
Agentic workflows are the next evolution in AI-powered tools. They enable developers to chain multiple AI models together to perform complex activities, enable AI models to use tools to access additional data or automate user actions, and enable AI models to operate autonomously, analyzing and performing complex tasks with a minimum of human involvement or interaction.
Because of their power, agentic workflows also present an element of risk. The most common model at the core of agentic systems remains some variety of LLM, which remains vulnerable to prompt injection if untrusted data can be introduced into the system.
To help assess and mitigate those vulnerabilities, NVIDIA presents an Agentic Autonomy framework, which we use for the following purposes:
- Understand risks associated with increasing complexity of AI workflows
- Help model and mitigate the risks posed by such workflows
- Introduce how we use it to model threats to agentic systems

Manipulating autonomous systems
In practice, exploitation of AI-powered applications requires two key components:
- An adversary must be able to get their data (read: attack) into the system through some mechanism.
- There must be a downstream effect that their malicious data can trigger.
When the AI component of the system is an LLM, this is commonly referred to as either direct prompt injection (the adversary and user are the same person) or indirect prompt injection (the adversary and the user could be different people).
However, similar threats exist for other types of AI models used in autonomous AI powered applications. Both flavors of prompt injection are rooted in the lack of separation between the control and data plane in the LLM architecture.
Direct prompt injection can be commonly seen in such examples as “Do Anything Now” (or DAN) prompts, which attempt to subvert safety and content filters trained into the model, and enable it to produce objectionable or unwanted content. These attacks typically only impact the active user’s session, and so typically have limited impact.
Indirect prompt injection, in which a threat actor causes their data to be included in another user’s session and thus takes control of the LLM’s behavior and productions, is more serious. This is often accomplished by targeting data sources used by retrieval augmented generation (RAG) tools, including internet search, such that documents containing malicious instructions are unknowingly included in the current user’s session. When the capability to manipulate another user’s session,– particularly LLM outputs, is combined with the use of tools, a significant number of new potential risks present themselves.
When potentially untrusted data enters an agentic system, any downstream actions taken by that system become potentially adversary-controlled.
Security and complexity in AI autonomy
Even before “agentic” AI became a distinct class of product offerings, the orchestration of AI workloads in sequences was commonplace. Even simple flows, such as an endpoint security product routing a sample to the correct AI powered analysis engine depending on file format, is arguably an example of such a workflow.
Because workflows such as these are deterministic, it’s straightforward to enumerate all possible paths, map out data flows, and isolate untrusted data from potentially risky actions that might be impacted by attacker-controlled data.
As the industry moves to systems that have more internal decision making capabilities, higher degrees of tool use, and more complex interactions between model components, the number of potential data flow paths increases exponentially, making threat modeling more difficult.
The following set of classification, ordering systems from least autonomous to most, distinguishes between different degrees of autonomy afforded by different architectures, and helps assess corresponding risks.
| Autonomy level | Description | Example |
| 0 – Inference API | A single user request results in a single inference call to a single model. | An NVIDIA NIM microservice serving a single model |
| 1 – Deterministic system | A single user request triggers more than one inference request, optionally to more than one model, in a predetermined order that does not depend on either user input or inference results. | NVIDIA Generative Virtual Screening for Drug Discovery Blueprint |
| 2 – Weakly autonomous system | A single user request triggers more than one inference request. An AI model can determine if or how to call plugins or perform additional inference at fixed predetermined decision points. | Build an Enterprise RAG Pipeline Blueprint |
| 3 – Fully autonomous system | In response to a user request, the AI model can freely decide if, when, or how to call plugins or other AI models, or to revise its own plan freely, including deciding when to return control to the user. | NVIDIA Vulnerability Analysis for Container Security Blueprint, “BabyAGI”, computer use agents |
Level 1
Level 1 is a linear chain of calls, where the output of one AI call or tool response is conveyed to the next step in an entirely deterministic manner. The complete flow of data through the system is known in advance.

Level 2
In level 2, the output from the AI model may be sent along different paths through the workflow in a data-dependent manner. While every execution path can be traced, it’s not known until the workflow is executed which execution path is used.
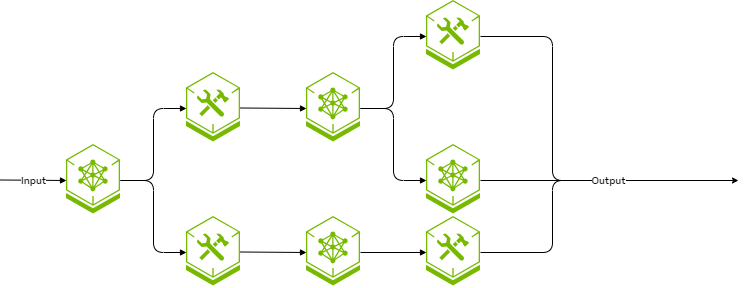
It forms a directed acyclic graph in that there is no path through the workflow that could potentially form a loop or cycle. All possible paths can be finitely enumerated. Most LLM routers fall into this level.
Level 3
For level 3, the number of potential execution paths grows exponentially with the number of execution steps in the workflow. Tools or other AI models may be invoked as the workflow progresses.
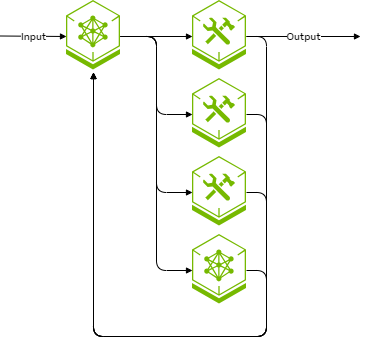
The presence of a cycle within the directed graph means that an exponentially increasing (and, at least in theory, potentially infinite) number of paths through the graph exist. It’s generally not tractable to enumerate all possible paths ahead of time, nor predict which specific path will be used for a particular input.
Separation of security boundary analysis and tool security
Our early experience with analyzing and securing agentic systems in the field led us to realize that the risk associated with these systems lies mostly in the tools or plugins available to those systems. In the absence of a tool or plugin that can perform sensitive or physical actions, the primary risk posed by manipulation of the AI component is misinformation, regardless of the degree of complexity of the workflow.
This observation drives the primary difference between this framework, which focuses on security boundaries as being distinct from tool security, and other frameworks, such as that proposed by HuggingFace in their smolagents library (Introduction to Agents). Some levels align closely. Their simple processor is approximately a deterministic system and their multi-step agent maps closely onto a fully autonomous system.
However, this framework focuses on the difficulty of identifying security boundaries given the degree of autonomy expressed by an AI component in describing program flow. HuggingFace’s description of agency, by combining the risks of tool use with the complexity of program flow, provides a quick rubric to judge systemic risks at the level of the system. This framework’s approach of separating the risks of tool calling and tool use from the difficulty of drawing security boundaries supports more detailed threat modeling of complex flows and potential mitigations.
In the proposed framework, separating the following concerns enables you to more concretely assess the risk posed by an agentic workflow:
- Security boundaries with respect to the flow of untrusted data through the system
- Security properties of specific functions or tools that may be called by the agentic system
Within a simple deterministic system with clear security boundaries, even a sensitive plugin may be a fairly low-risk if you can clearly separate it from untrusted input. In a similar manner, even a fully agentic system may be relatively low-risk as long as no sensitive tools are available to it and the output of the system is appropriately validated before use.
The combination of a more complex workflow with sensitive tools, however, demands further analysis to ensure secure operation.
Threat modeling under this framework
Increasing autonomy levels do not inherently represent increasing risk. Instead, they represent increasing lack of determinism and predictability of the system behavior, which makes it more difficult to assess the impact of untrusted data.
Risk associated with agentic systems is located largely in the tools or plugins that the system has access to which can perform sensitive actions, including the following examples:
- Completing a purchase
- Sending an email
- Physical actions such as moving a robot or setting a thermostat
Broadly speaking, anything that takes an action on behalf of a user that requires their delegated authorization to complete, or anything that results in a physical change in a system should be treated as potentially sensitive, and analyzed for its potential to act upon or be influenced by untrusted data.
Mitigation of this tool risk relies in large part on the ability to block the ability of attackers to inject malicious data into plugins, which becomes significantly more difficult with each increase in autonomy level.
Possible downstream effects are much more dependent on the details of the system and what plugins are being used, but at a minimum, a threat actor who can feed malicious data to the system must be presumed to be able to at least influence, if not control outright, the responses of the system.
If tools or plugins are being used, the potential threat increases significantly. A bad actor who can control the output of an AI model embedded in a system that uses tools might also be able to control which plugins are used and what actions those tools take. This can lead to a range of threats:
- Data exfiltration, for example, through Markdown rendering plugins
- Remote code execution, for example, through plugins that run LLM-provided code
- The risk of physical harm, if the system has control or influence over some sort of physical system
As you climb the autonomy hierarchy, you need a more careful analysis of and management of potentially untrusted data (Figures 4 and 5).
A Level 0 system, with no vectors for untrusted data, is relatively straightforward from this perspective.
A Level 1 system, with a predetermined workflow, always accesses the same data sources, models, and tools in the same sequence, making it straightforward to determine if untrusted data can be introduced into the workflow. The designer can either isolate sensitive functionality from the untrusted data, or design appropriate sanitization strategies for that data.
The number of potential execution paths in a Level 2 system is greater than in Level 1 systems but still enumerable, and specific paths that contain untrusted data can be analyzed in greater detail.
Level 3 autonomous systems pose the largest difficulty, as the number of execution paths typically grows exponentially in the number of self-reflection steps performed by the agent. In this case, these include time-of-use sanitization, time-of-use taint tracing, or other risk mitigations such as requiring manual user approval of potentially hazardous actions.
Taint tracing
Taint tracing is marking an execution flow as having received untrusted data and then either preventing use of or requiring manual re-authorization for any sensitive tool.
For Level 1 and Level 2 systems, identifying potential sources of untrustworthy data, and evaluating the risks of downstream impacts is relatively straightforward. When untrustworthy data enters the system, every downstream AI model and its associated outputs and every downstream tool and its associated actions and outputs are also untrusted.
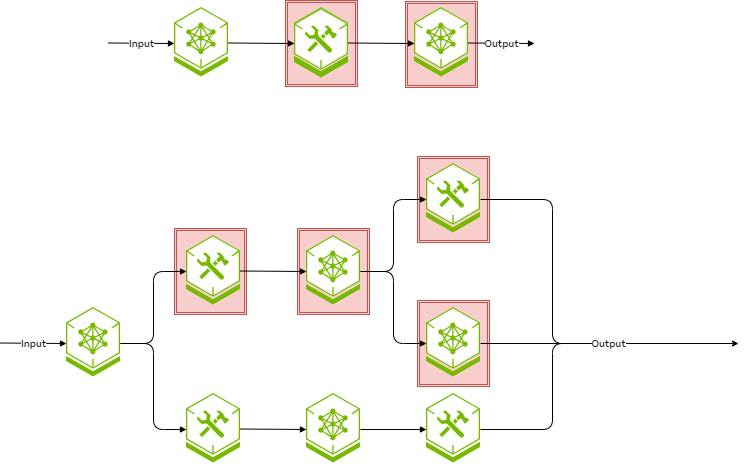
For level 3 systems, taint tracing in the general case becomes almost intractable. When untrusted data has been introduced into the workflow, it has the potential to propagate to any other downstream component through the looping structure inherent to level 3 workflows.
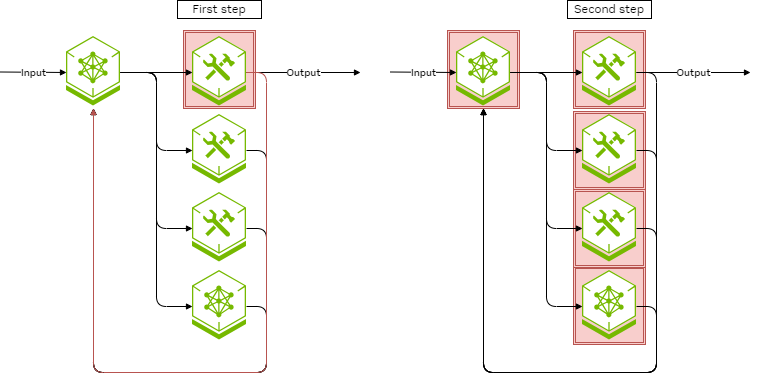
By classifying an agentic application into the correct level, it becomes simpler to identify the overall level of risk posed by the application and corresponding security requirements.
Recommended security controls per autonomy level
Table 2 provides a high-level summary of some suggested mitigating controls that should be placed around agents of various autonomy levels. Not all controls are required for all agentic workloads, depending on the sensitivity of tools provided to the workload.
| Autonomy level | Recommended security controls |
| 0 – Inference API | Use standard API security. |
| 1 – Deterministic system | Manually trace dataflows and order workflow correctly to prevent untrusted data from entering sensitive plugins. |
| 2 – Bounded agentic workflow | Enumerate dataflows, identify ones with potentially untrusted data, explore isolation or sanitization options, and consider time-of-use manual approval of sensitive actions. |
| 3 – Fully autonomous system | Implement taint tracing and mandatory sanitization of potentially untrusted data. Consider time-of-use manual approval of sensitive actions. |
For Level 0 systems, you can apply simple application and API security. Due to lack of further interaction taken by the system on the basis of AI model output, overall risk here is largely limited to non-AI components.
Level 1 and 2 systems provide a slightly elevated level of risk, but one that is straightforward to evaluate. Because these systems contain no loops, all execution flows through the systems can be exhaustively enumerated and examined for cases when untrusted data may flow into a sensitive tool.
Flows of this type are particularly risky when they pass through an LLM between the source and the sink. In level 1 systems, it’s often sufficient to reorder the workflow. For more complex (level 2) systems, risky flows from untrusted sources to sensitive sinks should be carefully evaluated to see if they can be eliminated, or otherwise if the untrusted data or input to the sensitive tool can be properly sanitized to remove risk.
Finally, if the flows cannot be rearranged or eliminated, or robust sanitization is not possible, add time-of-use manual approval to sensitive tools that may receive untrusted data, thus placing a human in the loop. This enables users of agentic workflows to inspect risky actions before they are performed and deny the workflow the ability to perform adversarially manipulated ones.
Level 3 systems, due to their complexity, typically cannot be meaningfully rearranged to block untrusted sources to sensitive sink flows. In this case, sanitization of untrusted data at time of retrieval should be implemented.
If possible, implementing taint tracing should also be considered. In the event that neither is possible, simply requiring that all potentially sensitive tools require manual approval before executing their function may be used as a last resort.
As with threat modeling, breaking agentic workloads into different complexity levels enables the quick determination of reasonable security controls to avoid the risk of having sensitive tools ingest untrusted data, including LLM outputs that have been manipulated by prompt injection.
Conclusion
As systems climb the autonomy hierarchy, they become more complex and more difficult to predict. This makes threat modeling and risk assessment more difficult, particularly in the presence of a range of data sources and tools of varying trustworthiness and sensitivity.
Identifying the system autonomy level provides a useful framework for assessing the complexity of the system, as well as the level of effort required for threat modeling and necessary security controls and mitigations.
It’s also important to analyze the plugins in the pipeline and classify them depending on their capabilities to provide an accurate risk evaluation based on the autonomy level.
