
As enterprise adoption of agentic AI accelerates, teams face a growing challenge of scaling intelligent applications while managing inference costs. Large language models (LLMs) offer strong performance but come with substantial computational demands, often resulting in high latency and costs.
At the same time, many development workflows—such as evaluation, data curation, and fine-tuning—remain largely manual. These processes are time consuming, difficult to automate, and don’t scale effectively.
Adding to the complexity, AI agents increasingly rely on multiple specialized models for tasks like reasoning, tool routing, and summarization. Each of these components has distinct performance characteristics and optimization requirements—making it difficult to evaluate and tune them individually at scale.
To address this, NVIDIA is introducing the NVIDIA AI Blueprint for building data flywheels, a reference architecture built on the NVIDIA NeMo microservices. This blueprint enables teams to continuously distill LLMs into smaller, cheaper, and faster models without compromising accuracy, using real-world production traffic from the AI agent interactions. It automates the execution of structured experiments that explore the space of available models, surfacing promising efficient candidates for production promotion or deeper manual evaluation.
This blog unpacks the Data Flywheel Blueprint—how it works, how to apply it to a real-world use case around agentic tool calling, and how to easily configure it to build data flywheels for your own agentic AI workflows. This demo notebook puts the flywheel in action on a pre-curated customer service agent dataset.

How does it work?
This version of the blueprint is designed to help teams replicate the capabilities of large foundational models (e.g., 70B parameters) with smaller, more efficient alternatives. By continuously benchmarking existing and newly released models against production tasks, fine-tuning promising candidates, and surfacing top performing smaller models, the system enables teams to reduce latency and inference costs without compromising model accuracy.
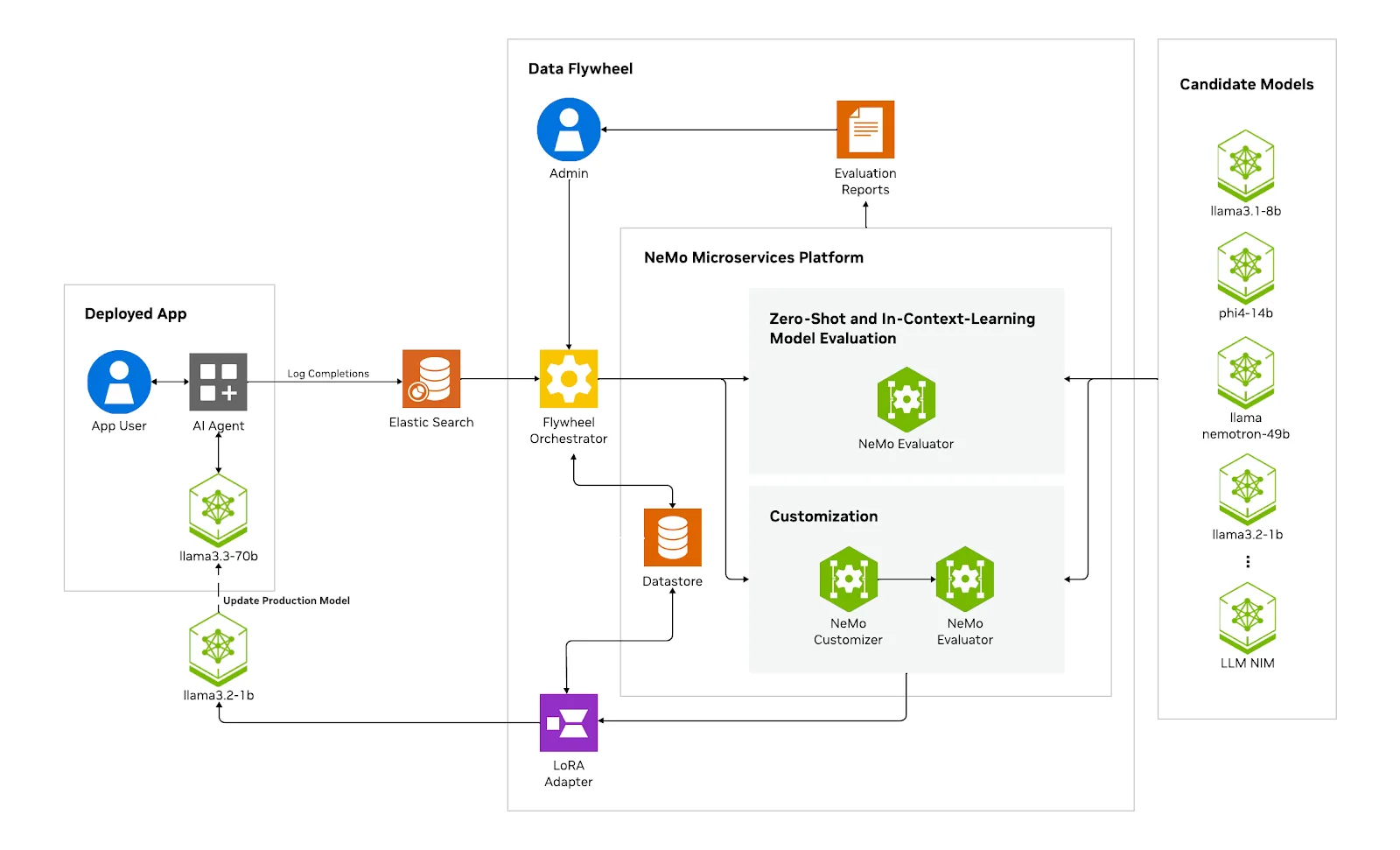
At the heart of the Data Flywheel Blueprint is the Flywheel Orchestrator Service, a unified control plane that abstracts the complexity of interacting directly with NeMo microservices. Acting as the brain of the flywheel system, the Orchestrator API coordinates the data flywheel job by leveraging a suite of modular NeMo microservices:
- NVIDIA NeMo Customizer to handle lightweight LoRA-based fine-tuning
- NVIDIA NeMo Evaluator to automate evaluations using LLM-as-a-judge scoring
- NeMo Datastore to manage structured datasets and artifacts
- NeMo Deployment Manager to spin up and serve candidate models (NIMs) dynamically for inference
Here’s how the flywheel works, step by step:
Step 1: Log ingestion
Production prompt/response logs from the teacher base-NIM (e.g., a large 70B model) are ingested into an Elasticsearch index. These logs follow the OpenAI-compliant format.
Step 2: Tagging for partitioning
Each log is tagged with metadata like workload_id, enabling the system to isolate and process data by task for each agent node.
Step 3: Dataset creation
The orchestrator de-duplicates the logs and transforms them into task-aligned datasets for training and evaluation. Notably, these datasets do not rely on any external ground-truth labels—only on the original model’s responses—which eliminates the need for manual labeling. These datasets are stored in the NeMo Datastore.
Step 4: Fine-tuning jobs
Using the NeMo Customizer, supervised fine-tuning jobs are launched with LoRA adapters. Each job distills the knowledge from the larger teacher model stored in the NeMo Datastore into smaller task-specific candidates without requiring handcrafted datasets.
Step 5: Evaluate runs
The NeMo Evaluator benchmarks multiple candidate NIM models using three evaluation methods:
base-eval: Zero-shot baseline on raw logsicl-eval: Few-shot context-based evaluationcustomized-eval: Evaluation post fine-tuning pipelines
Step 6: Scoring and aggregation
Model outputs are scored using the NeMo Evaluator, including LLM-as-a-judge, and results are reported back through the Orchestrator API.
Step 7: Review and promotion
Developers and admins can programmatically access metrics, download artifacts, launch follow-up experiments, or promote top-performing candidates to production to replace the larger NIM.
This entire loop can be scheduled or triggered on-demand, creating an automated, scalable system that continuously and progressively surfaces smaller, faster, and more cost-efficient models—while preserving the accuracy of the larger baseline model.
Adopting the Data Flywheel Blueprint for agentic tool-calling
To demonstrate the value and use of the Data Flywheel Blueprint, we applied it to a high-impact use case: Agentic Tool Calling. This is particularly relevant for production AI agents that must interface reliably with external systems via structured API calls.
We built upon the NVIDIA AI Blueprint for AI virtual assistants, a multi-tool agent designed for customer support tasks like product Q&A, order tracking, returns, and casual conversation. Initially, this agent was powered by a large Llama-3.3-70B-instruct model that performed tool-calling with high accuracy. We wanted to tune a smaller model to match the accuracy of the larger one while reducing costs. In production, this would be driven by real customer interactions to continuously improve tool-calling performance.
To simulate production traffic, we synthetically generated natural language queries and captured the agent’s tool-calling behavior in OpenAI-compatible request-response logs. These logs became the basis for both training and evaluation datasets.
Using this setup, we ran three optimization experiments with the Data Flywheel Blueprint to assess the tool-calling performance of smaller candidate models:
- Zero-shot prompting (
`base-eval`): The models (including the larger base NIM) were evaluated on production-like prompts without any prior examples or customization. This serves as a gold standard, capturing the original behavior of the large model and providing a reference point against which smaller models are benchmarked. - In-context learning (
`icl-eval`): Few-shot examples were prepended to each prompt. These examples came from actual production traffic and were automatically sampled and formatted by the flywheel based on the ICL configuration (config.yaml) that comes with the blueprint. This approach tests how much a model can improve just by contextual prompting. - Supervised fine-tuning with LoRA (
`customized-eval`): Using the`training_config`and`lora_config` sections, we fine-tuned models with LoRA adapters, training on curated task-specific datasets derived from production logs. Those models were then evaluated to measure gains overbase-evalandicl-eval.
The NeMo Evaluator, using LLM-as-judge capabilities, automatically scored all model outputs without requiring human labels. Each run provided structured metrics like `function_name_and_args_accuracy` and `tool_calling_correctness`, which were logged and surfaced through the Orchestrator API for review and comparison. This whole process has been completely automated so developers can programmatically access evaluation reports to promote top-performing candidates to replace the original NIM.
The outcome: A fine-tuned Llama-3.2-1B model using SFT-LoRA achieved 98% of the tool-calling accuracy of the original 70B model. This was enabled by automated, repeated cycles of fine-tuning and evaluation, as more traffic data flowed through the blueprint.
The result is a dramatically lighter model that retains accuracy while offering substantial improvements in latency and cost. Notably, the optimized Llama-3.2-1B model requires only one GPU to serve, compared to two GPUs needed for the original Llama-3.3-70B.
Check out this demo video on how to launch this blueprint and put these experiments in action.
Configuring and running the blueprint
To get the Data Flywheel Blueprint up and running, you’ll first need to set up your environment and deploy the required services. Detailed instructions can be found under this GitHub repo readme, but the steps broadly involve:
- Generating a personal API key to deploy NeMo microservices, access models hosted as NIM, and download model on-premises
- Deploying the NeMo microservices platform
- Installing and configuring the Data Flywheel Orchestrator
Once the environment is ready, you’ll configure your models and workflows using a config.yaml file. This file defines everything from which NIM models to deploy to configs for fine-tuning (e.g., LoRA) and evaluation (e.g., ICL, LLM-as-a-Judge).
Note: This file loads when the system starts. The settings remain static during a flywheel run. To update anything, you must stop the services, modify the YAML, and redeploy.
Below are the essential steps and configuration blocks you’ll need to review or modify to launch your flywheel job.
Model settings
Specify the NIM to be deployed and evaluated. You can set the model name, context length, GPU count, and other options like customization. See supported models available to fine-tune by the NeMo Customizer.
nims:
- model_name: "meta/llama-3.2-1b-instruct"
context_length: 32768
gpus: 1
pvc_size: 25Gi
tag: "1.8.3"
customization_enabled: true
Fine-tuning
Specify the fine-tuning parameters. These include training type, fine-tuning type, batch size, and the number of training epochs.
training_config:
training_type: "sft"
finetuning_type: "lora"
epochs: 2
batch_size: 16
learning_rate: 0.0001
lora_config:
adapter_dim: 32
adapter_dropout: 0.1
In-context learning (ICL) settings
Configure how many few-shot examples are used and their context windows when evaluating models via ICL mode.
icl_config:
max_context_length: 32768
reserved_tokens: 4096
max_examples: 3
min_examples: 1
Evaluation settings
Controls how data is split into validation and evaluation sets for each evaluation job.
data_split_config:
eval_size: 20
val_ratio: 0.1
min_total_records: 50
random_seed: null
limit: null
eval_size: Number of examples for evaluation
val_ratio: Ratio of data used for validation
Launching the flywheel job
Once configured, launch the job via a simple API call to the microservice.
# client_id: Identifier of the application or deployment that generated traffic
# workload_id: Stable identifier for the logical task / route / agent node
curl -X POST http://localhost:8000/api/jobs \
-H "Content-Type: application/json" \
-d '{"workload_id": "tool_router", "client_id": "support-app"}'
A successful submission will return tool-calling accuracy metrics that can be used to compare performance across various models.
"scores": {
"function_name_and_args_accuracy": 0.95,
"tool_calling_correctness": 1
}
Extending the blueprint to custom workflows
The blueprint is a reference workflow that can be easily customized to build data flywheels for any downstream task. NVIDIA has already seen early adoption stories among its partner ecosystem.
- Weights & Biases offers a custom version of this data flywheel blueprint on the NVIDIA API catalog augmented with tools for agent traceability and observability, model experiment tracking, evaluation, and reporting.
- Iguazio, a machine learning firm acquired by QuantumBlack, AI by McKinsey, has adapted the blueprint to build its own custom data flywheel with AI orchestration and monitoring components to power its AI platform. This is also available as a partner example on the NVIDIA API catalog.
- Amdocs has integrated this blueprint into its amAIz platform, integrating LLM fine-tuning and evaluation directly into the CI/CD pipeline. With added automation and enhancements, this enables Amdocs to continuously improve its agent’s accuracy and performance as new base models emerge—while also catching potential issues early in the development cycle.
- EY is integrating the blueprint to enhance the EY.ai Agentic Platform with real-time model optimization, which enables self-improving, cost-efficient agents across tax, risk, and finance domains.
- VAST is designing its own data flywheels for custom use cases by integrating the VAST AI Operating System with NVIDIA’s Data Flywheel Blueprint. It will enable real-time data collection, enrichment, and feedback across multimodal sources, accelerating the delivery of intelligent AI pipelines for industries such as finance, healthcare, and scientific research.
Build a data flywheel for your use case
Explore the NVIDIA AI Blueprint for data flywheels on the NVIDIA API catalog, and dive into set-up guides, implementation details, and tutorials. Follow the video tutorial for a hands-on walkthrough on building the flywheel for the agentic tool-calling use case covered in the blog.
Developers building agentic workflows with the new NVIDIA NeMo Agent toolkit can seamlessly build data flywheels around their agents using this blueprint and integrate the toolkit’s evaluation and profiling capabilities.
Join our team on June 18 for a live webinar where our experts break down how the NVIDIA NIM and NeMo microservices power data flywheels. Interact with the NVIDIA blueprint product team at our upcoming livestream Q&A session on June 26 to dive into building data flywheels with ease using this latest blueprint.
