
Kubernetes underpins a large portion of all AI workloads in production. Yet, maintaining GPU nodes and ensuring that applications are running, training jobs are progressing, and traffic is served across Kubernetes clusters is easier said than done.
NVSentinel is designed to help with these challenges. An open source system for Kubernetes AI clusters, NVSentinel continuously monitors GPU health and automatically remediates issues before they disrupt workloads.
A health system for Kubernetes GPU clusters
NVSentinel is an intelligent monitoring and self-healing system for Kubernetes clusters that run GPU workloads. Just as a building’s fire alarm continuously monitors for smoke and automatically responds to threats, NVSentinel continuously monitors your GPU hardware and automatically responds to failures. It’s part of a broader category of health automation open source tools designed to improve GPU uptime, utilization, and reliability.
GPU clusters are expensive and failures are costly. In modern AI and high-performance computing, organizations operate large clusters of servers with NVIDIA GPUs that can cost tens of thousands of dollars each. If those GPUs fail, the results could include:
- Silent corruption: Faulty GPUs producing incorrect results that go undetected
- Cascading failures: One bad GPU crashing an entire multiday training job
- Wasted resources: Healthy GPUs sitting idle while waiting for a failed node to recover
- Manual intervention: On-call engineers getting paged at all hours to diagnose issues
- Lost productivity: Data scientists spending hours re-running failed experiments
Traditional monitoring systems detect problems but rarely fix them. Correctly diagnosing and remediating GPU issues still requires deep expertise, and remediation can take hours or even days.
NVIDIA runs some of the world’s largest GPU clusters to support products and research efforts such as NVIDIA Omniverse, NVIDIA Cosmos, and NVIDIA Isaac GR00T. Maintaining the health of these clusters at scale requires automation.
Over the past year, NVIDIA teams have been developing and testing NVSentinel internally across NVIDIA DGX Cloud clusters. It has already helped reduce downtime and improve utilization by detecting and isolating GPU failures in minutes instead of hours.
How does NVSentinel work?
NVSentinel is installed in each Kubernetes cluster run. Once deployed, NVSentinel continuously watches nodes for errors, analyzes events, and takes automated actions such as quarantining, draining, labeling, or triggering external remediation workflows. Specific NVSentinel features include continuous monitoring, data aggregation and analysis, and more, as detailed below.
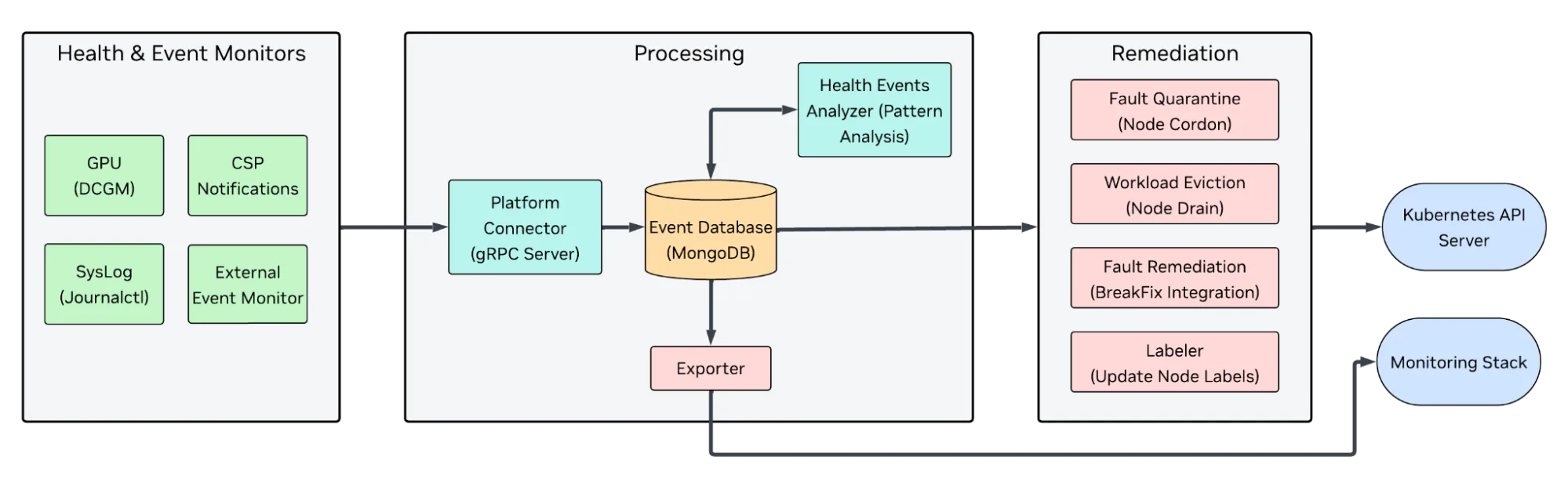
Continuous monitoring
NVSentinel deploys modular GPU and system monitors to track thermal issues, memory errors, and hardware faults using NVIDIA DCGM diagnostics. It also inspects kernel logs for driver crashes and hardware errors, and can integrate with cloud provider APIs (AWS, GCP, OCI) to detect maintenance events or hardware faults. The modular design makes it easy to extend with custom monitors and data sources.
Data aggregation and analysis
Collected signals flow into the NVSentinel analysis engine, which classifies events by severity and type. Using rule-based patterns similar to operational runbooks, it distinguishes between transient issues, hardware faults, and systemic cluster problems. For example:
- A single correctable ECC error might be logged and monitored
- Repeated uncorrectable ECC errors trigger node quarantine
- Driver crashes lead to node drain and cordon actions
This approach shifts health management in the cluster from “detect and alert” to “detect, diagnose, and act,” with policy-driven responses that you can declaratively configure.
Automated remediation
When a node is identified as unhealthy, NVSentinel coordinates the Kubernetes-level response:
- Cordon and drain to prevent workload disruption
- Set NodeConditions that expose GPU or system health context to the scheduler and operators
- Trigger external remediation hooks to reset or reprovision hardware
The NVSentinel remediation workflow is pluggable by design. If you already have an existing repair or reprovisioning workflow, it can be seamlessly integrated with NVSentinel. This makes it easy to connect with custom systems such as service management platforms, node imaging pipelines, or cloud automation tools.
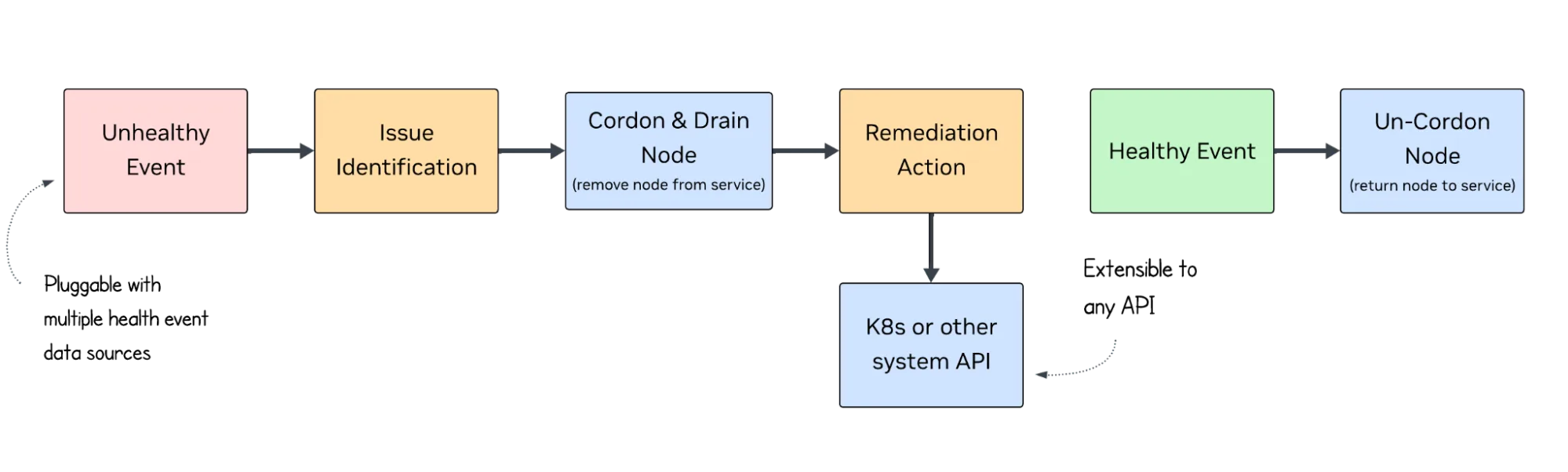
The system is disaggregated, enabling operators to use only the components they need. It is designed to fit into diverse operational models rather than replace them. You may choose to:
- Deploy only monitoring and detection
- Enable automated cordon and drain actions
- Enable full closed-loop remediation (for more advanced environments).
Example: Detecting and recovering from GPU errors
To provide an example, consider a 64-GPU training job. One node starts reporting repeated double-bit ECC errors. Traditionally, this might go unnoticed until the job fails hours later. With NVSentinel, the GPU Health Monitor detects the pattern, the Analyzer classifies the node as degraded, the node is cordoned and drained, and a remediation workflow reprovisions the node. The job continues with minimal disruption, saving hours of GPU time and preventing wasted compute.
How to get started with NVSentinel
NVSentinel uses the NVIDIA Data Center GPU Manager (DCGM), deployed through the NVIDIA GPU Operator, to collect GPU and NVIDIA NVSwitch health signals. If your environment supports the GPU Operator and DCGM, NVSentinel can monitor and act on GPU-level faults.
Supported NVIDIA hardware includes all data center GPUs supported by DCGM, such as:
- NVIDIA B200 series
- NVIDIA GB200, GB300
- NVIDIA H100 (80 GB, 144 GB, NVL)
- NVIDIA A100 (PCIe and SXM4)
- NVIDIA A30 / A40
- NVIDIA P100, P40, P4
- NVIDIA K80 and newer NVIDIA Tesla-class data center GPUs
DCGM also exposes telemetry for NVSwitch-based systems, enabling NVSentinel to monitor NVIDIA DGX and HGX platforms, including DGX A100, DGX H100, HGX A100, HGX H100, and HGX B200. For an authoritative list, see the DCGM Supported Products documentation.
Installation
You can deploy NVSentinel into your Kubernetes clusters using a single command:
helm install nvsentinel oci://ghcr.io/nvidia/nvsentinel --version v1.0.0
The NVSentinel documentation explains how to integrate with DCGM, customize monitors and actions, and deploy on-premises or in the cloud. Example manifests are included for both environments.
More NVIDIA initiatives for advancing GPU health
NVSentinel is also part of a broader set of NVIDIA initiatives focused on advancing GPU health, transparency, and operational resilience for customers. These initiatives include the NVIDIA GPU Health service, which provides fleet-level telemetry and integrity insights that complement NVSentinel Kubernetes-native monitoring and automation. Together, these efforts reflect NVIDIA’s ongoing commitment to helping operators run healthier and more reliable GPU infrastructure at every scale.
Early adopter experiences
NVIDIA DevOps and SRE teams are using NVSentinel as their preferred health automation tool for running AI training, inferencing, and simulation workloads on Kubernetes-accelerated compute clusters. Some note that NVSentinel has been effective for automating node and cluster-level health diagnosis, triage, cordon/drain, and remediation actions—in “seconds” versus “hours to days” for manual health detection-to-remediation approaches.
Get involved with NVSentinel
NVSentinel reached Beta/Stable status with v1.0.0. We recommend it for production testing and use. Note that APIs and configurations may change between releases. We encourage you to try it and leave feedback through NVIDIA/NVSentinel using GitHub issues. Upcoming releases will expand GPU telemetry coverage and logging systems such as NVIDIA DCGM, and add more remediation workflows and policy engines. More stability checks and documentation will also be added as the project continues to mature.
NVSentinel is open source, and we welcome contributions. To get involved, you can:
- Test NVSentinel on your own GPU clusters
- Share feedback and feature requests through the NVIDIA/NVSentinel GitHub repo
- Contribute new monitors, analysis rules, or remediation workflows
To get started, visit the NVIDIA/NVSentinel GitHub repo and follow the NVSentinel project road map for regular updates.
March 2026 update: NVSentinel has reached Beta/Stable with v1.0.0, and it is recommended for production testing and use. At NVIDIA, NVSentinel is now running on cloud and bare metal clusters, maintaining the health of 40,000+ GPUs. Since launch: 13 releases, 400+ commits, and external contributions from engineers across NVIDIA partner companies. Key additions include GPU reset, Kubernetes object monitor, event exporter, preflight checks, Slinky drain support, and GB200/GB300 support. For more details, see the NVSentinel v1.0.0 Release Notes.
