从单调乏味的高速公路到日常的社区出行,驾驶通常都很平静。因此,在现实世界中收集的大部分自动驾驶汽车 (AV) 开发训练数据严重倾斜于简单的场景。
这给部署稳健的感知模型带来了挑战。AV 必须经过全面的训练、测试和验证,才能处理复杂的情况,而这需要涵盖此类情况的大量数据。
模拟为在现实世界中查找和收集此类数据提供了一种替代方案,而这需要非常耗时和成本。然而,大规模生成复杂的动态场景仍然是一个重大障碍。
在最近发表的一篇论文中,NVIDIA Research 展示了一种新的基于神经辐射场(NeRF)的方法(称为 EmerNeRF),它如何使用自监督学习准确生成动态场景。通过自监督进行训练,EmerNeRF 不仅在处理动态对象时优于其他基于 NeRF 的方法,而且在处理静态场景时也表现出色。有关更多详情,请参阅 EmerNeRF:通过自监督对紧急时空场景进行分解。



在与类似的 NeRF 一起运行 EmerNeRF 时,它将动态场景重建准确率提高 15%,静态场景提高 11%,此外,新颖的视图合成也提高了 12%.
解决基于 NeRF 的方法中的限制
NeRF 可接收一组静态图像,并将其重建为逼真的 3D 场景。它们可以通过驱动日志创建高保真模拟,以进行闭环深度神经网络 (DNN) 训练、测试和验证。
然而,当前基于 NeRF 的重建方法难以处理动态对象,并且已证明难以扩展。例如,虽然一些方法可以生成静态和动态场景,但它们需要真值 (GT) 标签才能生成。这意味着,必须使用自动标记技术或人工标注器准确概述和定义驾驶日志中的每个对象。
其他 NeRF 方法依赖于其他模型来获得有关场景的完整信息,例如光流。
为了解决这些限制,EmerNeRF 使用自监督学习将场景分解为静态、动态和流场。模型从原始数据中学习关联和结构,而不是依赖人类标记的 GT 注释。然后,它同时渲染场景的时间和空间方面,无需外部模型填补空白,同时提高准确性。

因此,虽然其他模型往往会生成过于平滑的渲染和精度较低的动态对象,但 EmerNeRF 可以重建高保真背景场景和动态对象,同时保留场景的精细细节。
| Dynamic-32 分割 | ||||||||
| 场景重建 | 新型视图合成 | |||||||
| 方法 | 完整图像 | 仅动态 | 完整图像 | 仅动态 | ||||
| PSNR* | SSIM* | PSNR* | SSIM* | PSNR* | SSIM* | DPSNR* | SSIM* | |
| D2NeRF | 24.35 | 0.645 | 21.78 | 0.504 | 2417 | 0.642 | 21.44 | 0.494 |
| HyperNeRF | 2517 | 0.688 | 22.93 | 0.569 | 24.71 | 0.682 | 22.43 | 0.554 |
| EmerNeRF | 28.87 | 0.814 | 26.19 | 0.736 | 27.62 | 0.792 | 24.18 | 0.67 |
| Static-32 拆分 | ||
| 方法 | 静态场景重建 | |
| PSNR* | SSIM* | |
| iNGP | 24.46 | 0.694 |
| 街头冲浪 | 26.15 | 0.753 |
| EmerNeRF | 29.08 | 0.803 |
EmerNeRF 方法
使用自监督学习,而非人工标注或外部模型,使 EmerNeRF 能够绕过之前方法遇到的挑战。
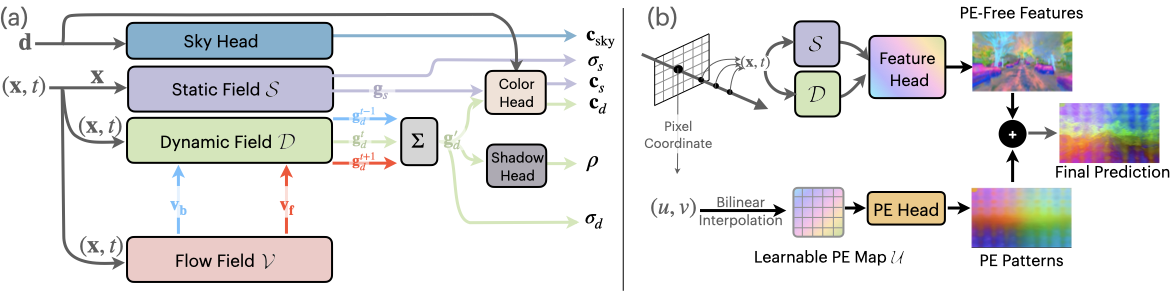
EmerNeRF 旨在将场景分解为动态元素和静态元素。在分解场景时,EmerNeRF 还可以从动态物体(如汽车和行人)中估计流场,并使用此字段通过跨时间聚合特征来进一步提高重建质量。其他方法使用外部模型提供此类光流数据,这通常会导致不准确。
通过同时组合静态、动态和流场,EmerNeRF 可以独立表示高度动态的场景,从而提高准确性并支持扩展到通用数据源。
使用基础模型添加语义理解
使用基础模型进行额外监督,EmerNeRF 对场景的语义理解得到了进一步加强。基础模型对物体(例如特定类型的车辆或动物)有广泛的了解。EmerNeRF 利用视觉转换器 (ViT) 模型(例如 DINO 和 DINOv2)将语义特征纳入场景重建。
这使得 EmerNeRF 能够更好地预测场景中的物体,并执行自动标记等下游任务。

然而,基于 Transformer 的基础模型带来了新的挑战:语义特征可能会表现出与位置相关的噪声,这可能会显著限制下游任务的性能。

为了解决噪声问题,EmerNeRF 使用位置嵌入分解来恢复无噪点特征图。这解锁了基础模型语义特征的完整、准确表示,如图 5 所示。
评估 EmerNeRF
详情见EmerNeRF:通过自监督对紧急时空场景进行分解。此外,我们通过整理一个包含 120 个独特场景的数据集来评估 EmerNeRF 的性能,这些场景被分为 32 个静态场景、32 个动态场景和 56 个不同场景,它们适用于高速和低光照等具有挑战性的条件。
然后,评估每个 NeRF 模型基于数据集的不同子集重建场景和合成新视图的能力。
因此,我们发现 EmerNeRF 在场景重建和新视图合成方面的表现始终如一,并且明显优于其他方法,如表 1 所示。
EmerNeRF 的表现也优于专为静态场景设计的方法,这表明将场景分解为静态和动态元素的自监督式分析可改善静态重建和动态重建。
结束语
只有能够准确再现现实世界,AV 模拟才会有效。随着场景变得更加动态和复杂,对保真度的需求也在增加,实现这一目标的难度也在增加。
与之前的方法相比,EmerNeRF 能够更准确地表示和重建动态场景,无需人工监督或外部模型。这使得能够大规模重建和修改复杂的驾驶数据,解决自动驾驶训练数据集中的当前不平衡问题。
我们迫切希望研究 EmerNeRF 释放的新功能,包括端到端驾驶、自动标记和模拟。
如需了解详情,请访问 EmerNeRF 项目页面 并阅读论文 EmerNeRF:通过自监督对紧急时空场景进行分解。