Editor’s Note: Get notified and be the first to download our real-world blueprint once it’s available.
This is the third installment in a series describing an end-to-end blueprint for predicting customer churn. In previous installments, we’ve discussed some of the challenges of machine learning systems that don’t appear until you get to production: In the first installment, we introduced our use case and described an accelerated data federation pipeline; in the second installment, we showed how advanced analytics fits with the rest of the machine learning lifecycle.
In this third installment, we finish presenting the analytics and federation components of our application and explain some best practices for getting the most out of Apache Spark and the RAPIDS Accelerator for Apache Spark.
Architecture review
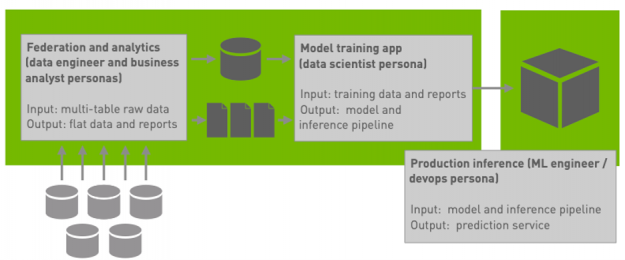
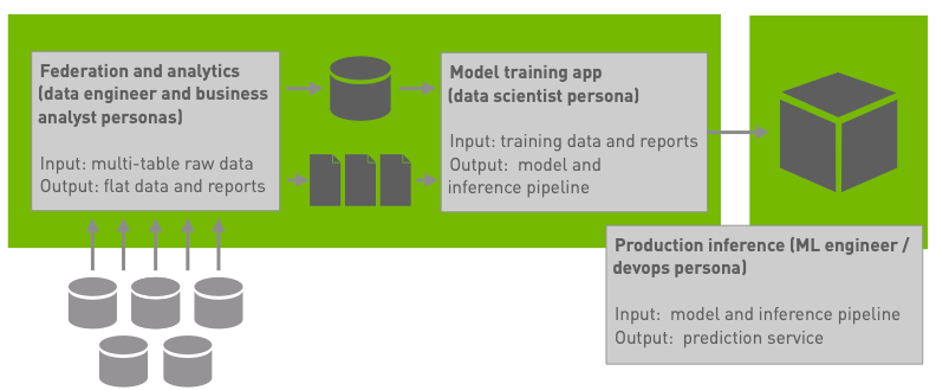
Recall that our blueprint application (Figure 1) includes a federation workload and a pair of analytics workloads.
- The federation workload produces a single denormalized wide table of data about each customer drawn from aggregating data spread across five normalized tables of observations related to different aspects of customers’ accounts.
- The first analytic workload produces a machine-readable summary report of value distributions and domains for each feature.
- The second analytic workload produces a series of illustrative business reports about customer outcomes. Our first installment contains additional details about the federation workload and our second installment contains additional details about the analytics workloads.
We’ve implemented these three workloads as a single Spark application with multiple phases:
- The app federates raw data from multiple tables in HDFS (which are stored as Parquet files) into a single wide table.
- Because the wide table is substantially smaller than the raw data, the app then reformats the wide output by coalescing to fewer partitions and casting numeric values to types that will be suitable for ML model training. The output of this phase is the source data for ML model training.
- The app then runs the analytics workloads against the coalesced and transformed wide table, first producing the machine-readable summary report and then producing a collection of rollup and data cube reports.
Performance considerations
Parallel execution
For over 50 years, one of the most important considerations for high performance in computer systems has been increasing the applicability of parallel execution. (We choose, somewhat arbitrarily, to identify the development of Tomasulo’s algorithm in 1967, which set the stage for ubiquitous superscalar processing, as the point at which concerns about parallelism became practical and not merely theoretical.) In the daily work of analysts, data scientists, data and ML engineers, and application developers, concerns about parallelism often manifest in one of a few ways; we’ll look at those now.
When scaling out, perform work on a cluster
If you’re using a scale-out framework, perform work on a cluster instead of on a single node whenever possible. In the case of Spark, this means executing code in Spark jobs on executors rather than in serial code on the driver. In general, using Spark’s API rather than host-language code in the driver will get you most of the way there, but you’ll want to ensure that the Spark APIs you’re using are actually executing in parallel on executors.
Operate on collections, not elements; on columns, not rows
A general best practice to exploit parallelism and improve performance is to use specialized libraries that perform operations on a collection at a time rather than an element at a time. In the case of Spark, this means using data frames and columnar operations rather than iterating over records in partitions of RDDs; in the case of the Python data ecosystem and RAPIDS.ai, it means using vectorized operations that operate on entire arrays and matrices in a single library call rather than using explicit looping in Python. Crucially, both of these approaches are also amenable to GPU acceleration.
Amortize the cost of I/O and data loading
I/O and data loading are expensive, so it makes sense to amortize their cost across as many parallel operations as possible. We can improve performance both by directly reducing the cost of data transfers and by doing as much as possible with data once it is loaded. In Spark, this means using columnar formats, filtering relations only once upon import from stable storage, and performing as much work as possible between I/O or shuffle operations.
Better performance through abstraction
In general, raising the level of abstraction that analysts and developers employ in apps, queries, and reports allows runtimes and frameworks to find opportunities for parallel execution that developers didn’t (or couldn’t) anticipate.
Use Spark’s data frames
As an example, there are many benefits to using data frames in Spark and primarily developing against the high-level data frame API, including faster execution, semantics-preserving optimization of queries, reduced demand on storage and I/O, and dramatically improved memory footprint relative to using RDD based code. But beyond even these benefits lies a deeper advantage: because the data frame interface is high-level and because Spark allows plug-ins to alter the behavior of the query optimizer, it is possible for the RAPIDS Accelerator for Apache Spark to replace certain data frame operations with equivalent — but substantially faster — operations running on the GPU.
Transparently accelerate Spark queries
Replacing some of the functionality of Spark’s query planner with a plug-in is a particularly compelling example of the power of abstraction: an application written years before it was possible to run Spark queries on GPUs could nevertheless take advantage of GPU acceleration by running it with Spark 3.1 and the RAPIDS Accelerator.
Maintain clear abstractions
While the potential to accelerate unmodified applications with new runtimes is a major advantage of developing against high-level abstractions, in practice, maintaining clear abstractions is rarely a higher priority for development teams than shipping working projects on time. For multiple reasons, details underlying abstractions often leak into production code; while this can introduce technical debt and have myriad engineering consequences, it can also limit the applicability of advanced runtimes to optimize programs that use abstractions cleanly.
Consider operations suitable for GPU acceleration
In order to get the most out of Spark in general, it makes sense to pay down technical debt in applications that work around Spark’s data frame abstraction (e.g., by implementing parts of queries as RDD operations). In order to make the most of advanced infrastructure, though, it often makes sense to consider details about the execution environment without breaking abstractions. To get the best possible performance from NVIDIA GPUs and the RAPIDS Accelerator for Apache Spark, start by ensuring that your code doesn’t work around abstractions, but then consider the types and operations that are more or less amenable to GPU execution so you can ensure that as much of your applications run on the GPU as possible. We’ll see some examples of these next.
Types and operations
Not every operation can be accelerated by the GPU. When in doubt, it always makes sense to run your job with spark.rapids.sql.explain set to NOT_ON_GPU and examine the explanations logged to standard output. In this section, we’ll call out a few common pitfalls, including decimal arithmetic and operations that require configuration for support.
Beware of decimal arithmetic
Decimal computer arithmetic supports precise operations up to a given precision limit, can avoid and detect overflow, and rounds numbers as humans would while performing pencil-and-paper calculations. While decimal arithmetic is an important part of many data processing systems (especially for financial data), it presents a particular challenge for analytics systems. In order to avoid overflow, the results of decimal operations must widen to include every possible result; in cases in which the result would be wider than a system-specific limit, the system must detect overflow. In the case of Spark on CPUs, this involves delegating operations to the BigDecimal class in the Java standard library and precision is limited to 38 decimal digits, or 128 bits. The RAPIDS Accelerator for Apache Spark can currently accelerate calculations on decimal values of up to 18 digits, or 64 bits.
We’ve evaluated two configurations of the churn blueprint: one using floating-point values for currency amounts (as we described in the first installment) and one using decimal values for currency amounts (which is the configuration that the performance numbers we’re currently reporting is running against). Because of its semantics and robustness, decimal arithmetic is more costly than floating-point arithmetic, but it can be accelerated by the RAPIDS Accelerator plugin as long as all of the decimal types involved fit within 64 bits.
Configure the RAPIDS Accelerator to enable more operations
The RAPIDS Accelerator is conservative about executing operations on the GPU that might exhibit poor performance or return slightly different results than their CPU-based counterparts. As a consequence, some operations that could be accelerated may not be accelerated by default, and many real-world applications will need to enable these to see the best possible performance. We saw an example of this phenomenon in our first installment, in which we had to explicitly enable floating-point aggregate operations in our Spark configuration by setting spark.rapids.sql.variableFloatAgg.enabled to true. Similarly, when we configured the workload to use decimal arithmetic, we needed to enable decimal acceleration by setting spark.rapids.sql.decimalType.enabled to true.
The plugin documentation lists operations that can be supported or not by configuration and the reasons why certain operations are enabled or disabled by default. In addition to floating-point aggregation and decimal support, there are several classes of operations that production Spark workloads are extremely likely to benefit from enabling:
- Cast operations, especially from string to date or numeric types or from floating-point types to decimal types.
- String uppercase and lowercase (e.g., “
SELECT UPPER(name) FROM EMPLOYEES“) are not supported for some Unicode characters in which changing the case also changes the character width in bytes, but many applications do not use such characters. You can enable these operations individually or enable them and several others by setting spark.rapids.sql.incompatibleOps.enabled to true. - Reading specific types from CSV files; while reading CSV files is currently enabled by default in the plugin (spark.rapids.sql.format.csv.enabled), reading invalid values of some types (numeric types, dates, and decimals in particular) will have different behavior on the GPU and the CPU and thus reading each of these will need to be enabled individually.
Accelerate data ingest from CSV files
CSV reading warrants additional attention: it is expensive and accelerating it can improve the performance of many jobs. However, because the behavior of CSV reading under the RAPIDS Accelerator may diverge from Spark’s behavior while executing on CPUs and because of the huge dynamic range of real-world CSV file quality, it is particularly important to validate the results of reading CSV files on the GPU. One quick but valuable sanity check is to ensure that reading a CSV file on the GPU returns the same number of NULL values as reading the same file on the CPU. Of course, there are many benefits to using a self-documenting structured input format like Parquet or ORC instead of CSV if possible.
Avoid unintended consequences of query optimization
The RAPIDS Accelerator transforms a physical query plan to delegate certain operators to the GPU. By the time Spark has generated a physical plan, though, it has already performed several transformations on the logical plan, which may involve reordering operations. As a consequence, an operation near the end of a query or data frame operation as it was stated by the developer or analyst may get moved from a leaf of the query plan towards the root.
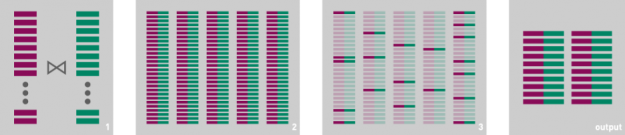
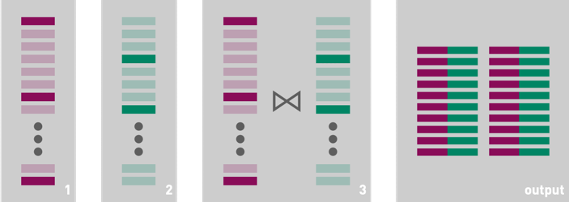
In general, this sort of transformation can improve performance. As an example, consider a query that joins two data frames and then filters the results: when possible, it will often be more efficient to execute the filter before executing the join. Doing so will reduce the cardinality of the join, eliminate comparisons that will ultimately be unnecessary, decrease memory pressure, and potentially even reduce the number of data frame partitions that need to be considered in the join. However, this sort of optimization can have counterintuitive consequences: aggressive query reordering may negatively impact performance on the GPU if the operation that is moved towards the root of the query plan is only supported on CPU or if it generates a value of a type that is not supported on the GPU. When this happens, a greater percentage of the query plan may execute on the CPU than is strictly necessary. You can often work around this problem and improve performance by dividing a query into two parts that execute separately, thus forcing CPU-only operation near the leaves of a query plan to execute only after the accelerable parts of the original query run on the GPU.
Conclusion
In this third installment, we’ve detailed some practical considerations for getting the most out of Apache Spark and the RAPIDS Accelerator for Apache Spark. Most teams will realize the greatest benefits by focusing on using Spark’s data frame abstractions cleanly. However, some applications may benefit from minor tweaks, in particular semantics-preserving code changes that consider the RAPIDS Accelerator’s execution model and avoid unsupported operations. Future installments will address the rest of the data science discovery workflow and the machine learning lifecycle.
