
随着由 NVIDIA Blackwell GPU 架构驱动的 Jetson Thor SoC 即将支持 CUDA 13.0 版本,嵌入式与边缘计算领域将迎来更快速、更高效且更广泛的应用前景。
此版本的核心是面向 Arm 平台的统一 CUDA 工具包,不再需要为服务器级和嵌入式系统分别提供独立的工具包。Jetson Thor 还支持高度一致的统一虚拟内存(UVM)、多进程服务(MPS)和绿色上下文等 GPU 共享功能,同时提供增强的开发工具以及全新的互操作性选项。这些改进共同实现了更高效的开发流程,为边缘 AI 应用在性能和可移植性方面带来了更多可能性。
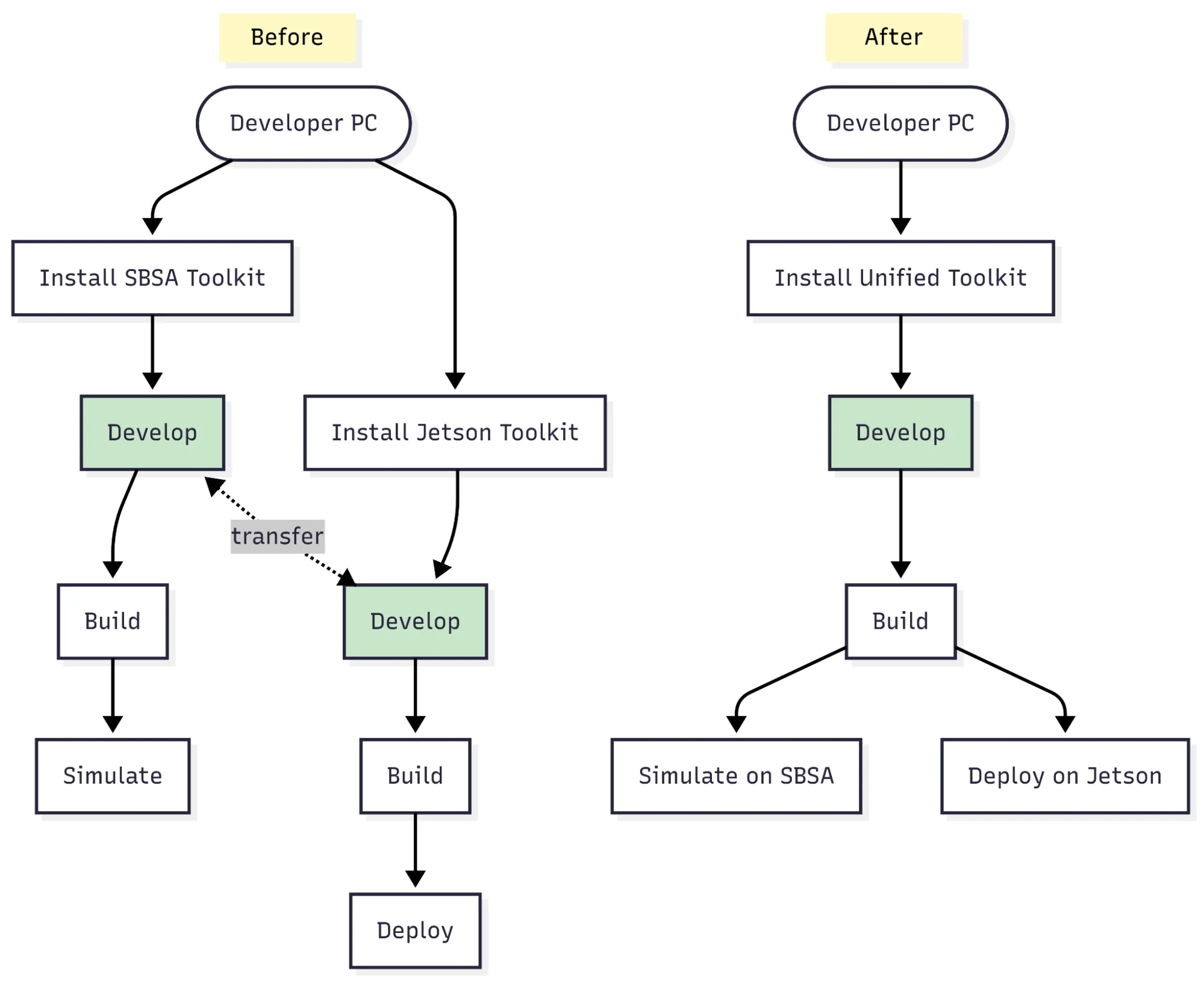
统一 CUDA for Arm:一次构建,随处部署
CUDA 13.0 通过统一服务器级和嵌入式设备的 CUDA 工具包,简化了 Arm 平台的开发。现在,您无需再为服务器基础系统架构(SBSA)兼容的服务器和 Thor 等新一代嵌入式系统分别维护独立的安装包或工具链。唯一的例外是 Orin(sm_87),目前仍沿用现有的独立路径。
这一变化带来了显著的生产力提升。开发者只需构建一次机器人或 AI 应用,便可在 GB200 和 DGX Spark 等高性能系统上进行仿真,并将完全相同的二进制文件直接部署到 Thor 等嵌入式目标上,无需修改任何代码。尽管编译器和运行时仍会针对目标 GPU 架构生成优化后的代码,但您不再需要维护两套独立的工具链即可实现这一过程,如图 1 所示。
这种统一还延伸至容器领域,通过整合镜像生态系统,使模拟、测试和部署工作流程能够依托一致的容器传承。这不仅减少了重复构建,降低了持续集成(CI)的开销,也实现了从代码到硬件的更顺畅交付路径。
对团队而言,这意味着减少 CI 工作流中的重复操作,简化容器管理,并降低因使用不同 SDK 而带来的不一致性。对组织而言,它提供了跨仿真与边缘平台构建的统一基准,节省了工程投入,提升了在不断演进的 GPU 架构和平台之间的可移植性。同时,它还为 Jetson 和 IGX 平台中集成 GPU(iGPU)与独立 GPU(dGPU)的协同使用创造了条件,实现更加无缝且高效的计算体验。
统一虚拟内存 (UVM) 和全一致性如何在 CUDA 13.0 中发挥作用
NVIDIA Jetson 平台将首次支持统一虚拟内存与完全一致性,使设备能够通过主机的分页表访问可分页的主机内存。
在 Jetson Thor 平台上,cudaDeviceProp::pageableMemoryAccessUsesHostPageTables 被设置为 1,表示 GPU 可以通过主机的分页表访问可分页的主机内存。GPU 对该 CPU 缓存显存的访问会在 GPU 端进行缓存,并由硬件互连技术确保完全一致性。在实际应用中,通过 mmap() 或 malloc() 创建的系统分配内存现在可直接在 GPU 上使用。
同样,通过 cudaMallocManaged() 创建的分配会将 cudaDeviceProp::concurrentManagedAccess 报告为 1,表明该内存可由设备与 CPU 同时访问,且 cudaMemPrefetchAsync() 等 API 能够正常工作。然而,在 CUDA 13.0 中,cudaMallocManaged() 分配不会被 GPU 缓存。这些变更使得 Jetson 平台上的 UVM 功能与 dGPU 系统保持一致。
以下示例展示了如何使用 mmap() 将文件映射到内存中,并在 GPU 内核中直接使用该指针执行直方图计算。通过 mmap() 可获取输出直方图缓冲区,且无需进行 CUDA 分配调用。输入数据与输出直方图均缓存在 GPU 的 L2 缓存中,并由系统自动维护一致性。这种方法避免了显式的 CUDA 内存分配或 cudaMemcpy() 调用,同时仍能保持较高的性能。
#include <stdio.h>
#include <stdlib.h>
#include <cuda_runtime.h>
#include <sys/mman.h>
#include <fcntl.h>
#include <unistd.h>
#define HIST_BINS 64
#define IMAGE_WIDTH 512
#define IMAGE_HEIGHT 512
// Error handling macro
#define CUDA_CHECK(call) \
if ((call) != cudaSuccess) { \
cudaError_t err = cudaGetLastError(); \
printf("CUDA error calling \""#call"\", code is %d\n", err); \
}
__global__ void histogram(
unsigned int elementsPerThread,
unsigned int *histogramBuffer,
unsigned int *inputBuffer)
{
unsigned int offset = threadIdx.x + blockDim.x * blockIdx.x;
unsigned int stride = gridDim.x * blockDim.x;
for (unsigned int i = 0; i < elementsPerThread; i++) {
unsigned int indexToIncrement = inputBuffer[offset + i * stride] % HIST_BINS;
atomicAdd(&histogramBuffer[indexToIncrement], 1);
}
}
int main(int argc, char **argv)
{
size_t alloc_size = IMAGE_HEIGHT * IMAGE_WIDTH * sizeof(int);
size_t hist_size = HIST_BINS * sizeof(int);
unsigned int *histogramBuffer = (unsigned int*)mmap(NULL, hist_size, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS, -1, 0);
unsigned int *inputBuffer;
cudaEvent_t start, end;
float timeInMs;
const unsigned int elementsPerThread = 4;
const unsigned int blockSize = 512;
dim3 threads(blockSize);
dim3 grid((IMAGE_WIDTH * IMAGE_HEIGHT) / (blockSize * elementsPerThread));
int fd;
if (setenv("CUDA_MODULE_LOADING", "EAGER", 1) != 0) {
printf("Error: Unable to set environment variable CUDA_MODULE_LOADING.\n");
return -1;
}
fd = open("inputFile.bin", O_RDONLY, 0);
if (fd == -1) {
printf("Error opening input file: inputFile.bin\n");
return -1;
}
inputBuffer = (unsigned int*)mmap(NULL, alloc_size, PROT_READ, MAP_PRIVATE, fd, 0);
CUDA_CHECK(cudaEventCreate(&start));
CUDA_CHECK(cudaEventCreate(&end));
CUDA_CHECK(cudaEventRecord(start, NULL));
histogram<<<grid, threads>>>(elementsPerThread, histogramBuffer, inputBuffer);
CUDA_CHECK(cudaEventRecord(end, NULL));
CUDA_CHECK(cudaStreamSynchronize(NULL));
CUDA_CHECK(cudaEventElapsedTime(&timeInMs, start, end));
printf("Elapsed Time was %f ms.\n", timeInMs);
munmap(histogramBuffer, hist_size);
munmap(inputBuffer, alloc_size);
close(fd);
return 0;
}
改进跨工作负载的 GPU 共享
CUDA 13.0 进一步强化了多 GPU 共享功能,旨在提升 GPU 的利用率和整体性能。
借助 MPS 在 Tegra 上充分发挥 GPU 潜力
随着 Tegra GPU 计算能力的不断提升,单个进程往往难以充分占用可用的 GPU 资源,尤其是在处理较小或突发性工作负载时(例如应用程序中的多个轻量级生成式 AI 智能体)。这种情况可能导致多进程系统的整体效率下降。
MPS 通过支持多个进程并发共享 GPU 来解决这一问题,有效避免了上下文切换的开销,实现了真正的并行执行。MPS 能够将轻量级工作负载整合到单一 GPU 环境中,从而提升资源占用率、吞吐量和系统可扩展性。尤为重要的是,MPS 无需修改应用程序代码,因此可便捷地应用于现有的多进程架构。
对于开发现代多进程应用的开发者而言,MPS 在充分释放 Tegra GPU 性能潜力方面起着关键作用。
开始在 Tegra 上使用 MPS:
有两个与 MPS 相关的二进制文件,名为 nvidia-cuda-mps-control 和 nvidia-cuda-mps-server,通常存放在 /usr/bin 目录下。
请按照以下步骤启动 MPS 控制守护进程:
export CUDA_MPS_PIPE_DIRECTORY=<Path to pipe dir>
export CUDA_MPS_LOG_DIRECTORY=<Path to log dir>
nvidia-cuda-mps-control -d # Start the control daemon in background mode
ps –ef | grep mps # To check if MPS control daemon has started
要将应用程序作为 MPS 客户端运行,需先设置管道和日志目录为守护进程模式,然后正常启动应用程序。日志将存储在 $CUDA_MPS_LOG_DIRECTORY/control.log 和 $CUDA_MPS_LOG_DIRECTORY/server.log 中。如需停止 MPS,请执行相应停止操作。
echo quit | nvidia-cuda-mps-control
有关更多详细信息,请参考 MPS 文档。
绿色环境下的确定性 GPU 调度
绿色上下文是一种轻量级的 CUDA 上下文,可预先分配 GPU 资源,特别是流式多处理器(SM),以实现确定性执行。通过提前分配 SM,各个环境能够独立运行,不受其他环境活动的干扰,从而提升延迟敏感型工作负载的执行可预测性。
例如,Jetson 上的机器人应用可能需要同时运行 SLAM、物体检测和运动规划,而这些任务各自具有不同的实时性要求。为了满足可预测的延迟、资源隔离以及高效的 GPU 利用率等综合需求,开发者可以结合使用多实例 GPU(MIG,将在未来版本中推出)、绿色环境和 MPS 技术。
MIG 技术可将 GPU 划分为多个相互隔离的切片,使 SLAM 等时间关键型模块免受对时间敏感度较低任务所占用资源的干扰。在每个 MIG 切片中,绿色上下文支持将流式多处理器(SM)确定性地分配给特定的 CUDA 上下文。多个进程可分别通过 CUDA 驱动 API(如 cuDevSmResourceSplitByCount 和 cuGreenCtxCreate)创建绿色上下文,实现 SM 资源的非重叠分配。以下代码片段展示了绿色上下文的使用方法:
CUdevResource fullSMs;
CUdevResource smGroupA, smGroupB;
CUdevResourceDesc descA, descB;
CUgreenCtx ctxA, ctxB;
CUstream streamA, streamB;
// Get all SMs from device
cuDeviceGetDevResource(device, &fullSMs, CU_DEV_RESOURCE_TYPE_SM);
// Split SMs: assign 1 SM to ctxA, rest to ctxB
unsigned int minCount = 1;
cuDevSmResourceSplitByCount(&smGroupA, &nbGroups, &fullSMs, &smGroupB, 0, minCount);
// Generate descriptors
cuDevResourceGenerateDesc(&descA, &smGroupA, 1);
cuDevResourceGenerateDesc(&descB, &smGroupB, 1);
// Create Green Contexts
cuGreenCtxCreate(&ctxA, descA, device, CU_GREEN_CTX_DEFAULT_STREAM);
cuGreenCtxCreate(&ctxB, descB, device, CU_GREEN_CTX_DEFAULT_STREAM);
// Create streams bound to contexts
cuGreenCtxStreamCreate(&streamA, ctxA, CU_STREAM_NON_BLOCKING, 0);
cuGreenCtxStreamCreate(&streamB, ctxB, CU_STREAM_NON_BLOCKING, 0);
使用 MPS 时,只需将环境变量 CUDA_MPS_ACTIVE_THREAD_PERCENTAGE 设置为 100 或不设置,即可实现跨进程的并发执行,同时保持 SM 隔离。该配置有助于为各个模块维持稳定的性能表现,在机器人领域尤为重要,因为实时性保障和高效的多任务处理对安全、快速响应的操作至关重要。
借助增强的开发者工具实现更出色的可见性和可控性
CUDA 13.0 为 Jetson Thor 平台带来了重要的开发者工具增强功能,新增了对 nvidia-smi 实用程序和 NVIDIA 管理库(NVML) 的支持。这些工具此前已在 dGPU 开发者中广泛应用,如今将帮助 Jetson 开发者更深入地了解 GPU 使用情况,并实现更高效的资源控制。
借助 nvidia-smi,开发者可查询 GPU 的详细信息,如设备名称、型号、驱动版本及支持的 CUDA 版本,同时还能实时获取 GPU 利用率,便于在开发与调试过程中更高效地监控工作负载的运行状态。
NVML 库通过 C 和 Python API 提供对类似功能的编程访问,便于将 GPU 的监控与管理集成到自定义工具、CI 工作流或部署脚本中。
尽管 Jetson Thor 目前已支持 nvidia-smi 和 NVML,但部分功能(如时钟、功耗和温度查询,按进程的利用率统计,以及 SoC 显存监控)尚不可用。此版本是迈向完善支持的重要一步,后续更新有望实现更全面的功能对等。
使用 DMABUF 简化内存共享
CUDA 13.0 支持将分配的 CUDA 缓冲区与 dmabuf 文件描述符相互转换。在 Linux 系统上,dmabuf 提供了一个标准化的接口,用于在多个内核模式设备驱动程序之间共享和同步 I/O 缓冲区的访问。应用程序在用户空间中以 Linux 文件描述符(FD)的形式接收这些缓冲区,从而实现不同子系统间的零拷贝共享。
在 Jetson Automotive 等 Tegra 平台上,EGL 或 NvSci 方案通常被用于内存共享。随着 OpenRM 和 L4T 插件采用基于 FD 的机制,集成 dmabuf 并结合现有的专有方案,成为实现 CUDA、第三方设备与开源软件堆栈之间高效互操作性的关键一步。
将 dmabuf 通过 CUDA 外部资源互操作性 API 导入显存,同时将 dmabuf 作为新的外部显存类型添加。图 2 概述了这一过程。

通过受支持的 OpenRM 平台,应用程序可利用驱动 API 调用将 CUDA 分配导出为 dmabuf。可通过 cuDeviceGetAttribute() 查询 CU_DEVICE_ATTRIBUTE_HOST_ALLOC_DMA_BUF_SUPPORTED 属性来检查平台是否支持该功能;若系统支持并可检索 CUDA 主机内存分配中的 dmabuf,则会返回 1。图 3 展示了应用程序如何在 CUDA 与外部环境之间导入和导出 dmabuf fds。

将 NUMA 感知型应用移植到 Jetson Thor
CUDA 13.0 为 Tegra 引入了对非统一内存访问(NUMA)架构的支持。在 NUMA 架构中,CPU 核心和内存被划分为多个节点,每个节点访问本地内存的延迟低于访问其他节点内存的延迟。这一特性使支持 NUMA 的应用程序能够显式控制内存的分配位置,从而提升性能。
该功能简化了多插槽系统的开发,同时提升了单插槽系统的兼容性。过去,从 dGPU 平台移植的 NUMA 感知应用程序需要进行修改,因为 Jetson 不支持带有 CU_MEM_LOCATION_TYPE_HOST_NUMA 的 cuMemCreate()。尽管 Jetson Thor 仅包含一个 NUMA 节点,但此次更新使得原本为 dGPU 平台开发的应用程序能够在 Tegra 上无缝运行,无需对代码进行任何修改。
使用步骤如下:
CUmemGenericAllocationHandle handle;
CUmemAllocationProp prop;
// size = <required size>; numaId = <desired Numa Id>
memset(&prop, 0, sizeof(CUmemAllocationProp));
prop.location.type = CU_MEM_LOCATION_TYPE_HOST_NUMA;
prop.location.id = numaId;
prop.requestedHandleTypes = CU_MEM_HANDLE_TYPE_NONE;
prop.type = CU_MEM_ALLOCATION_TYPE_PINNED;
prop.win32HandleMetaData = NULL;
CHECK_DRV(cuMemCreate(&handle, size, &prop, 0ULL));
未来趋势
多实例 GPU(MIG)功能可将大型 GPU 划分为多个较小的独立设备,每个设备拥有专用资源,实现资源隔离并避免相互干扰。该技术使不同关键等级的工作负载能够并行运行,从而提升系统确定性与故障隔离能力。
例如,在机器人开发中,某些工作负载(如 SLAM)通常被赋予比路径规划等任务更高的优先级。通过将(Thor)GPU 划分为两个实例——其中一个专用于执行关键工作负载,另一个处理优先级较低的任务——可以显著提升关键进程运行的确定性。这种配置避免了关键工作负载与其他任务竞争 GPU 资源,从而实现更可预测的实时性能。<!–
随着 CUDA 13.0 引入对 nvidia-smi 工具和 NVIDIA 管理库(NVML) 的支持,未来的 JetPack 版本有望实现一系列新功能,包括时钟频率、功耗、温度查询、各进程的资源利用率以及 SoC 显存使用情况的监控。
CUDA 13 针对 Jetson Thor 推出的新功能,标志着开发者体验向统一化和简化迈出了重要一步,实现了从复杂的并行工具链转向在 Arm 架构上部署单一 CUDA 的目标。新增的驱动功能以及高级特性(如 UVM、MIG 和 MPS)使 Jetson 平台在性能表现和应用灵活性方面都得到了显著提升。
您可立即在 JetPack 7.0 版本中体验 CUDA 13.0 工具包。欢迎加入 NVIDIA 开发者论坛,分享使用心得,或在将这些新功能集成到应用中时获取技术支持。
敬请持续关注我们不断创新、持续突破 CUDA 领域边界的更多最新动态。
致谢
感谢以下 NVIDIA 贡献者:Saumya Nair、Ashish Srivastava、Debalina Bhattacharjee、Alok Parikh、Quinn Zambeck、Ashutosh Jain 以及 Raveesh Nagaraja Kote。





