
Accelerated computing is enabling giant leaps in performance and energy efficiency compared to traditional CPU computing. Delivering these advancements requires full-stack innovation at data-center scale, spanning chips, systems, networking, software, and algorithms. Choosing the right architecture for the right workload with the best energy efficiency is critical to maximizing the performance and minimizing the carbon footprint of your data center.
Although workloads are increasingly accelerated by GPUs, many use cases continue to run primarily on traditional CPUs—particularly code that is sparse and “branchy” serialized tasks such as graph analytics. At the same time, data centers are increasingly power-constrained, limiting the growth of their capabilities. This means that all workloads that can be accelerated should run accelerated. Those that have not been accelerated should run on the most efficient CPU compute possible.
The NVIDIA Grace CPU combines 72 high-performance and power-efficient Arm Neoverse V2 cores, connected with the NVIDIA Scalable Coherency Fabric (SCF) that delivers 3.2 TB/s of bisection bandwidth—double that of traditional CPUs. This architecture keeps data flowing between CPU cores, cache, memory, and system I/O to get the most out of the system performance. Grace is the first data center CPU to utilize server-class high-speed LPDDR5X memory with a wide memory subsystem that delivers 500 GB/s of bandwidth at one-fifth the power of traditional DDR memory at a similar cost.

The NVIDIA Grace CPU powers multiple NVIDIA products. It can pair with either NVIDIA Hopper or NVIDIA Blackwell GPUs to form a new type of processor that tightly couples the CPU and GPU to supercharge generative AI, high-performance computing (HPC) and accelerated computing. In addition, the NVIDIA Grace CPU portfolio includes both the NVIDIA Grace CPU Superchip that is the heart of a dual-socket server and the Grace CPU C1 that delivers incredible performance in a single socket configuration.
The NVIDIA GH200 Grace Hopper Superchip brings together the groundbreaking performance of the NVIDIA Hopper GPU with the versatility of the NVIDIA Grace CPU in a single superchip, connected with the high-bandwidth, memory-coherent 900 GB/s NVIDIA NVLink Chip-2-Chip (C2C) interconnect that delivers 7x the bandwidth of the PCIe Gen 5. NVLink-C2C memory coherency increases developer productivity, performance, and the amount of GPU-accessible memory. CPU and GPU threads can concurrently and transparently access both CPU and GPU resident memory, enabling you to focus on algorithms instead of explicit memory management.
Over the last two decades, computer-aided engineering (CAE) has been revolutionizing product development. The ability to quickly assess the physical performance of a design virtually without having to create a physical prototype has saved time and money. The adoption of CAE has been key for many sectors, including the automotive industry where it has helped them succeed in a competitive market and has allowed them to quickly adapt to industry trends like electrification.
Computational fluid dynamics (CFD) and crash workloads are highly networking performance-driven simulations requiring maximum bandwidth, ultra-low latency, and native CPU offloads, such as RDMA, to achieve optimal server efficiency and application productivity for multinode scalability. NVIDIA Quantum InfiniBand meets these demands by providing ultrafast data speeds, minimal latency, intelligent accelerations, and superior efficiency, enabling exceptional scalability and performance.
Ansys is the leading provider of CAE tools. This post explores the performance of Ansys LS-DYNA, which is commonly used for crash analysis, and Ansys Fluent software, which is commonly used for CFD aerodynamics analysis. Ansys LS-DYNA simulation is primarily a CPU workload, so will be tested on NVIDIA Grace CPU. Ansys Fluent software benefits from a native CUDA solver, so will be run on NVIDIA Grace Hopper. These workloads are key in the automotive industry. Crash analysis often occupies over 50% of the automotive HPC workload, with CFD being the largest of the remaining workloads.
CAE revolutionizes automotive crash analysis
Ensuring a vehicle meets safety requirements without excess weight is essential to ensure a safe and energy-efficient vehicle. The industry standard tool for crash analysis is Ansys LS-DYNA software. Due to the nature of the explicit nonlinear solver required, this workload runs on CPU. Given that there are many thousands of CPU cores running crash analysis at just one OEM, there’s good potential for energy and cost savings by adopting the NVIDIA Grace CPU.
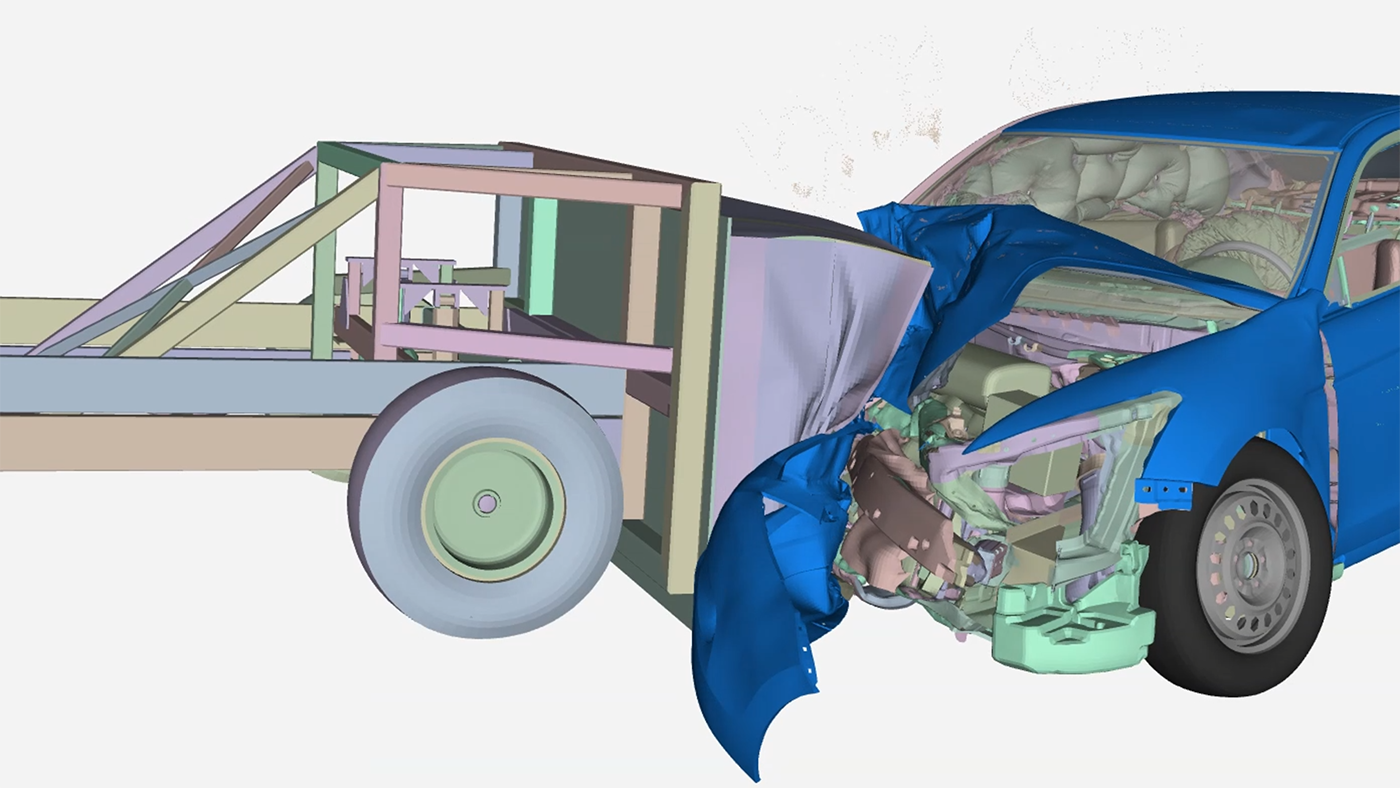
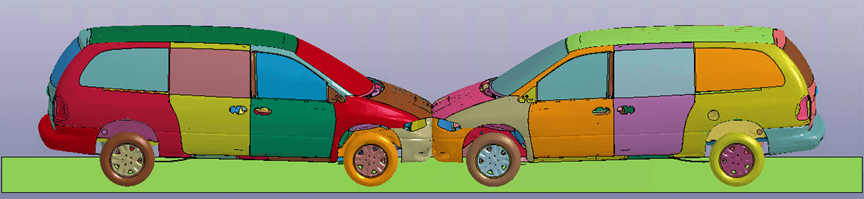
A key element in adopting any new hardware platform is having an ecosystem of software. As Grace is based on the Arm architecture, there is a rich and growing ecosystem of support. This includes many of the tools offered by Ansys, such as LS-DYNA software.
Performance of Ansys LS-DYNA on NVIDIA Grace CPU
Figure 4 shows NVIDIA Grace CPU performance compared to other currently available x86 options for both the car2car_20m and odm_10m models. The relative performance measurement is based on the CPU time to complete the case.
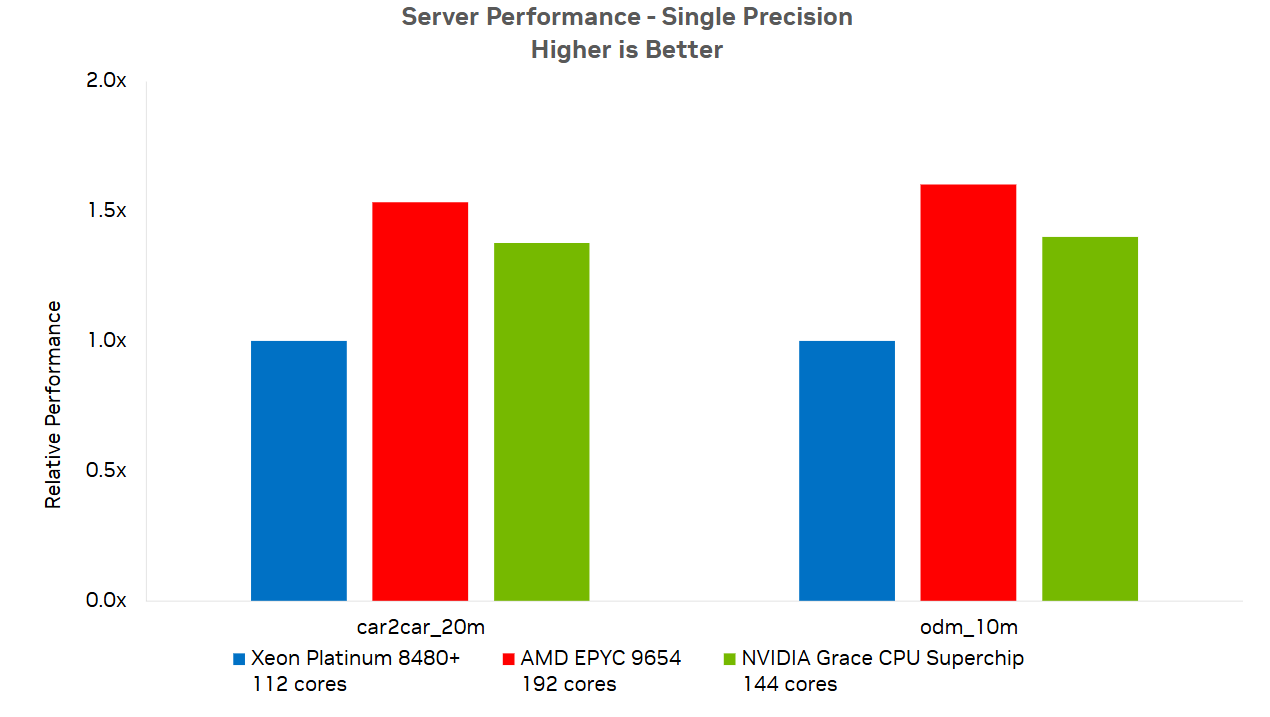
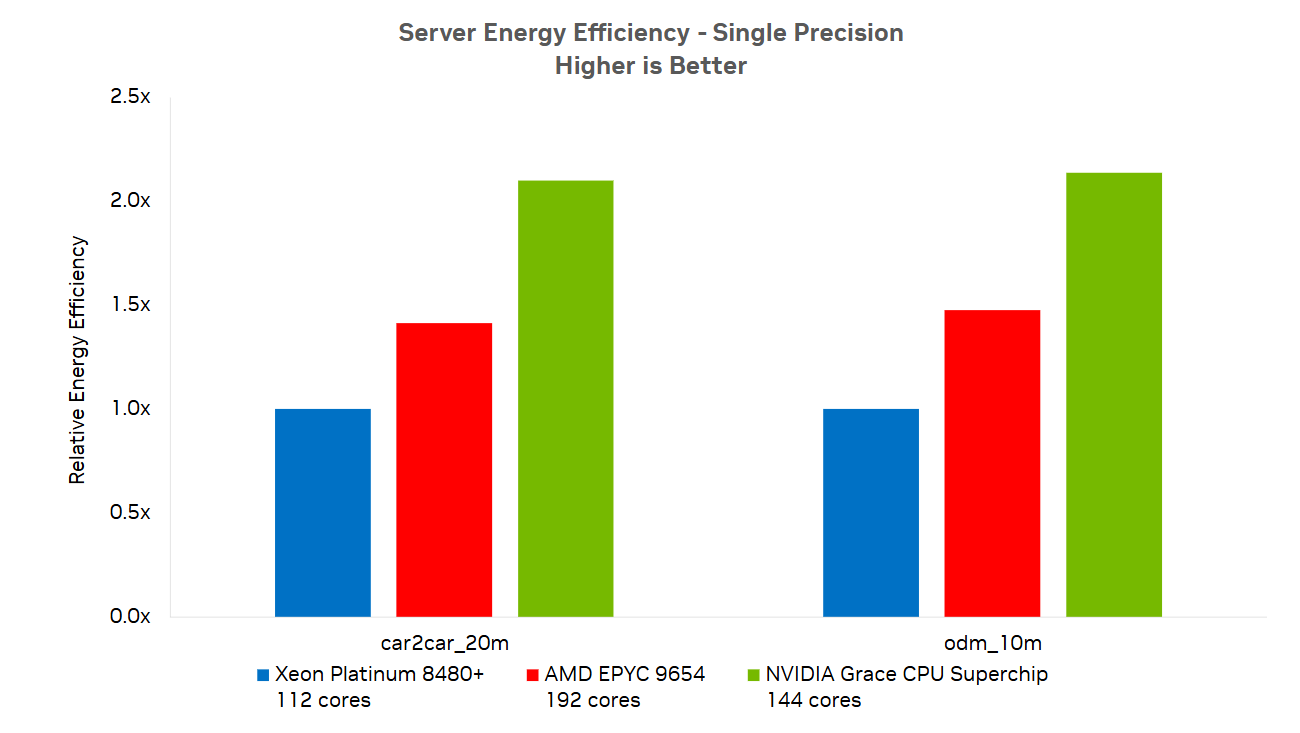
Figure 5 shows the advantage of the NVIDIA Grace Superchip in energy efficiency. Grace can run both the car2car_20m and odm_10m cases with far less power resulting in reduced cost and more sustainable compute. Many data centers are power limited, so reduced power consumption results in more compute within the same power budget.
As LS-DYNA simulations are often run across several nodes to reduce the runtime and get engineering analysis information faster, we compared a scaling of 1-8 nodes of Grace CPU versus 1-8 nodes of Intel Sapphire Rapids.
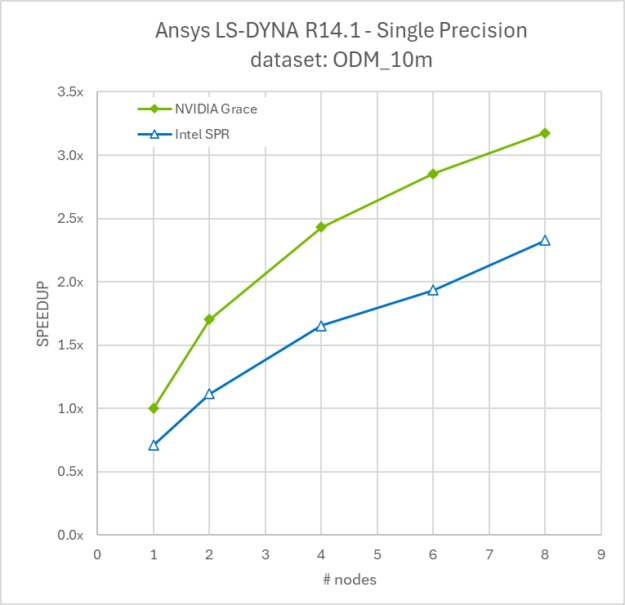
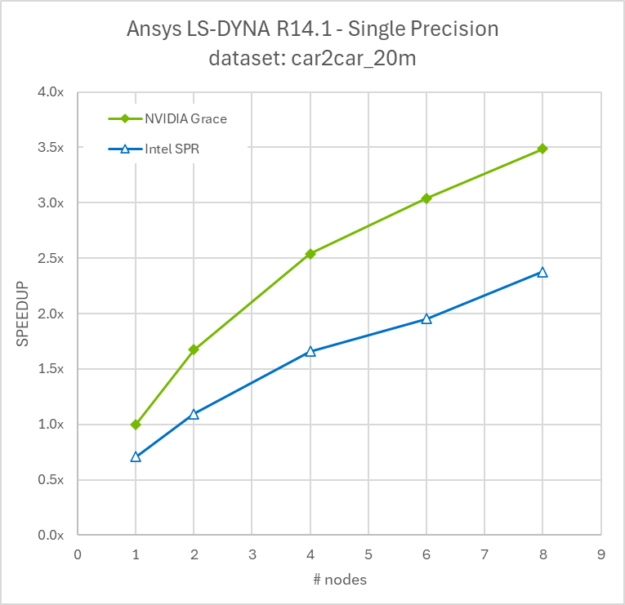
NVIDIA Grace Superchip 480GB of LPDDR5X, AMD EPYC 9654 768 GB of DDR5 and Intel Xeon Platinum 8480+ with 1TB DDR5. OS: CentOS 7.9 (Grace) Ubuntu 22..04 (x86) Compilers: LLVM 12.0.1 (Grace), Intel FORTRAN Compiler 19.0 (x86). LS-DYNA R14.1.
Energy-efficient compute for Ansys LS-DYNA simulations
The NVIDIA Grace CPU is a step forward in energy efficiency for workloads like automotive crash analysis with Ansys LS-DYNA software. Arm-based architectures, like Grace, offer a compelling balance of performance and efficiency, a trend that’s increasingly relevant for HPC, where power costs can be substantial. The benchmark results of over 2x performance/watt improvement over x86 alternatives underscore how Arm is becoming a viable HPC option. In a power-capped data center, that means that you can get up to twice the performance in the same power envelope, which expands simulation capabilities. Customers could maintain the same level of performance while freeing additional resources for acceleration. With the upcoming NVIDIA Vera CPU, Arm’s role in HPC is set to expand even further, likely enhancing both raw performance and efficiency.
Next-generation compute for Ansys Fluent simulation
Designing an efficient vehicle requires an understanding of aerodynamic performance. The drag of a vehicle directly influences the range. Therefore, many simulations need to be run to optimize the shape of the vehicle. These simulations are computationally expensive given the wide range of time and length scales that need to be captured. Running CFD tools like Ansys Fluent software quickly and efficiently is key.

Ansys ran Fluent 2024 R2 software on the Texas Advanced Computing Center (TACC) Vista supercomputer with 320 NVIDIA GH200 Grace Hopper Superchips, all connected with the NVIDIA Quantum-2 400Gb/s InfiniBand networking to enable scalable performance. The large, 2.4-billion cell automotive simulation would have taken nearly a month on 2,048 x86 CPU cores, but on Grace Hopper it ran 110x faster and was completed in just over 6 hours.
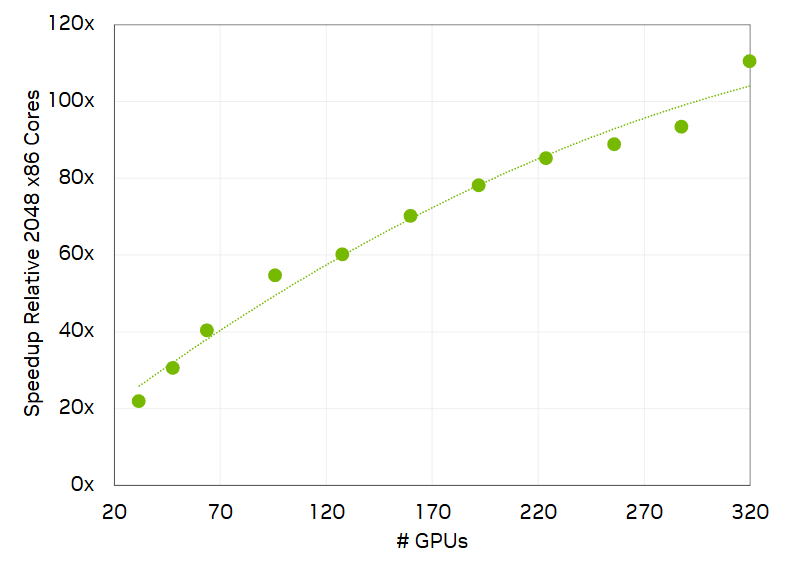
In addition to speed, energy and cost efficiencies are serious concerns. Ansys Fluent simulation on Grace Hopper also excels when evaluated for these metrics.
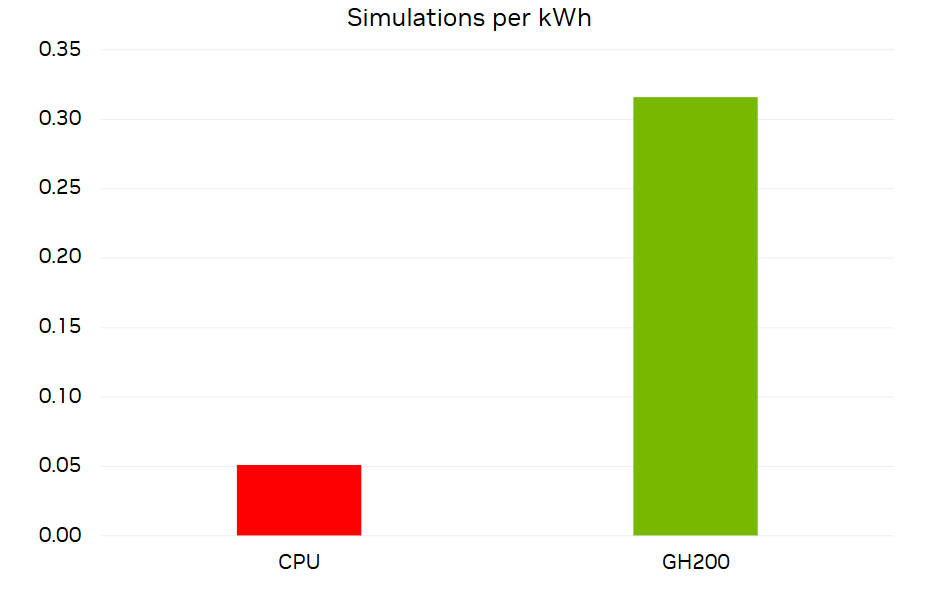
Figure 10 shows the number of DrivAer 2.4B simulations run for 1,000 iterations per kilowatt-hour in comparison to the same simulation on 2,048 cores of an x86 CPU. Though the Grace Hopper system uses more power, it finishes the simulation much faster, so it saves over six times the energy used by CPUs. To contextualize this, the average U.S. household uses 30 kWh per day. For that amount of energy, Grace Hopper could run a simulation of this size nine times. The CPU system could only run it 1.5 times.
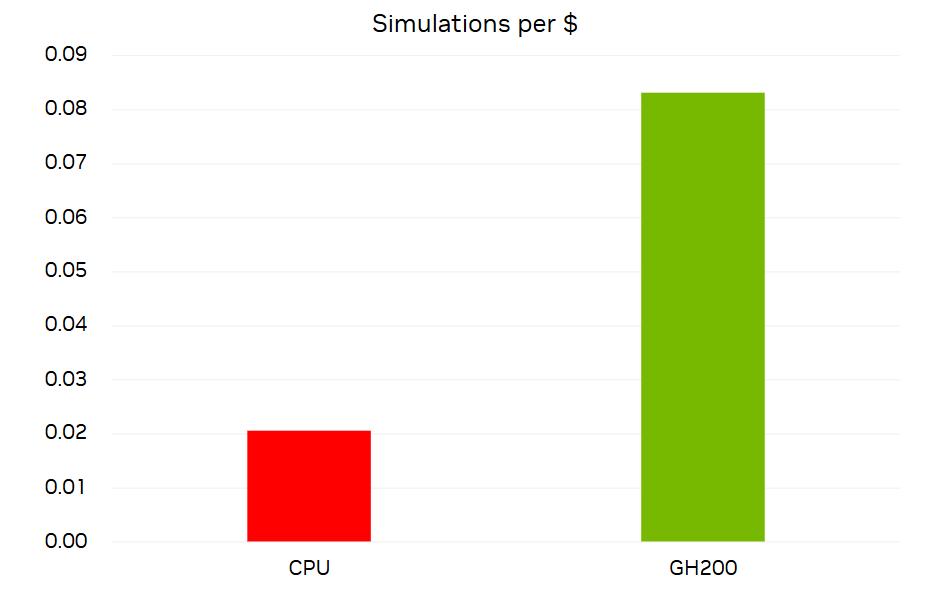
From a price performance standpoint, we completed a similar analysis but used standard pricing for the CPU server and Grace Hopper servers. With a useful life of 3 years for a supercomputer, we saw a 4x advantage to using Grace Hopper for large Ansys Fluent simulations such as the one presented in this post.
We calculated the number of simulations that could be done per dollar by calculating the number of 1,000 iteration simulations of DrivAer 2.4B that could be done in 3 years divided by the cost of 2,048 cores or 32 GPUs.
TACC Vista GH200 partition: 96 GB HBM3 / 120 GB LPDDR, NVIDIA Quantum-2 MQM9790 400Gb/s InfiniBand switch.
Experience NVIDIA Grace Hopper and NVIDIA Grace CPU
Sign up to test your workload’s performance on the NVIDIA Grace Superchip or NVIDIA Grace Hopper. Apply for system access to test your workload on Thea, an NVIDIA Quantum-2 InfiniBand-connected multinode environment hosted by the HPC-AI Advisory Council.
