
随着数据集规模的不断扩大,采用 Amazon S3 和谷歌云存储( GCS )等云存储平台变得越来越流行。尽管节点本地存储可能会带来更好的 IO 性能,但在数据集超过单 TB 规模后,这种方法可能变得不切实际。
在远程存储是唯一实用的解决方案的情况下, PyData 生态系统的许多部分已经采用文件系统规范(fsspec)作为通用文件系统 API 。自从s3fs和gcsfs推出以来,fsspec已经为用户提供了足够的远程存储访问权限,但内部字节传输和缓存算法还没有对拼花等高性能文件格式进行特定于格式的优化。
关键教训
在本文中,我们将介绍fsspec.parquet模块,它为远程拼花文件提供了一种支持格式的字节缓存优化。这个模块是实验性的,并且仅限于一个公共 API :open_parquet_file。
此 API 提供了更快的远程文件访问。与 cuDF 和 cuDF 数据帧库中的默认read_parquet行为相比,对于大型拼花地板文件的部分 I / O (列块和行组选择),整体吞吐量有了一致的性能提升。
我们还讨论了这个新模块中使用的优化,并给出了初步的性能结果。
什么是 fsspec ?
文件系统规范(fsspec)是一个开源项目,为各种后端存储系统提供统一的 Python 接口。fsspec对应于一个特定的fsspec Python 库和一个更大的 GitHub 组织,其中包含许多特定于系统的存储库(例如s3fs和gcsfs)。
在基于 Python 的库或应用程序中使用fsspec的优点是,类似于 POSIX 的文件 API 可以从远程对象和本地文件进行读写。当一个基于云的对象被一个fsspec兼容的文件系统打开时,底层应用程序会得到一个AbstractBufferedFile对象,或者其他一些类似文件的对象,这些对象被设计为使用原生 Python 文件对象进行 duck type 操作。现在,这些类似文件的对象可以像本地 Python 文件句柄一样处理。
一个明显的区别是AbstractBufferedFile对象必须在内部使用特定于文件系统的命令,以便向远程存储系统输入和从远程存储系统获取字节。由于内部数据传输操作的延迟通常高于本地磁盘访问,fsspec提供了几种缓存策略来预取数据,同时避免了许多小请求。
在这篇文章的后面,我们将解释为什么对于大型拼花地板文件,默认缓存策略通常不太理想,以及新的KnownPartsOfAFile(“部件”)选项如何显著减少读取延迟。
什么是拼花地板?
Parquet 是一种面向二进制列的数据存储格式,设计时考虑了性能、压缩和部分 I / O 。由于与 CSV 等文本格式文件相比具有显著的性能优势,自 2013 年首次发布以来,开源格式的受欢迎程度迅速增长。
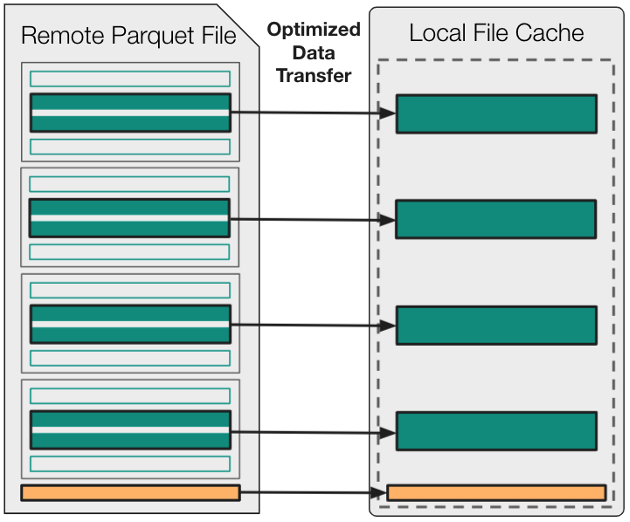
为了理解 Fsspec 拼花地板模块中使用的优化,对拼花地板规范有一个高层次的理解是很有用的。图 1 显示,所有拼花文件都由一组连续存储的行组组成,而这些行组中的每一个都包括一组连续存储的列块。
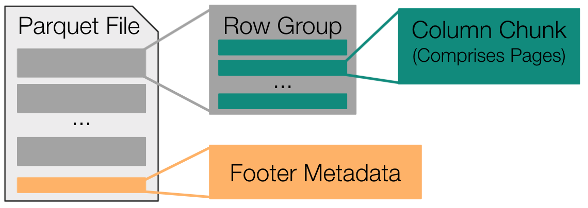
总之,拼花地板文件中的大部分字节都对应于这些列块。剩余的字节用于将文件元数据存储在旧格式的页脚中。此页脚元数据包括文件中每个列块的字节偏移量和可选统计信息(min、max、valid count、null count)。
由于这些重要信息整合在页脚中,因此只需对拼花地板文件的结尾进行采样,即可确定文件中每个列块的具体位置。
fsspec 新拼花模块的用途是什么?
fsspec已经是 Python 下加载拼花地板文件的最常用方法。新fsspec.parquet模块的主要目的是为这项任务提供优化的实用程序。
在内部,这个新的实用程序(open_parquet_file)基本上将一个传统的开放调用封装在特定于拼花地板的逻辑中,该逻辑设计用于在用户启动显式读取操作之前,开始将所有相关数据从远程文件传输到本地内存。
尽管任何大小的读取都可能受益于此新实用程序,但当读取操作仅针对所有列和行组的子集时,可以看到最显著的改进。例如,当远程读取使用列投影时,相同的列列表可以直接传递给open_parquet_file:
from fsspec.parquet import open_parquet_file
import pandas as pd path = “<protocol>://my-bucket/my-data”
columns = [“col1”, “col2”]
options = {“necessary”: ”credentials”} with open_parquet_file( path, columns=columns, storage_options=options,
) as f: df = pd.read_parquet(path, columns=columns)
如前所述,fsspec新open_parquet_file函数的主要目的是通过在AbstractBufferedFile.open中使用支持格式的缓存策略,提高大型拼花地板文件的读取性能。
要理解拼花地板模块使用的特定优化为什么是有益的,首先了解简单的无缓存方法以及默认的预读策略是有帮助的。
了解无缓存和预读方法
图 2 显示了对于 naive 和 naive 读调用序列,无缓存文件访问可能如何映射到read_parquet操作中的远程 get 调用(在远程文件已经打开之后)。
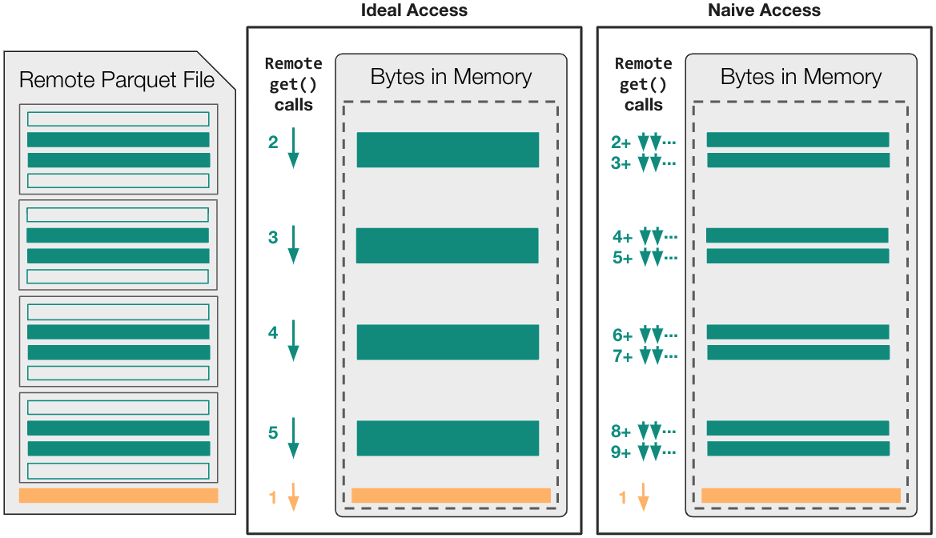
在这个特定的示例中,假设拼花文件足够大(~ 400MB +)以包含四个不同的行组,read_parquet调用的目标是四个可用列中的两个。这意味着AbstractBufferedFile对象最终必须将八个不同的列块范围以及页脚元数据传输到本地内存中。
在禁用缓存的情况下,经过良好调整的拼花地板库可以使用五个不同的请求仅将必要的数据移动到本地内存中。然而,由于fsspec的类文件接口包含state,这五个读取调用始终是串行的,每次调用都会产生一整段延迟时间。
这种 ideal-access 场景无法利用并发性来最小化延迟,即使该策略可能会最小化文件系统请求的数量并产生高的总体吞吐量。对于采用 naive-access 方法且未明确最小化读取调用数的拼花地板库,read_parquet操作可能会出现高延迟和低总体吞吐量!
此时,我们已经确定,在文件已经打开进行读取之后, I / O 库无法利用文件系统的并发性。更重要的是,当涉及部分 I / O 时,默认的预读缓存策略可能会进一步降低观察到的性能。这是因为预读缓存的固有假设是,顺序文件访问可能是连续的。
Figure 3 shows that read-ahead caching is likely to transfer about 20 MB of unnecessary data, 5 MB of read-ahead for each row-group.
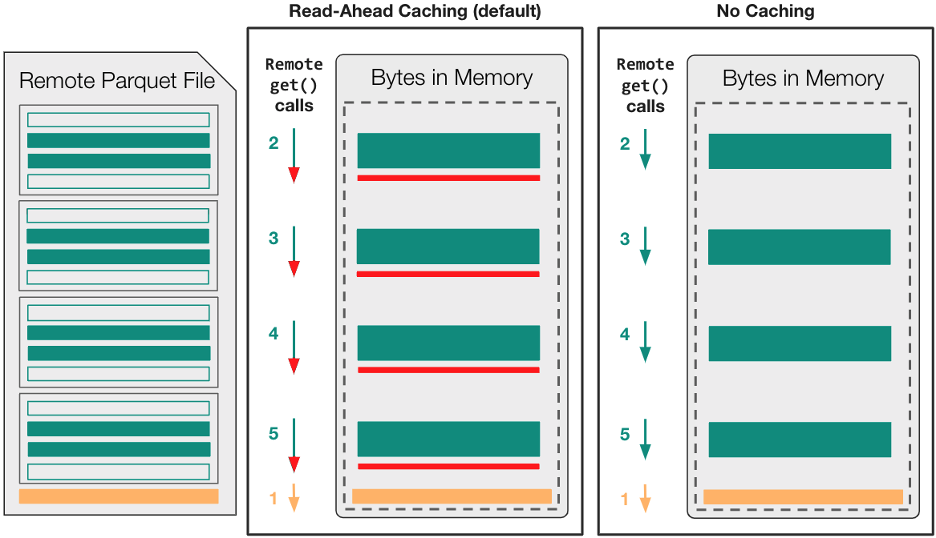
正如您在以下性能结果中看到的,禁用缓存优于预读缓存的好处取决于read_parquet中使用的引擎和特定的存储系统。
如果引擎已经包含了支持格式的优化,可以将必要的字节范围移动到本地内存中(即pyarrow和fastparquet),那么无缓存选项可能是更好的选择。当引擎假定本地文件访问速度很快( cuDF )时,某种形式的fsspec级缓存可能非常关键。
在这两种情况下,引擎都无法开始传输所需的字节范围,直到创建fsspec文件对象之后。它受到顺序数据传输附加延迟的限制。
现在,我们已经对典型的 read _ parquet 调用中的默认和无缓存 AbstractBufferedFile 行为有了较高的理解,现在我们可以解释open_parquet_file为提高总体读取吞吐量而使用的两种通用优化。
优化 1 :使用“部件”缓存策略
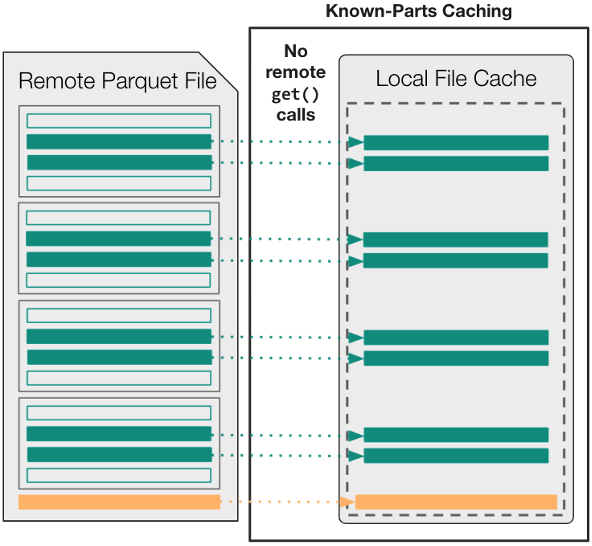
默认情况下,与AbstractBufferedFile中使用的格式无关的缓存策略不同,您可以使用新的KnownPartsOfAFile(“部件”)选项在文件打开之前精确缓存所需内容。
In other words, begin by using an external Parquet engine (either fastparquet or pyarrow) to parse the footer metadata up-front. Then, transfer the necessary byte-ranges into local memory, and use the parts’ cache to ensure that downstream applications never have to wait for remote data after an open fsspec file object is acquired.
图 4 显示,用于访问read_parquet中数据的逻辑与用于远程数据访问的get调用的数量或大小之间不再存在任何关系。从拼花引擎的角度来看,任何读取操作几乎都是瞬时的,因为所有必需的数据都已缓存在内存中。
优化 2 :异步并行传输“部件”
尽管之前的优化使您能够避免read_parquet中的许多小型 get 操作和不必要的数据传输,但在初始化AbstractBufferedFile之前,您仍然必须填充KnownPArtsOfAFile缓存。
为了尽可能高效地执行此操作,请使用cat_ranges一次性获取所有必需的列块,包括异步获取和使用asyncio并行获取。因为对于包含多个字段或多个行组的文件,传输的列块的总数可能很大,所以只要聚合的请求的大小保持在上限以下,就可以聚合相邻的字节范围请求。
图 5 显示,这种方法最终会导致并发传输多个字节范围的最佳大小。
初步 fsspec 。拼花地板基准测试结果
要将open_parquet_file的性能与其他基于fsspec和pyarrow的文件处理方法进行比较,请使用 可用 Python 脚本 :
pyarrow-6.0.1fastparquet-0.8.0cudf-22.04fsspec/s3fs/gcfs-2022.2.0
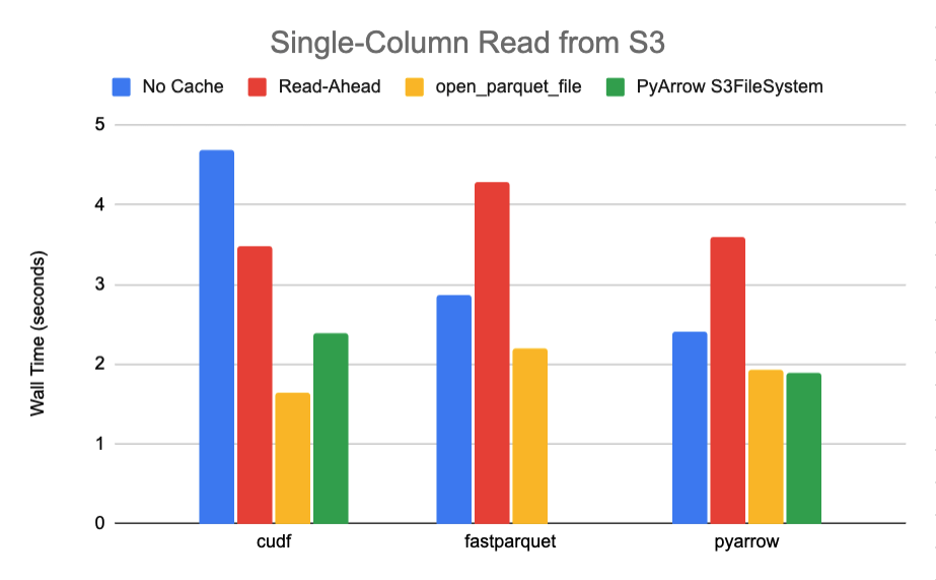
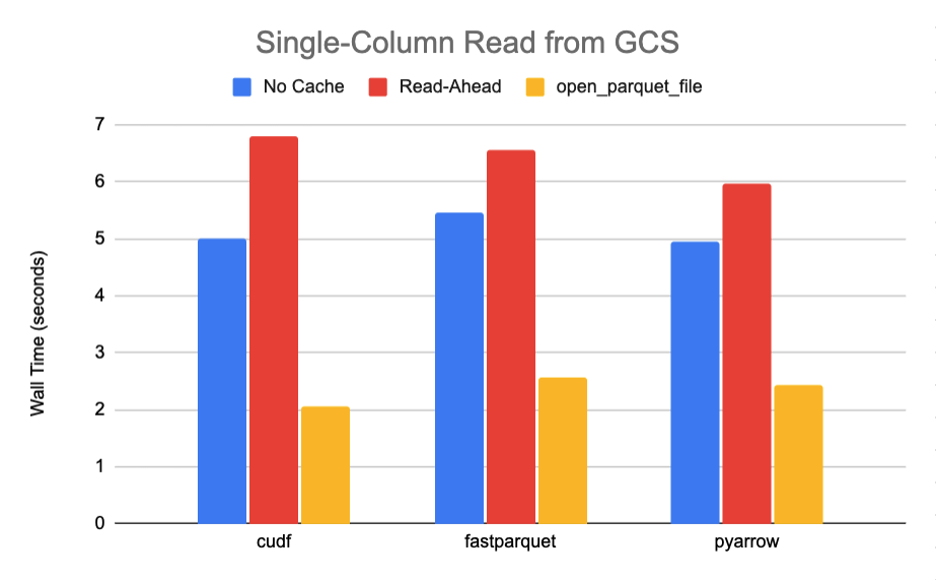
使用这个脚本,我们从一个 789M 的拼花地板文件中读取一列,该文件共包含 10 个行组和 30 个列,具有快速压缩,需要传输大约 27M 的数据。图 6-7 中总结的 S3 和 GCS 的结果清楚地表明,当从默认缓存策略转向open_parquet_file时,性能显著提升 85% 或更高。
事实上,新功能有效地匹配了 PyArrow 的原生S3FileSystem实现的性能,该实现是专门为其镶木地板引擎的最佳性能而设计的。在本文中,我们仅将其与 Amazon S3 基准测试的本机 PyArrow 文件系统进行比较,因为 PyArrow 在发布时仅提供 Amazon S3 和 Hadoop 的公共支持实现。
为了说明使用open_parquet_file缩放文件的好处,我们还从一个 12 GB 的拼花地板文件中读取了一列,其中包含禁用压缩的公共 GCS 存储中 Criteo 数据集的第一天。图 8 显示,新的fsspec函数可以提供比默认缓存 10 倍或更多的加速。

自己测试一下
在本文中,我们介绍了fsspec.parquet模块,它为打开远程拼花文件open_parquet_file提供了一种支持格式的字节缓存优化。基准测试清楚地表明,与fsspec中的默认文件打开行为相比,新的优化可以提供显著的性能改进,甚至可以接近 PyArrow 中针对部分 I / O 的优化 C ++文件系统实现的性能。
自从在 2021.11.0 版本的 fsspec 中正式发布以来,open_parquet_file实用程序已经被 RAPIDS cuDF 库和 Dask -Dataframe 采用。
由于基于 cuDF 的工作流得到了显著且一致的改进,此新功能已被cudf.read_parquet和dask_cudf.read_parquet采用为默认的文件打开方法。
对于没有 GPU 资源的 Dask 用户,现在可以通过向read_parquet传递open_file_options参数来选择优化的缓存方法。例如,以下代码示例指示 Dask 使用parquet预缓存方法打开所有拼花地板数据文件:
import dask.dataframe as dd ddf = dd.read_parquet( path, open_file_options={“precache_options”: {“method”: “parquet”}}
)鉴于这一早期的成功,我们希望扩展和简化fsspec中可用的预缓存选项,并在所有文件打开函数中建立一个清晰的 precache_options API 。
这里的社区反馈至关重要。请访问 GitHub 或在下面发表评论,并让我们知道您的想法!




