
Since its debut in 2023, the NVIDIA Grace CPU has experienced rapid adoption across data centers, setting new benchmarks for performance efficiency across diverse workloads. Grace integrates Arm Neoverse cores with NVIDIA Scalable Coherency Fabric (SCF), high-bandwidth LPDDR5X memory, and NVIDIA NVLink-C2C interconnect, delivering breakthrough bandwidth, low-latency scalability, and energy efficiency.
In this blog post, we’ll explore the advantages of the Grace Non-Uniform Memory Access (NUMA) monolithic architecture. We’ll dive into memory bandwidth per-core, scalability, and efficiency, and compare its design approach to traditional x86 chiplet-based CPUs.
Single NUMA design
Grace CPU features a coherent mesh interconnect that unifies all 72 Arm Neoverse cores into a single high-performance domain. Every core has equal access to memory without NUMA boundaries, simplifying software development, application scaling, and ensuring consistent performance across threads and workloads. This unified mesh fabric delivers similar memory access latencies for all cores, eliminating cross-NUMA transfers and the associated performance penalties. Grace’s unified cache and memory subsystem provides optimal inter-core latencies and higher cache hit rates without the die-to-die hops inherent to multi-chip design.
In cloud environments where smaller-sized virtual machines (VMs) are more prevalent among end users, Grace’s unified architecture enables each VM to access the full memory subsystem—an advantage over chiplet-based designs that partition memory across multiple dies. Legacy multi-chip architectures often require meticulous core pinning to maintain performance consistency, and when under-utilized, distributing workloads can incur additional power overhead from activating multiple chiplets.
Figure 1 below shows the NVIDIA SCF, which serves as the backbone, enabling the 72 Arm Neoverse cores, 114 MB unified L3 cache, 480 GB of LPDDR5X, and the 900 GB/s NVLink-C2C, all functioning as one coherent system on a single monolithic die. The illumination showcases data movement across the mesh grid without bottlenecks typically observed in chiplet-based designs.
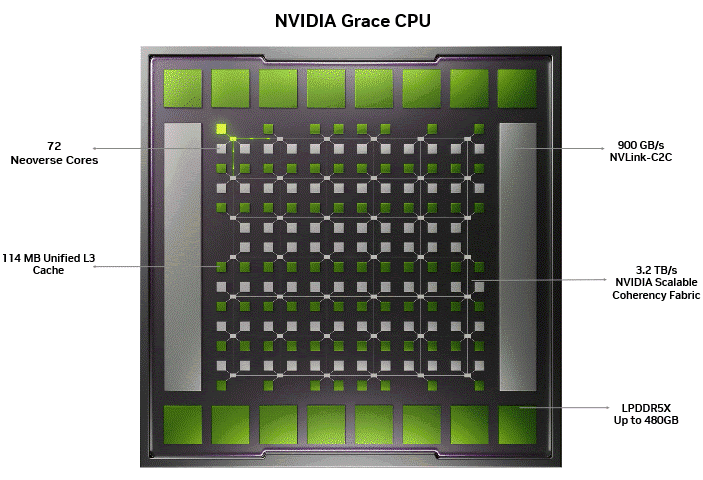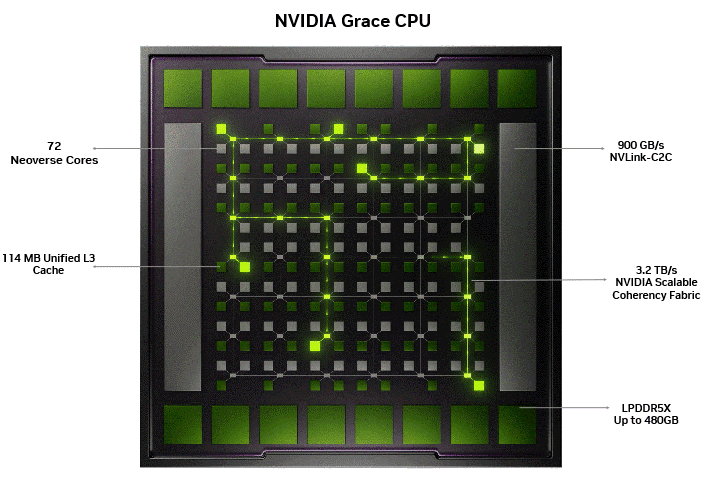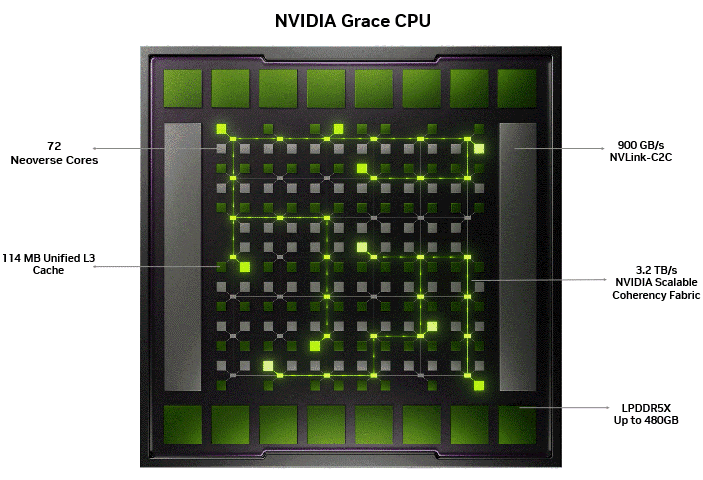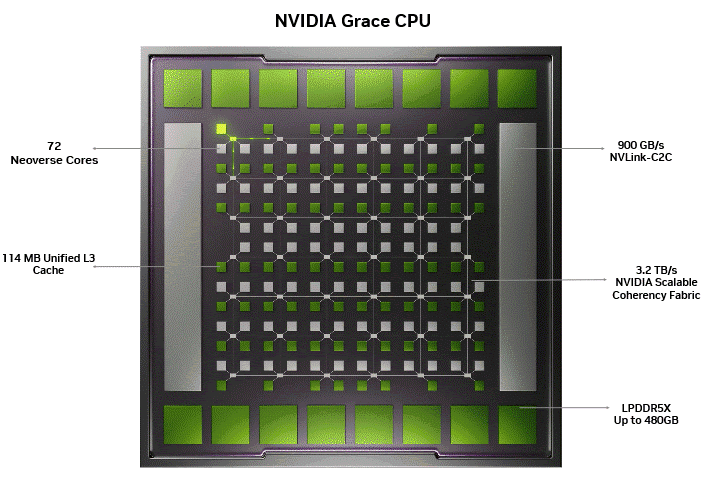
Optimal memory bandwidth scaling with core count
NVIDIA Grace CPU offers an optimal balance of core count and memory bandwidth, connected by a vast unified mesh that moves data across the system. Many data analytics, Extract, Transform, Load (ETL), and HPC workloads move vast amounts of data between cores, caches, and memory, demanding a well-balanced ratio of memory bandwidth to total core count.
As shown in Figure 2, STREAM benchmark measurements highlight Grace’s achievable memory bandwidth advantage. This benchmark is specifically designed to overwhelm CPU caches and force the system to perform large-scale, continuous data movement directly from memory.
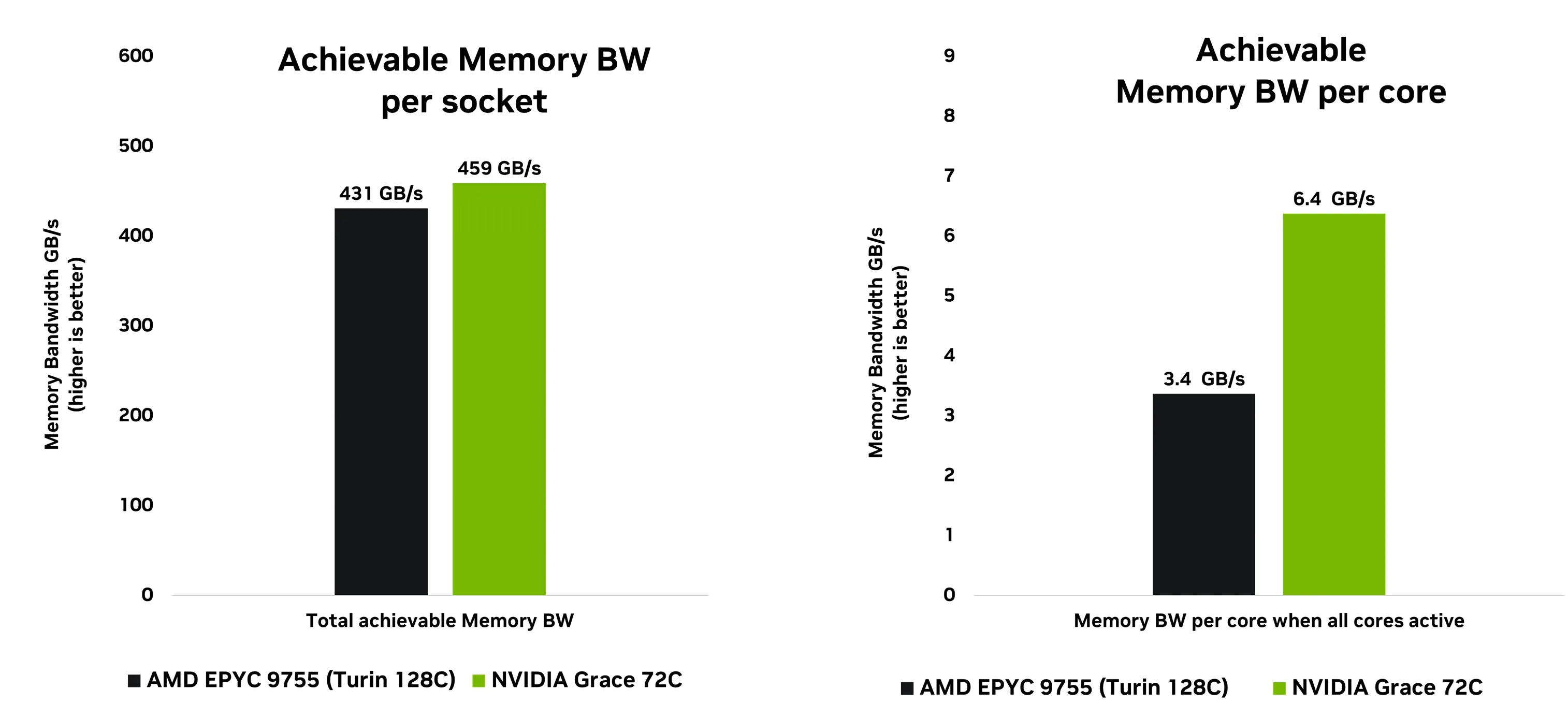
Grace surpasses AMD Turin in total achievable memory bandwidth, but its real strength lies in bandwidth efficiency. When all cores are active under full system stress, Grace delivers higher bandwidth per core, a key advantage for the next generation of data-driven computing. Grace provides up to 1.8x higher per-core memory bandwidth compared to competing SoCs, enabling every core to efficiently process massive data flows simultaneously across the mesh fabric and memory subsystem.
Grace for big data workloads
The benefits of Grace’s unified fabric and higher per-core memory bandwidth are evident in real-world data analytics workloads. For instance, the PageRank graph algorithm, part of the Graph Algorithm Platform Benchmark Suite (GAPBS), is a key workload for assessing system performance in graph analytics and big data. It’s designed to iteratively calculate a score of importance for every node in a massive graph, simulating real-world processes like ranking websites or analyzing social networks. The PageRank benchmark stresses both inter-core communication and the ability to efficiently handle large random, scattered memory access patterns.
Figure 3 shows the performance of the PageRank algorithm on both Grace and AMD Epyc Turin, run sequentially on cores 0 to 15. The key PageRank metric, traversed edges per second (TEPS), scales consistently with core count on the Grace CPU. This is made possible by the unified SCF, which enables seamless data movement across cores, caches, and the memory subsystem.
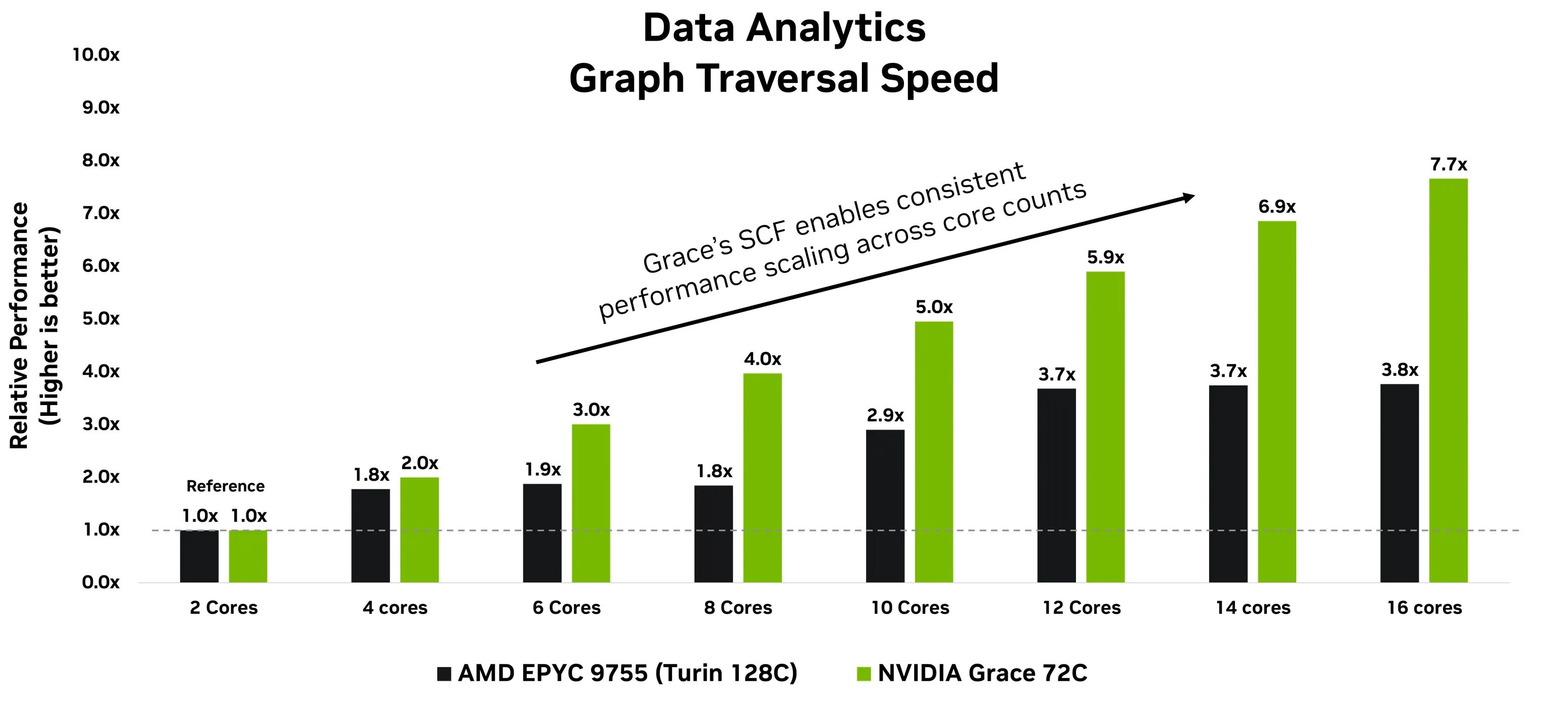
In contrast, chiplet-based x86 designs have uneven and limited scaling due to fragmented mesh and inter-die latencies. While fine-grained core pinning can yield modest gains on chiplet architectures, it’s often counterproductive for data analytics workloads and adds engineering overhead in real-world deployments. This problem is further exacerbated in cloud computing with smaller-sized VMs, where distributing cores may not be an option.
Grace outperforms x86 CPUs across data analytics and HPC workloads
Grace is the first server CPU with high-performance LPDDR5X memory and a fully coherent CPU-GPU interconnect (NVLink-C2C) running at 900 GB/s. This enables the next generation of AI factory and big data workloads.
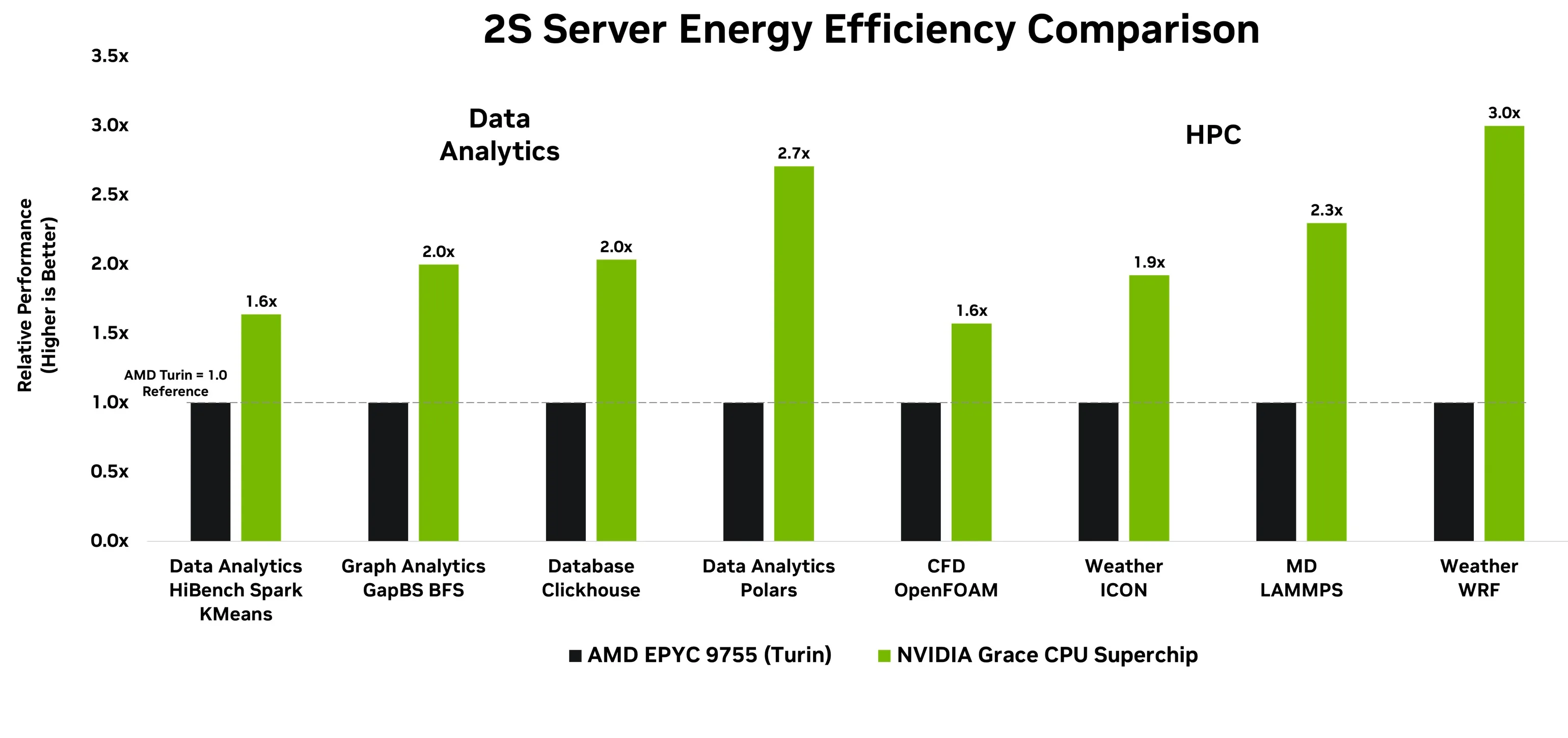
Figure 4 shows the performance-per-watt comparison of Grace vs AMD Epyc Turin in a two-socketed system. NVIDIA Grace offers up to 3x higher performance per watt across key data analytics, including OLAP, Graph, and ETL, and HPC workloads spanning CFD, Weather, and Molecular Dynamics, maximizing data-center throughput and lowering total cost of ownership.
Grace delivers high performance at low power
A key advantage of the Grace CPU’s power-efficient architecture is its ability to maintain high performance even when operating under lower power caps, which limit CPU-module power to reduce total rack energy and cooling demands. As data centers push towards higher compute density and tighter energy budgets, efficiency becomes increasingly important. Figure 5 shows Grace’s relative performance at several power-cap levels compared to its 250W baseline across identical workloads. Grace sustains over 90% performance at 200W and ~80% at 150W, enabling significant energy savings with minimal performance trade-offs.
This capability enables operators to tune for efficiency without sacrificing meaningful compute performance, maximizing rack-level density and reducing cooling costs in power-constrained environments.
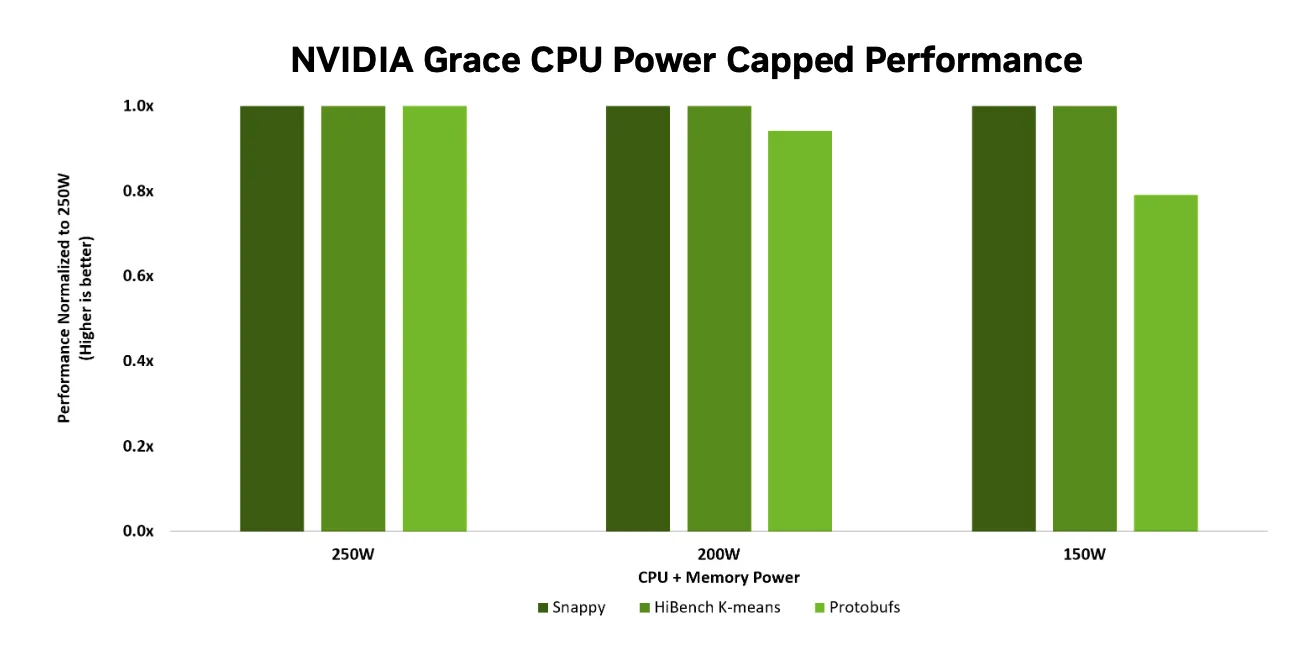
Grace achieves this balance through a combination of LPDDR5X memory, a power-efficient design with high-performance, and energy-efficient Arm Neoverse cores in a monolithic SoC die that minimizes off-chip communication. These technologies reduce data-movement overhead and deliver outstanding performance per watt. The result is a CPU that runs faster at lower power. It maintains performance headroom even under constrained power, making it ideal for modern, power-constrained environments spanning hyperscale deployments, high-performance edge, storage, CDN, high-performance computing (HPC), and other power-constrained use cases.
Powering the next generation of data factories
Grace sets the foundation of the NVIDIA CPU roadmap, delivering leadership performance, power efficiency, consistent core scaling, optimal mesh, and memory bandwidth in a single NUMA design, ideally suited for a diverse range of server deployments. Looking forward, we are very excited for the upcoming launch of our next-generation server CPU Vera, with 88 custom Arm Cores with multi-threading, a larger mesh, 1.2TB/s memory bandwidth, and 1.8 TB/s NVlink-C2C to drive the next generation of data compute.
Learn more about the NVIDIA Grace CPU performance and efficiency, optimizations, and software ecosystem.
NVIDIA Grace Superchip 480GB of LPDDR5X, AMD EPYC 9755 768 GB of DDR5
OS: Ubuntu 24.04 LTS Compilers: GCC 12.3 unless noted below. Power for energy efficiency includes CPU + memory
Data Analytics: HiBench+K-means Spark (HiBench 7.1.1, Hadoop 3.3.3, Spark 3.3.0;) Graph Analytics: The Gap Benchmarks Suite BFS, PR arXiv:1508.03619 [cs.DC], 2015, Dataset Kronecker
Database: Clickhouse Phoronix TestSuite gcc11 Polars-CPU PDS SF100 (hot cache parquet)
HPC: CFD: OpenFOAM v2406 Weather: ICON v2024.8_RC AMD MD: LAMMPS Phoronix TestSuite gcc11 Weather: WRF v4.6.0 AMD: ICC 2024.01
Compression: Snappy (Commit af720f9a3b2c831f173b6074961737516f2d3a46 | N instances in parallel)
Microservices: Google Protobufs (Commit 7cd0b6fbf1643943560d8a9fe553fd206190b27f | N instances in parallel)
Data Analytics: HiBench+K-means Spark (HiBench 7.1.1, Hadoop 3.3.3, Spark 3.3.0) | STREAM Triad
NVIDIA Grace CPU C1 OS: Ubuntu 22.04 Compilers: GCC 12.3 | AMD EPYC 9755 Turin –
High Performance Computing Tuning Guide
