learn about other types of LLM agents, see Build an LLM-Powered API Agent for Task Execution and Build an LLM-Powered Data Agent for Data Analysis.