由于 深度学习 的进步和矢量嵌入的使用,推荐模型近年来进展迅速。这些模型日益复杂,需要强大的系统来支持它们,在生产中部署和维护这些模型可能具有挑战性。
在论文 Monolith: Real Time Recommendation System With Collisionless Embedding Table 中,字节跳动详细介绍了他们如何构建一个推荐系统,以支持在线培训、滚动嵌入更新、容错等。
这篇文章详细介绍了离线、在线和在线大型推荐系统架构。我们专注于部署,使用构建块框架 NVIDIA Merlin 和实时数据层 Redis 构建端到端推荐系统的示例。最后,我们提供了云部署说明和管理的 Redis 选项,用于生产就绪和简化架构。
下载 RedisVentures/Redis-Recsys GitHub 存储库中的代码,并查看相关资产以遵循每个示例。提供了 Terraform 脚本和可解释的剧本,以帮助在 Amazon Web 服务上部署此基础设施。
请参加 GTC 2023 ,参加我们即将举行的演讲 Optimizing Data Systems for NVIDIA Merlin and NVIDIA Triton ,以获得有关优化推荐系统以降低延迟的提示。
推荐系统架构
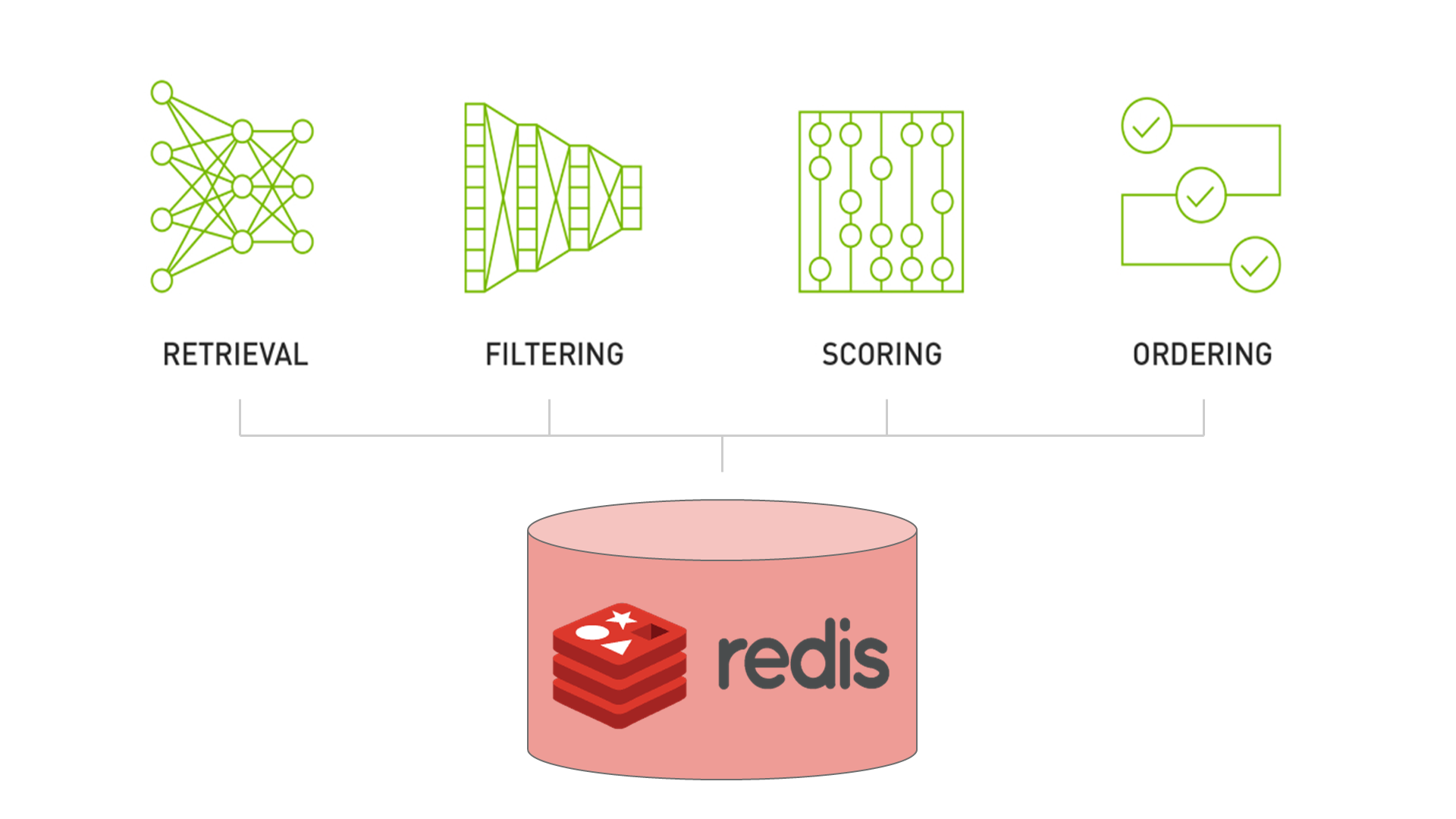
NVIDIA Merlin 推荐系统依赖于 Recommender Systems, Not Just Recommender Models 中讨论的四阶段模式:
- 检索包含用户最终将参与的项目的合理相关集合。
- 过滤模型几乎不可能强制执行的不需要的项目。
- 对用户可能对一组项目产生的兴趣进行评分(或排名)。
- 对项目进行排序,使模型的输出与业务的其他需求或约束保持一致。
这四个阶段的检索、过滤、评分和排序构成了一个设计模式,涵盖了大多数推荐系统在生产中的外观(图 1 )。对于这篇文章,我们使用 scoring 和 ranking 同义。我们只关注检索和评分阶段,因为它们是推荐系统的计算密集型阶段。
检索阶段
retrieval 过程通常很快,但粒度较粗。从大量潜在候选人中选择相关子集。在这一步骤中,效率高于精度。
在现代检索系统中,通过将所有潜在项目传递给深度学习模型,将候选目录转化为密集嵌入。当使用 RediSearch 或 FAISS 进行索引时,可以比较数百万个嵌入,并且可以在低延迟下检索最相似的候选嵌入。
排名阶段
在 ranking 工艺中,精度比效率更受青睐。因此,排名模型通常比检索阶段更复杂。由于深度学习的进步,排名阶段可以包含比以前更多的数据。
Meta 生产的深度学习推荐模型( DLRM )等模型用于排名阶段,可以学习对给定用户的数百万候选人进行排名。然而,输入仅限于几千个候选项。
大规模排名系统通常应用两个或多个子阶段,即粗略排名和精细排名或重新排名,以利用更复杂的方法或注入额外的信息来影响最终结果。结合起来,随着计算成本的增加,他们进一步缩小了候选人数。
有关推荐系统体系结构的更多信息,请参见 System Design for Recommendations and Search 。本文介绍了一些顶级公司部署的示例。
虽然我们使用术语 offline 来指代整个推荐系统的部署架构,但 Eugene Yan 将 offline 称为模型训练阶段。
离线推荐系统
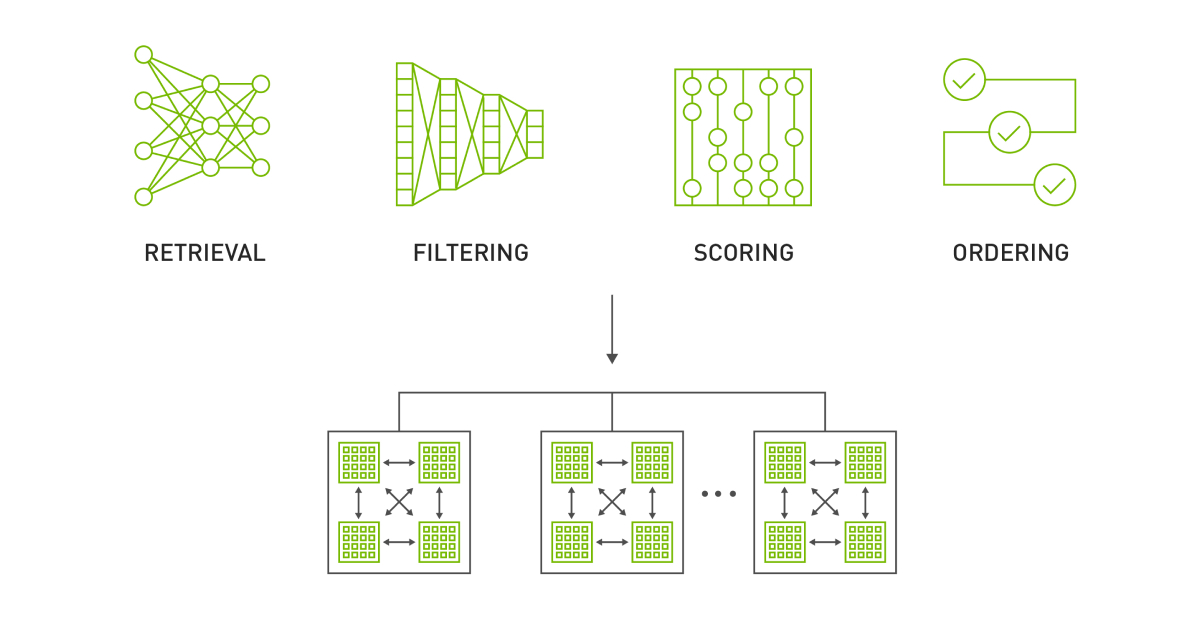
Offline recommendation systems 使用批处理计算来处理大型数据集并存储建议以供以后检索。
批量计算对于那些负担不起托管实时多阶段推荐系统的复杂性或必须快速启动和运行的开发人员来说尤其有用。这些系统非常适合于业务目标,这些业务目标只能在一定时间间隔内刷新,但需要高精度,因此需要额外的计算时间。示例包括定期新闻通讯或电子邮件活动。
图 2 显示了 Redis 纯粹用于推荐存储和检索的离线体系结构。笔记本 Offline Batch Recommender System 演示了如何为 Alibaba Click and Conversion Prediction dataset 创建这样的系统。
检索:双塔
候选检索模型是双塔神经网络结构。 user tower 为用户偏好建模,而 item tower 为项目特性建模。
笔记本示例在训练期间使用负抽样。该模型使用隐式反馈 , ,例如用户交互或点击,而不是使用显式反馈,例如用户评分或分数。经过训练的嵌入用于将整个项目目录缩小到给定用户最可能与之交互的项目目录。嵌入还可以用于其他电子商务用例中的项目或用户用户相似性,例如基于内容的推荐或客户细分。
等级: DLRM
排名模型是推荐系统中常用的一种 机器学习 模型,用于基于用户交互的相关性或可能性对项目进行排名。这些模型可以通过考虑用户偏好和过去的交互(如点击、购买或评分)来生成个性化推荐。
Jupyter 笔记本示例使用 DLRM ,这是一种混合模型架构,可对用户项对进行评分和排序。有关 DLRM 体系结构的更多信息,请参阅 Exporting Ranking Models 笔记本。
生成和提供建议
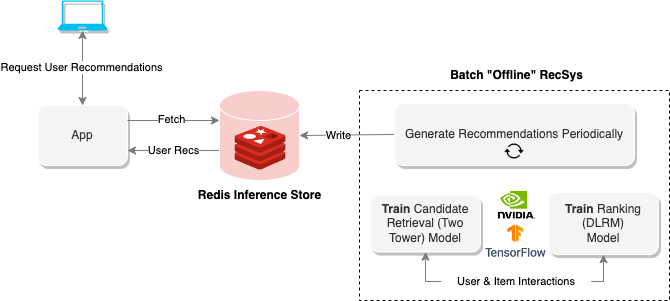
推荐系统的最后一部分是在低延迟数据层中托管生成的推荐。关键价值存储(如 Redis )使您能够接近实时地访问推荐,而无需为在线推荐系统托管基础设施。
下一节将解释如何使用刚才描述的管道并部署实时服务层以在线生成建议。
在线推荐系统
在线推荐系统按需生成推荐。与面向批处理的系统不同,可扩展性和端到端延迟(通常< 100-300ms )通常是最重要的因素。
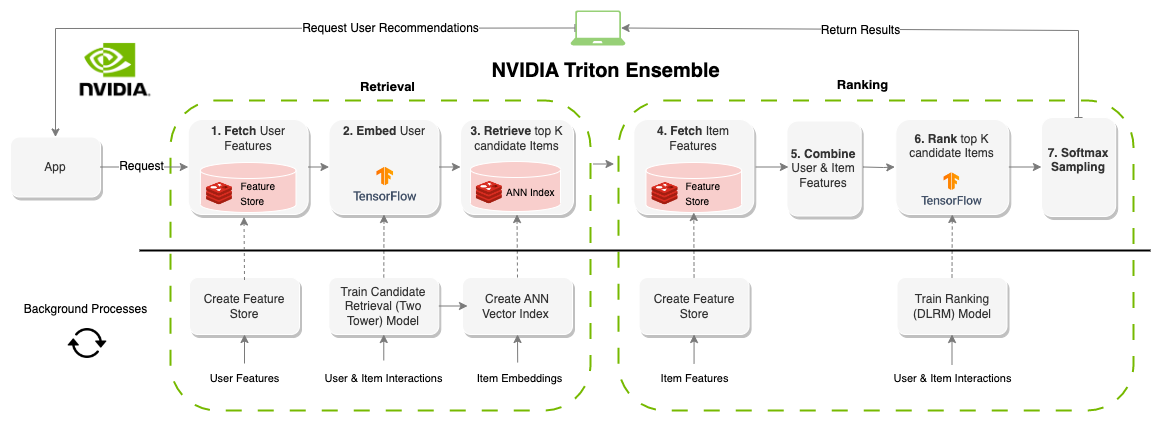
本节介绍了构建具有功能存储( Redis )、编排( Feast )、矢量数据库和搜索( Redi )以及推理( NVIDIA Triton )的在线推荐系统所需的基础设施。
然后,我们介绍了一个 set of notebooks ,它概述了如何使用 NVIDIA Triton 推理服务器 ensemble 功能将这个基础设施联系在一起。
功能存储
两种广泛部署的 feature stores 与推荐系统的二分法非常相似,分别是离线和在线商店。
脱机功能存储
offline feature store 通常是一个持久的、基于磁盘的数据库,具有大容量(> 10 TB )。所有模型功能,包括历史功能,都保存在离线商店中。像 Apache Spark 这样的批处理框架通常用于以指定的间隔将功能从离线商店具体化到在线功能商店。例如, Spark-Redis 经常用于将功能加载到 Redis 。
在线功能商店
Online feature stores 权衡容量以减少延迟,通常将功能保留在内存中。一部分功能从离线商店具体化到在线商店中,这样“最新鲜”的功能就可以保留下来。在线商店在服务管道中被直接查询,以提供具有丰富特征向量的机器学习模型用于推断。
在第二个示例中, Redis 被用作在线功能商店,用户和项目功能从拼花文件(离线商店)中具体化。 Feast 是一个功能编排框架,用于在运行时定义功能、配置具体化和查询模型功能。
服务嵌入
在离线示例中,使用双塔模型将用户和项目编码为嵌入。然而,对于在线服务,仅通过使用用户塔并部署矢量数据库来托管和搜索项目嵌入,可以减少系统的总体延迟。
除了减少延迟外,矢量数据库还可以在不中断查询服务的情况下更新嵌入。脱机笔记本将创建的项目嵌入保存到文件中,以便联机笔记本可以演示如何设置此系统。
Redis 除了用作在线功能商店外,还用作 RediSearch 模块的近似最近邻居 index of the item embeddings 。 RediSearch 在 2.4 版中增加了对向量索引的支持。
笔记本 Building Online Multi-Stage Recsys Components 展示了如何设置 Feast 和 Redis 以进行特征存储和向量嵌入搜索。
提供实时建议
NVIDIA Triton 是一款 inference serving platform ,具有 number of backends 以支持不同的型号和管道。集成后端允许您定义在有向非循环图( DAG )中运行的多个步骤。设置 Feast 和 Redis 后,您可以定义一个 NVIDIA Triton 集成(图 3 ),该集成在给定user_id值的情况下按需执行推荐系统管道。
Deploying Online Multi-Stage RecSys with Triton Inference Server 笔记本显示了如何定义 NVIDIA Triton 集成,并提供了如何使用 NVIDIA Triton Python 客户端查询该集成的示例。
设计注意事项
尽管该系统支持实时推荐,但仍有一些设计考虑因素需要考虑。
首先,用户功能必须定期从离线功能商店发布到在线功能商店。例如,在电子商务网站上执行操作的用户可能会看到静态推荐,除非功能物化足够频繁。但是,如果执行得太频繁,对 Redis 的写入次数会降低读取吞吐量,并降低服务管道的速度。找到平衡是关键。
其次,必须监控训练模型的特征漂移。随着特征从训练集所包含的内容更新,模型性能可能会随着时间的推移而改变。为了保持性能,模型应经过重新培训并随时间更新。此外,在更新模型时,应更新向量索引中存储的嵌入。使用 Redis ,可以直接对索引进行增量向量更新,也可以在后台创建新的向量索引,并使用 FT.ALIASADD 命令进行交换。
在线、大规模
大型企业通常拥有数百万用户和项目。模型的整个嵌入表可能不适合单个 GPU 。
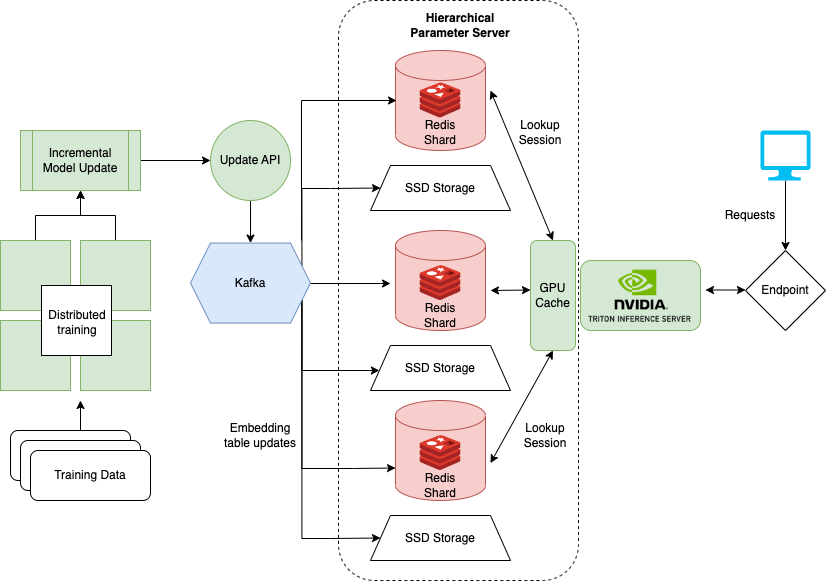
为此, NVIDIA Merlin 创建了 HugeCTR 后端,该后端支持分布式培训、更新和推荐模型服务
笔记本 Large-Scale Recommender Models 专注于 HugeCTR 部署,并提供了可用于示例的 DLRM 的预训练版本。有关 HugeCTR 分布式培训的更多信息,请参见 Scaling Recommendation System Inference with Merlin Hierarchical Parameter Server 。
与 HugeCTR 一起服务
参考笔记本中部署的 DLRM 模型与上一节中的排名模型在线推荐系统相同。本节将进一步探讨排名阶段,以描述 HugeCTR 如何实现多级推荐系统排名阶段所需的能力水平。
HugeCTR 使排名模型成为可能,该模型可以解释数百万用户项交互,从而创建精确但计算成本高昂的模型。如上所述,排名阶段通常比检索更慢、更精确,通常占分配给给定用例的可用时间预算的很大一部分。
分级参数服务器
HugeCTR 通过使用分层参数服务器( HPS )在多个服务器上分发嵌入,如图 4 所示。 HPS 是一个分层存储系统,它在三个不同的位置缓存嵌入内容,逐渐以速度换取容量。
GPU 缓存层
GPU 缓存保存最频繁访问的嵌入,这些嵌入最接近于它们将用于推断的位置。由于 GPU 上已有嵌入,因此在推断时数据移动延迟会减少。通常,嵌入的访问模式模仿幂律,通过用尽可能多的嵌入填充 GPU 缓存来获得最大的好处。
CPU 存储层
CPU 存储层的容量大于 GPU 缓存。然而,在推断之前,数据必须移动到 GPU ,并且在推断时访问速度较慢。 HPS 中的 CPU 内存层实现了多种方法,例如分布式哈希映射。笔记本示例使用 Redis 在内存中缓存嵌入。 HugeCTR 完全支持 Redis 集群在服务器之间分配嵌入表内存。
SSD 层
SSD 层是 HPS 中最大和最慢的层。整个嵌入表保存在 SSD 层中。该层保证了分布式嵌入表在发生故障时不会丢失,因为每个服务器都包含所有模型的一整套嵌入表。
滚动更新
更新嵌入是托管在线推荐系统的必要部分。在在线推荐系统示例中,我们依靠 Redis 功能在后台进行更新。然而,更新没有解决训练的 DLRM 模型所使用的嵌入表。
相反,必须更新模型以避免特性和模型漂移问题。通过将新版本的 DLRM 上载到 NVIDIA Triton ,可以实现更新。然而,大型模型(如使用 HugeCTR 框架训练的模型)不容易更新,因为它们的总大小可达 TB 。
为了解决大规模模型, NVIDIA 使用 Kafka 实现了一个滚动更新系统,该系统将更新的嵌入作为 Kafka 管道中的消息发送到运行 HugeCTR 后端的 NVIDIA Triton 服务器。因此, DLRM 模型的在线训练可以与发球同时进行。这种在线的大规模架构与 Monolith: Real-Time Recommendation System with Collisionless Embedding Table 中讨论的架构非常相似。
基于云的部署
随附的笔记本提供了如何配置和部署 NVIDIA Triton 以及 HugeCTR 后端和 HPS 以及 Docker (本地)和 AWS 上的 Terraform (云)的示例。然而,在某些情况下,自行管理 HPS 基础设施的部署可能不太理想。
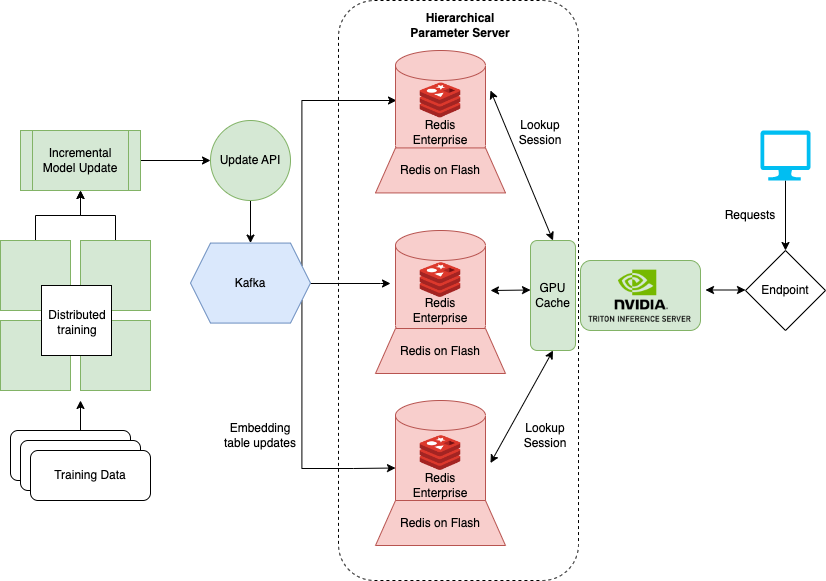
有许多 Redis 提供商推出并管理大规模运行 HPS 所需的大部分基础设施。一个选项 Redis Enterprise 提供了部署在云中的 Redis 的托管版本,并简化了 HPS 的基础架构。
在图 5 中,基于 RocksDB 的 SSD 层被 Redis Enterprise flash capability ( RoF )所取代。使用 RoF ,您可以直接在 Redis 中调整 SSD 和闪存之间的比率,而无需在 NVIDIA Triton 中重新部署 HugeCTR 型号。这在调整交通高峰和低谷时是有益的。
对于现有的 RocksDB 层,每个模型的嵌入表都存储在每个推理节点上,以提高系统可用性。这样,在发生灾难性事件时,可以恢复模型参数和推理服务,前提是至少有一个计算实例处于活动状态。相反, RoF 通过跨 Redis 数据库的碎片分发复制来降低总体 HPS 存储需求。
Redis Enterprise 通过进一步切分数据库,为故障切换时间、可用性( 99.999% )、 active-active geo distribution 和可扩展 IOPS 提供 SLA 。用于更新嵌入的 Kafka 消息的订阅者数量也减少到单个端点。提供了这种体系结构,整个服务器变得更简单、更易于维护。
RedisVentures/Redis-Recsys GitHub 存储库提供 Terraform scripts and Ansible playbooks 在 AWS 上启动此基础设施。
总结
本文描述了使用 NVIDIA Merlin 框架创建推荐系统的三种不同用例,其中 Redis 是实时数据层。每个用例都提供了低延迟解决方案,即使在数据扩展时,尤其是对于计算复杂的应用程序。
在 GTC 即将举行的演讲 Optimizing Data Systems for NVIDIA Merlin and NVIDIA Triton 中,将讨论提高推荐系统整体性能的方法。有关这些用例的更多信息,请联系 sam.partee@redis.com 或在 Twitter 上关注我 @sampartee 。




