在这篇文章中,我们详细介绍了最近发布的 NVIDIA 时间序列预测平台( TSPP ),这是一个设计用于轻松比较和实验预测模型、时间序列数据集和其他配置的任意组合的工具。 TSPP 还提供了探索超参数搜索空间的功能,使用分布式训练和自动混合精度( AMP )运行加速模型训练,并在NVIDIA Triton 推理服务器上加速和运行加速模型格式的推理。
事实证明,在理解和管理复杂系统(包括但不限于电网、供应链和金融市场)时,使用以前的值准确预测未来的时间序列值至关重要。在这些预测应用中,预测精度的单位百分比提高可能会产生巨大的财务、生态和社会影响。除了需要精确之外,预测模型还必须能够在实时时间尺度上运行。
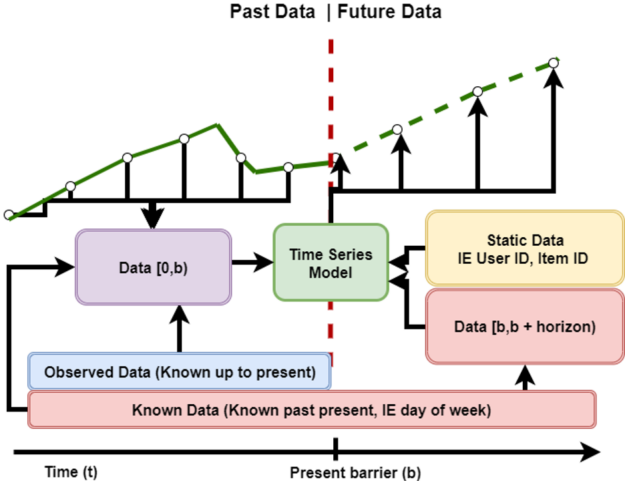
滑动窗口预测问题,如图 1 所示,涉及使用先前的数据和未来值的知识来预测未来的目标值。传统的统计方法,如 ARIMA 及其变体,或 Holt-Winters 回归,长期以来一直用于执行这些任务的回归。然而,随着数据量的增加和回归所要解决的问题变得越来越复杂, 深度学习 方法已经证明它们能够有效地表示和理解这些问题。
尽管出现了深度学习预测模型,但从历史上看,还没有一种方法可以有效地在任意一组数据集中试验和比较时间序列模型的性能和准确性。为此,我们很高兴公开开源 NVIDIA 时间序列预测平台 。
什么是 TSPP ?
时间序列预测平台是一个端到端的框架,使用户能够训练、调整和部署时间序列模型。其分层配置系统和丰富的功能规范 API 允许轻松集成和试验新模型、数据集、优化器和指标。 TSPP 设计用于香草 PyTorch 型号,对云或本地平台不可知。
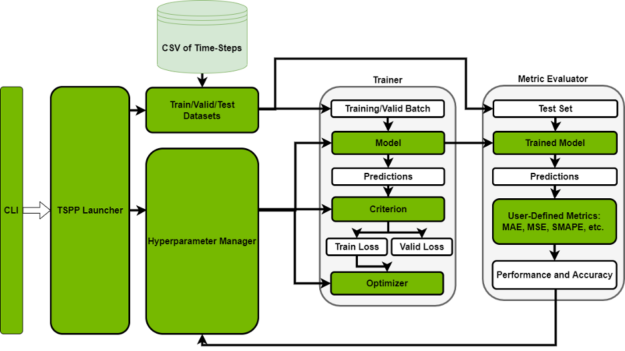
TSPP 如图 2 所示,以命令行控制的启动器为中心。根据用户对 CLI 的输入,启动器可以实例化 hyperparameter 管理器,该管理器可以并行运行一组训练实验,也可以通过创建所描述的组件(如模型、数据集、度量等)来运行单个实验。
支持的模型
TSPP 默认支持 NVIDIA 优化时间融合变压器 ( TFT )。在 TSPP 中, TFT 训练可以使用多 GPU 训练、自动混合精度和指数移动权重平均来加速。可以使用上述推理和部署管道部署模型。
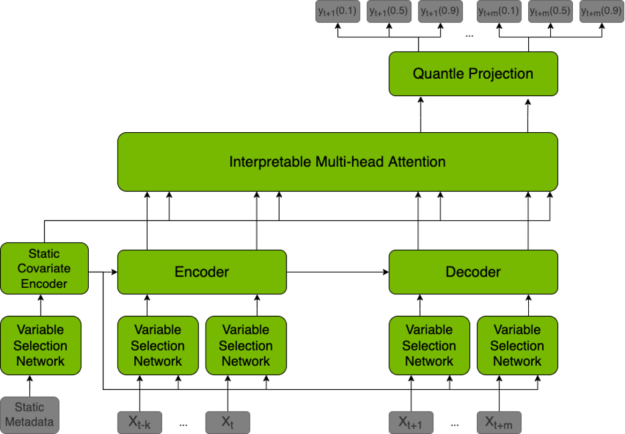
TFT 模型是一种混合架构,将 LSTM 编码和可解释 transformer 注意层结合在一起。预测基于三种类型的变量:静态(给定时间序列的常数)、已知(整个历史和未来提前知道)、观察(仅历史数据已知)。所有这些变量都有两种类型:分类变量和连续变量。除了历史数据,我们还向模型提供时间序列本身的历史值。
通过学习嵌入向量,将所有变量嵌入高维空间。范畴变量嵌入是在嵌入离散值的经典意义上学习的。该模型为每个连续变量学习一个向量,然后根据该变量的值进行缩放,以便进一步处理。下一步是通过变量选择网络( VSN )过滤变量,该网络根据输入与预测的相关性为输入分配权重。静态变量用作其他变量的变量选择上下文,以及 LSTM 编码器的初始状态。
编码后,变量被传递给多头注意层(解码器),从而产生最终的预测。整个体系结构与剩余连接交织在一起,门控机制允许体系结构适应各种问题。
加速训练
在使用深度学习模型进行实验时,训练加速可以极大地增加在给定时间内可以进行的实验迭代次数。时间序列预测平台提供了通过自动混合精度、多 GPU 训练和指数移动权重平均的任意组合来加速训练的能力。
训练快速开始
一旦进入 TSPP 容器,运行 TSPP 就很简单,只需结合数据集、模型和其他您想要使用的组件调用启动器。例如,要使用电力数据集训练 TFT ,我们只需调用:
Python launch_tspp.py dataset=electricity model=tft criterion=quantile
生成的日志、检查点和初始配置将保存到输出中。有关包含更复杂工作流的示例,请参考 repository 文档 。
自动混合精度
自动混合精度( AMP )是深度学习培训的一种执行模式,适用的计算以 16 位精度而不是 32 位精度计算。 AMP 执行可以极大地加快深度学习训练,而不会降低准确性。 AMP 包含在 TSPP 中,只需在启动呼叫中添加一个标志即可启用。
多 GPU 训练
多 GPU 数据并行训练通过在所有可用 GPU 上并行运行模型计算来增加全局批量大小,从而加速模型训练。这种方法可以在不损失模型精度的情况下大大缩短模型训练时间,尤其是在使用了许多 GPU 的情况下。它通过 PyTorch DistributedDataParallel 包含在 TSPP 中,只需在启动调用中添加一个元素即可启用。
指数移动加权平均
指数移动加权平均是一种技术,它维护一个模型的两个副本,一个通过反向传播进行训练,另一个模型是第一个模型权重的加权平均。在测试和推理时,平均权重用于计算输出。实践证明,这种方法可以缩短收敛时间,提高收敛精度,但代价是模型 GPU 内存需求翻倍。 EMWA 包含在 TSPP 中,只需在启动调用中添加一个标志即可启用。
没有超参数
模型超参数调整是深度学习模型的模型开发和实验过程中必不可少的一部分。为此, TSPP 包含与 Optuna 超参数搜索库的丰富集成。用户可以通过指定要搜索的超参数名称和分布来运行广泛的超参数搜索。一旦完成, TSPP 可以并行运行多 GPU 或单 GPU 试验,直到探索出所需数量的超参数选项。
搜索完成时, TSPP 将返回最佳单次运行的超参数,以及所有运行的日志文件。为了便于比较,日志文件是用NVIDIA DLLOGER 生成的,并且易于搜索,并且与张量板绘图兼容。
可配置性
TSPP 中的可配置性由 Facebook 提供的开源库 Hydra 驱动。 Hydra 允许用户使用运行时组合的 YAML 文件定义分层配置系统,使启动运行简单到声明“我想用这个数据集尝试这个模型”。
特性规范
特征规范包含在配置的数据集部分,是时间序列数据集的标准描述语言。它对每个表格特征的属性进行编码,其中包含关于未来是已知的、观察到的还是静态的、特征是分类的还是连续的以及更多可选属性的信息。这种描述语言为模型提供了一个框架,可以根据任意描述的输入自动配置自己。
组件集成
向 TSPP 添加一个新的数据集非常简单,只需为其创建一个功能规范并描述数据集本身。一旦定义了特征规范和其他一些关键值,与 TSPP 集成的模型将能够根据新的数据集进行配置。
将新模型添加到 TSPP 只需要模型期望特性规范提供的数据位于正确的通道中。如果模型正确地解释了功能规范,那么模型应该与集成到 TSPP 、过去和未来的所有数据集一起工作。
除了模型和数据集, TSPP 还支持任意组件的集成,例如标准、优化器和目标度量。通过使用 Hydra 使用 config 直接实例化对象,用户可以集成他们自己的定制组件,并在 TSPP 发布时使用该规范。
推理和部署
推理是任何 Machine Learning 管道的关键组成部分。为此, TSPP 内置了推理支持,可与平台无缝集成。除了支持本机推理, TSPP 还支持将转换后的模型单步部署到 NVIDIA Triton 推理服务器。
NVIDIA Triton 型号导航器
TSPP 为 NVIDIA Triton 型号导航器 。兼容的模型可以轻松转换为优化的格式,包括 TorchScript 、 ONNX 和 NVIDIA TensorRT 。在同一步骤中,这些转换后的模型将部署到 NVIDIA Triton 推理服务器 。甚至可以选择在单个步骤中对给定模型进行剖面分析和生成舵图。例如,给定一个 TFT 输出文件夹,我们可以通过使用以下命令导出到 ONNX ,将模型转换并部署为 fp16 中的 NVIDIA TensorRT 格式:
Python launch_deployment.py export=onnx convert=trt config.inference.precision=fp16 config.evaluator.checkpoint=/path/to/output/folder/
TFT 模型
我们在两个数据集上对 TSPP 内的 TFT 进行了基准测试: UCI 数据集存储库中的电力负荷(电力)数据集和 PEMs 流量数据集(流量)。 TFT 在两个数据集上都取得了很好的结果,在两个数据集上都实现了最低的可见误差,并证实了 TFT 论文作者的评估。
| Dataset | Mean Absolute Error | Root Mean Squared Error |
| Electricity | 43.807 | 142307.152 |
| Traffic | 0.005081 | 0.018 |
训练表现
图 4 和图 5 分别显示了电力和交通数据集上 TFT 的每秒吞吐量。每个批次大小为 1024 ,包含来自同一数据集中不同时间序列的各种时间窗口。使用自动混合精度计算了 100 次运行。显然, TFT 在 A100 GPU 上具有优异的性能和可扩展性,尤其是与在 96 核 CPU 上执行相比。
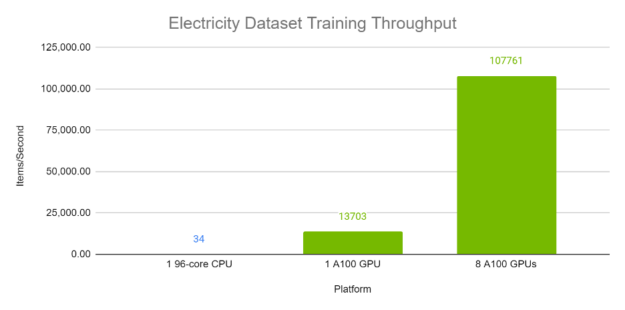
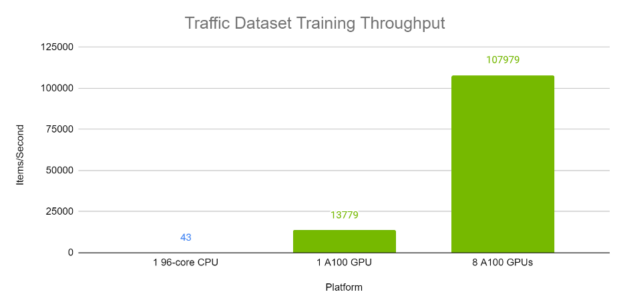
训练时间
图 6 和图 7 分别显示了 TFT 在电力和交通数据集上的端到端训练时间。每个批次大小为 1024 ,包含来自同一数据集中不同时间序列的各种时间窗口。使用自动混合精度计算 100 次完成的运行。在这些实验中,在 GPU 上, TFT 的训练时间为分钟,而 CPU 的训练时间约为半天。
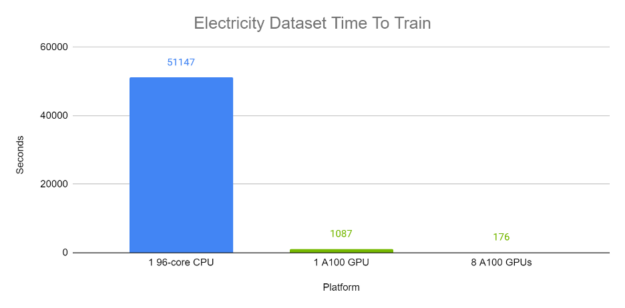
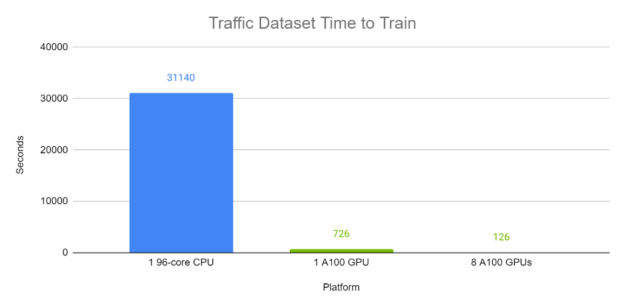
推理性能
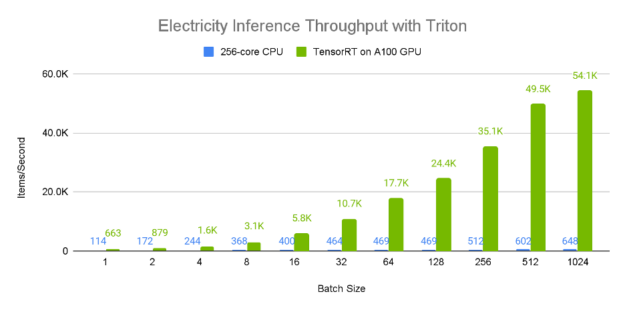
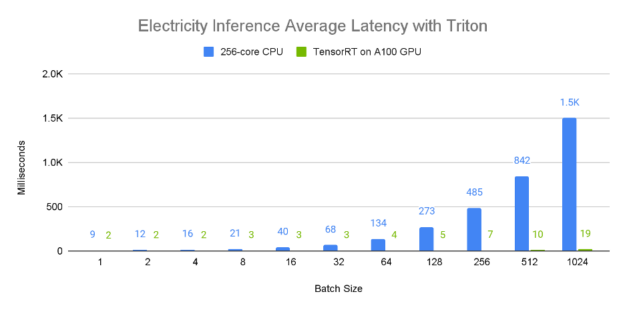
图 8 和图 9 展示了电力数据集上不同批量大小的 A100 80GB GPU 与 96 核 CPU 的相对单设备推理吞吐量和平均延迟。由于较大的批量大小通常产生更大的推断吞吐量,所以我们考虑 1024 元素批处理结果,其中显而易见的是, A100 GPU 具有令人难以置信的性能,每秒处理大约 50000 个样本。此外,更大的批量往往会导致更高的延迟,从 CPU 值可以明显看出,这似乎与批量成正比。相比之下,与 CPU 相比, A100 GPU 具有接近恒定的平均延迟。
端到端示例
结合前面的例子,我们演示了 TFT 模型在电力数据集上的简单训练和部署。我们首先从源代码构建并启动 TSPP 容器:
cd DeeplearningExamples/Tools/PyTorch/TimeSeriesPredictionPlatform source scripts/setup.sh docker build -t tspp . docker run -it --gpus all --ipc=host --network=host -v /your/datasets/:/workspace/datasets/ tspp bash
接下来,我们使用电力数据集 TFT 和分位数损耗启动 TSPP 。我们还让 10 年的历次训练负担过重。一旦对模型进行了培训,就会在 outputs /{ date }/{ time }中创建日志、配置文件和经过培训的检查点,在本例中为 outputs / 01-02-2022 /:
Python launch_tspp.py dataset=electricity model=tft criterion=quantile config.trainer.num_epochs=10
使用检查点目录,可以将模型转换为 NVIDIA TensorRT 格式,并部署到 NVIDIA Triton 推理服务器。
Python launch_deployment.py export=onnx convert=trt config.evaluator.checkpoint=/path/to/checkpoint/folder/
可利用性
NVIDIA 时间序列预测平台提供从训练到时间序列模型的推断的端到端 GPU 加速。平台中包含的参考示例经过优化和认证,可在 NVIDIA DGX A100 和 NVIDIA 认证系统上运行。要更深入地了解所取得的成绩,请参阅我们的 时间融合 transformer 基准 .
组织可以开始培训,将模型体系结构与自己的数据集进行比较,并在今日生产中部署模型。