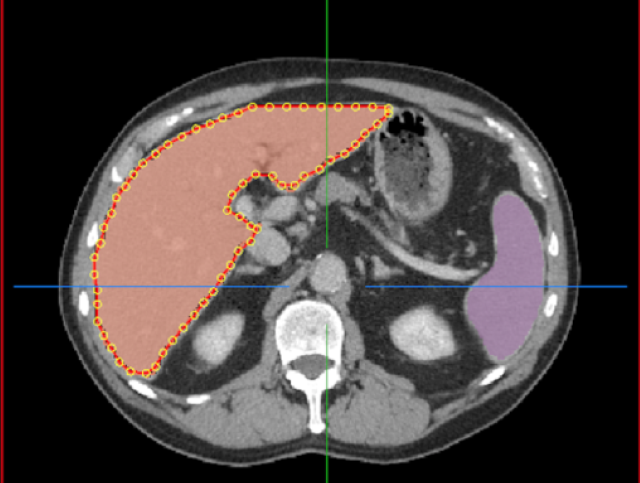
The medical imaging industry is undergoing a dramatic transformation driven by two technology trends. Artificial Intelligence and software-defined solutions are redefining the medical imaging workflow.
Deep learning research in medical imaging is booming. However, most of this research today is performed in isolation and with limited datasets. This leads to overly simplified models which only have high accuracy in narrow use cases. At the same time, smaller hospitals are deprived of the opportunity to provide higher quality of care for their local population due to a lack of technical expertise, compute resources, and the sheer data volumes required for deep learning.
Even when effective Deep Learning algorithms are created, challenges of integration and scalability in deploying these intelligent algorithms into clinical workflows slow uptake of these technologies.
The Clara AI toolkit addresses these challenges by lowering the bar to adopting AI in developing Medical Imaging workflows. The Clara Train SDK provides training capabilities, including Transfer Learning and AI assisted Annotation. These enable faster data annotation and adaptation of a neural network from a source domain to a target domain.
The Clara Deploy SDK provides the framework and tools required to define an application workflow that can be integrated and executed once a neural network is available. The latest release of Clara Train and Deploy SDKs provides tools that enable developers to create optimized AI models that easily integrate with existing hospital systems to enable end-end development and scalable, deployment of AI algorithms for medical imaging.
Understanding Clara Deploy SDK
The Clara Deploy SDK provides a robust, extensible platform for designing and deploying AI-enabled medical imaging pipelines. A Clara pipeline consists of a collection of operators configured to work together to execute a workflow. These operators accelerate modality-specific computation and can be reused across different pipelines. Figure 1 shows a block diagram of the Clara Deploy SDK.
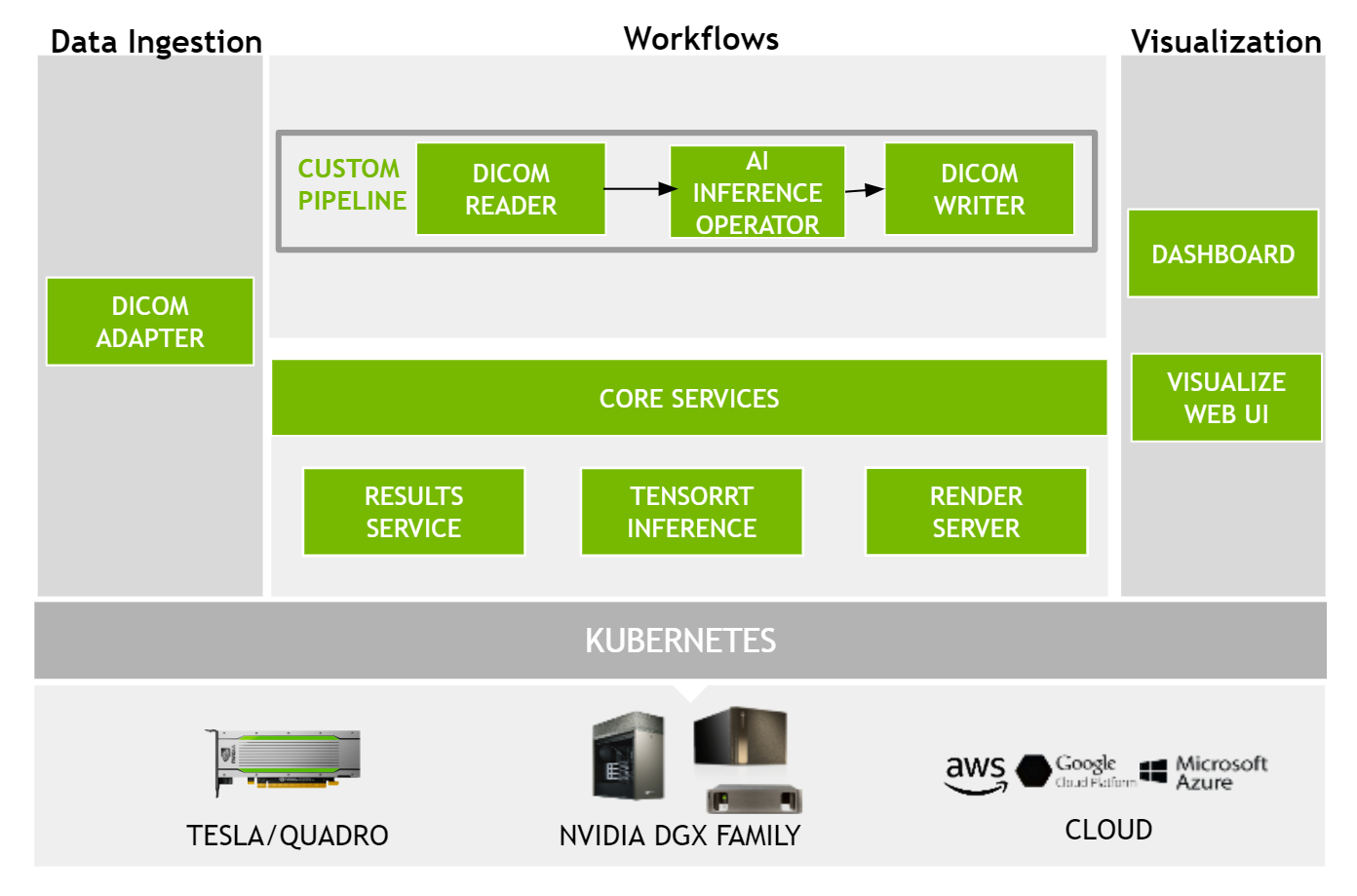
- The Clara Deploy SDK provides built-in support for the DICOM protocol so that imaging data can be seamlessly integrated with deployed pipelines.
- Developers can also build custom operators and pipelines using an intuitive Pipeline Definition Language and extend the ability of the platform using an expressive API.
- Under the hood, the framework uses industry standard container technologies to modularize operators and employs Kubernetes to orchestrate, automate, and scale deployment of AI based imaging applications.
Clara Deploy Core Concepts
Clara Deploy platform provides an engine that enables packaging individual steps in a medical imaging pipeline as containers. In addition, it provides flexible mechanisms for specifying constraints between the steps in a pipeline and artifact management for linking the output of any step as an input to subsequent steps. This ability to containerize individual steps of a pipeline plus the power of artifact management enables portability, scalability, and reusability for application developers.
Data Source
A Data Source acts as the origination point of medical imaging data used in applications developed for the Clara deploy platform. DICOM objects representing medical images and associated information make up one common type of data input used for Clara. Often, such DICOM data is organized in a picture archiving and communication system (PACS) that provides storage and convenient access to images from multiple modalities.
PACS can be set up as the primary data source for a radiology application developed using the Clara Deploy framework. For example, medical images and other related information can be transmitted from a PACS Data Source to the DICOM Adaptor component of the Clara Deploy framework using the DICOM networking protocol. In such a scenario, PACS performs the role of a Service Class User (SCU) and the Clara DICOM Adaptor acts as a Service Class Provider (SCP).
Operators
An operator is an element of the Clara Deploy Pipeline. Each operator is typically designed to perform a specific function/analysis on incoming input data. Common examples of such functions include reading images from disk, performing image processing, performing AI inference, and writing images to disk. The Clara Deploy platform comes with a bundled set of operators. A bundled operator arrives as a container which packages code and dependencies so that the operator can be executed reliably from one computing environment to another. Users can also build their own custom operators.
Pipeline
A Pipeline is a collection of operators configured to work together to execute a medical imaging workflow. Each step in such a workflow is an operator deployed as a container.
Using the Pipeline Definition Language, users can define a multi-step workflow as a sequence of tasks and capture the dependencies between tasks.
For example, a pipeline could have the following operators connected in sequence:
- DICOM Reader Operator, AI Inference Operator & DICOM Writer Operator.
- The Clara platform engine will orchestrate feeding of requisite data to a specific operator in the pipeline during the execution of such a pipeline.
- Incoming DICOM images from a registered Data Source will be made available to the DICOM Reader operator in this specific example.
- When the DICOM reader operator finishes its execution, its output from the reader operator feeds into the AI Inference Operator.
- Similarly, output from the AI Inference Operator will be provided to the DICOM Writer Operator.
- Finally the output from the Writer Operator can be pushed to a PACS DICOM Storage service.
Service
A Service is an abstraction which defines a mechanism to access a computational facility available in the Clara Deploy framework. An example of a service in the Clara Deploy framework is the TensorRT inference service used for managed AI models. Operators defined in a Clara pipeline could make use of one or more services at run-time.
New Features & Capabilities
The Clara Deploy SDK has incorporated significant architectural changes to enable data scientists and application developers with a robust, easy to use, scalable foundation for deployment of AI workfload for Medical Imaging. The features include:
Clara Core Services
- DICOM Adapter. Clara Deploy SDK provides a built-in DICOM Adapter service. This service acts as a bridge between sources of medical images in the hospital enterprise and pipelines designed to be executed on the Clara Deploy platform. It enables easy integration of imaging modalities with the Clara deploy platform. Users can configure a modality (such as CT, MR or PACS) to send medical images to the Clara DICOM adapter using the industry standard DICOM protocol. Based on the configuration, upon receiving such images, the Clara Deploy platform in turn triggers a specific pipeline. Once a pipeline completes its execution, the output (often another set of DICOM images) can be sent back to a hospital information system via the same Clara DICOM Adapter.
- Results Service. After registering a pipeline with Clara, payloads such as medical images from external data sources (e.g. CT modality) can be sent to trigger a job. As a result of the job execution, the pipeline produces output data such as segmentation masks). Clara Deploy provides a service that tracks results generated by all pipelines and maintains the linkage between a pipeline, its corresponding jobs, and all input/output data related to the jobs. This enables streamlined transmission of pipeline output to hospital information systems or to Clara’s built in visualization server for further processing.
- Tensor RT Inference Server. Clara Deploy provides a containerized TensorRT Inference Server to facilitate powerful inferencing for AI models. The inference service can be invoked via an HTTP or gRPC endpoint, allowing a Clara operator to request inferencing for any model managed by the server. A Clara operator can make use of features such as multi-GPU support, concurrent model execution, managed model repository out of the box via the TensorRT Inference Server, without the need for any custom work.
- Render Server. Render Server of the Clara Deploy platform provides a zero-footprint, browser based 3D visualization of medical imaging data. Using the render server, developers can visualize and interact with both the input data (such as cross-sectional MR images) as well as output from a pipeline execution (such as segmented body parts) in full-fidelity 3D.
- Clara I/O Model. The Clara I/O model is designed to follow standards that can be executed and scaled by Kubernetes. Payloads and results are separated to preserve payloads for restarting when unsuccessful or interrupted for priority, and to allow the inputs to be reused in multiple pipelines.
Pipeline Definition Language
Users of Clara Deploy SDK can define new pipelines to handle processing demands of a medical imaging workflow via the pipeline definition language. The key features of this language include:
- Operators. Parts of a pipeline definition which “do something”. At the heart of any operator declaration is its container declaration, specifically the image it declares. The image property defines the name of the container image Clara will fetch, deploy, and execute as part of the pipeline execution.
- Pipelines. Defined as a series of operators, or execution stages. Operators are defined as a container and a set of services the operator can invoke.
- Services. Invoked by operators in cases when operators need access to resources which are too expensive, complex, or restricted to run as a short lived container execution stage. A good example of a pipeline service is NVIDIA TensorRT Inference Server, aka TRTIS, which provides client-server inference services over network connections.
- Connections. Define the methods by which an operator can communicate with a service. Clara Deploy SDK supports HTTP/network and volume mounted connections.
- Services. Define a long running container application which can support multiple operators in parallel. Clara Deploy SDK will ensure that any service declared as required by a pipeline’s operator(s) is running before starting the execution of any of a pipeline’s operator(s).
Besides these, the Pipeline definition language exposes other properties & objects to provide users with an interface to query and define custom pipelines.
Clara API
Users can make of the powerful Clara Deploy API to develop extensions for the Clara Deploy framework . Examples include custom integration with hospital enterprise systems, custom visualization of pipelines, and performing payload related operations. The API is based on Google’s GRPC standard which is both platform and language agnostic. This means anyone can develop clients for Clara Deploy SDK using the language of their choice and on the platform of their choice.
Defining a Custom Pipeline
Let’s look at the steps for defining a custom pipeline.
Build Custom Operators
An operator is an element of the Clara Deploy Pipeline. If you are building a custom pipeline, you may have already built a custom Clara operator. If not, please refer to the section “Base Inference Application” to get information on how to build a Docker image to encapsulate your custom operator.
Configure the Model Directory
Once you have built a custom operator and you have one or more trained AI models, you are ready to use them in the context of a pipeline. However, in order for your models to be utilized during execution time, you need to place them in a known location so that the TensorRT Inference server can load them up. Copy all your AI models to the directory /clara/common/models/
Define Reference Pipeline
Clara provides a simple Pipeline Definition Language, using which you can define a multi-step pipeline as a sequence of operators and capture the dependencies among these operators.
Publish the Pipeline
Publishing a pipeline registers it with the platform. Once a pipeline is registered, it is represented with an ID. Refer to the section on Clara CLI in the User’s Guide to learn how to register a pipeline.
Configure External DICOM Sender and DICOM Receiver
After a pipeline is registered, the platform processes the data according to the pipeline definition whenever an appropriate payload (e.g, a set of DICOM images for example) is sent to the Clara platform. At this point of the workflow, you need to integrate your DICOM data source and DICOM destination with Clara.
To make it easier, Clara provides a built-in DICOM Adapter that can work as both receiver and sender of network DICOM images. You need an external DICOM Service Class User (SCU) application to send images to the Clara DICOM Adapter. Often an external PACS or an imaging modality acts as the DICOM sender in a medical imaging workflow. Similarly when your pipeline finishes executing, you may want to send the output to an external DICOM receiver. During test run of your pipeline execution, you may want to first test your pipeline setup and execution before integrating with a production PACS or a production imaging modality. In such a scenario, please consider using an open-source DICOM toolkit such as ‘dcmtk’ as an external DICOM sender and DICOM receiver to verify your end-to-end setup.
Configure the Clara DICOM Destination
When you send DICOM images from an external data source (for example a PACS) to Clara, a specific Application Entity (AE) configured in the Clara DICOM Adapter receives the images.
- An AE is the name used in DICOM standard to represent a program running on a system which is the end-point of DICOM communications.
- Each Application Entity has an Application Entity Title (AET) which only needs to be locally unique.
- To enable triggering your pipeline, you need to associate the ID of your pipeline with a specific AE title in the configuration file of the Clara DICOM Adapter. Please refer to the chapter on “Running Custom Pipeline” in the User’s Guide to learn how to do it.
Trigger Pipeline
Now you are ready to trigger the pipeline. A pipeline triggers when a DICOM series is sent to the specific AE title of the Clara DICOM Adapter associated with that pipeline. You need to either configure your PACS or the imaging modality to act as a Service Class User (SCU) enabled to send images to the specific AE title of the Clara DICOM Adapter configured in the last step.
View details of the Pipeline Execution in the Dashboard
Once a pipeline triggers, you can visualize it in action using the Clara dashboard. It provides a visual representation of each operator in the pipeline, the status of execution and information such as time taken by the operator for process completion.
Verify the output from your pipeline
The render server component of the Clara platform provides a browser-based, zero-footprint, high fidelity 3D volume rendering of both input images and output data (for example segmented structures) resulting from execution of your pipelines.
Obtaining the Clara Deploy SDK
You can download the SDK here We would like to hear your feedback and to engage on the latest developments please join the Clara Deploy SDK Forum.