大语言模型(LLM)提供异常强大的新功能,拓展了 AI 的应用领域。但由于其庞大的规模和独特的执行特性,很难找到经济高效的使用方式。
NVIDIA 一直在与 Meta、Anyscale、Cohere、Deci、Grammarly、Mistral AI、MosaicML(现已并入 Databricks)、OctoML、ServiceNow、Tabnine、Together AI 和 Uber 等头部企业密切合作,共同加速和优化 LLM 推理性能。
这些创新已被集成到开源的 NVIDIA TensorRT-LLM 软件中,可用于 Ampere、Lovelace 和 Hopper 架构 GPU,并将在未来几周内发布。TensorRT-LLM 包含 TensorRT 深度学习编译器,并且带有经过优化的内核、前处理和后处理步骤,以及多 GPU/多节点通信原语,可在 NVIDIA GPU 上提供出类拔萃的性能。它使开发人员能够尝试新的 LLM,提供最顶尖的性能和快速自定义功能,而且不需要开发人员具备深厚的 C++ 或 NVIDIA CUDA 知识。
TensorRT-LLM 通过一个开源的模块化 Python 应用编程接口(API)提高易用性和可扩展性,可随 LLM 的发展定义、优化和执行新的架构和增强功能,并且可以轻松地进行自定义。
例如,MosaicML 在 TensorRT-LLM 的基础上无缝添加了所需的特定功能,并将这些功能集成到推理服务中。Databricks 工程副总裁 Naveen Rao 就曾提到:“这已成为相当轻而易举的事情。”
Rao 表示:“TensorRT-LLM 简单易用,具有通证传输、in-flight 批处理、分页关注、量化等丰富功能,而且效率很高。它为使用 NVIDIA GPU 的 LLM 服务提供了领先的性能,并使我们能够将节省的成本回馈给我们的客户。”
性能比较
文章摘要仅仅是 LLM 众多应用之一。以下基准测试显示了 TensorRT-LLM 为最新 NVIDIA Hopper 架构带来的性能提升。
下图比较了 NVIDIA A100 与 NVIDIA H100 运行 CNN/Daily Mai(著名的摘要性能评估数据集)时的文章摘要性能。
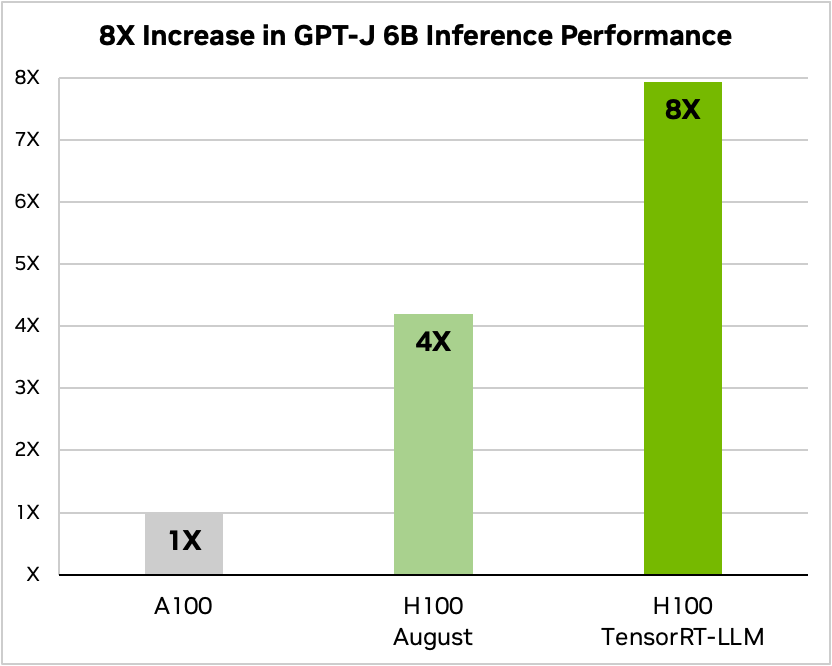
在图 1 中,仅 H100 就比 A100 快 4 倍。在加入 TensorRT-LLM 及 in-flight 批处理等优势功能后,总体性能提高了 8 倍,实现了最高吞吐量。
图表脚注… 文本摘要,I/O 长度可变,CNN/Daily Mail 数据集 | A100 FP16 PyTorch eager 模式 | H100 FP8 | H100 FP8,in-flight 批处理,TensorRT-LLM
图 1. A100 与 H100(使用 TensorRT-LLM 和不使用 TensorRT-LLM 时)运行 GPT-J-6B 时的性能比较
替代文本:此柱状图显示了 A100 和 H100 在使用和不使用 TensorRT-LLM 时的 GPT-J 性能比较。
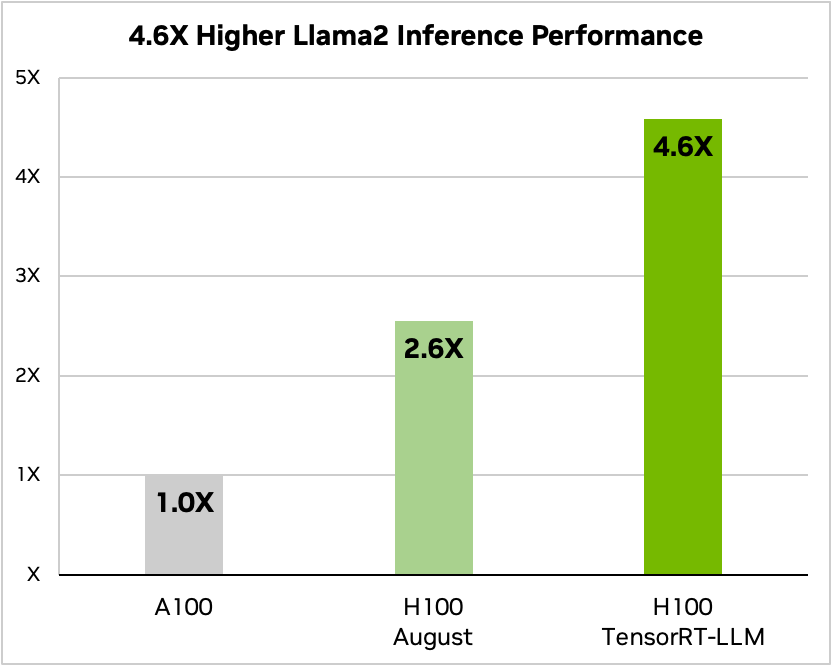
TensorRT-LLM 为 Llama 2(近期由 Meta 发布的一个流行的语言模型,被想要采用生成式 AI 的企业机构广泛使用)带来的推理性能比 A100 GPU 高出 4.6 倍。
图表脚注… 文本摘要,可变 I/O 长度,CNN/Daily Mail 数据集 | A100 FP16 PyTorch eager 模式 | H100 FP8 | H100 FP8,in-flight 批处理,TensorRT-LLM
图2. A100 与 H100(使用和不使用 TensorRT-LLM)运行 Llama 2 70B 模型时的性能对比
替代文本:此柱状图显示了 A100 和 H100 在使用和不使用 TensorRT-LLM 时的 Llama 2 70B 模型性能比较。
总体拥有成本与能效提升
最小化数据中心的总拥有成本(TCO)和能源消耗是采用人工智能的客户的关键目标,尤其是考虑到计算需求的爆炸式增长,LLM 更是如此。涉及到人工智能平台支出时,客户并不仅仅关注单个服务器的成本。相反,他们必须考虑总资本和运营成本。
资本成本包括 GPU 服务器、管理头节点(协调所有 GPU 服务器的 CPU 服务器)、网络设备(网络架构、以太网和布线)和存储的成本。运营成本包括数据中心的 IT 人员和软件、设备维护以及数据中心租金和电费。从数据中心实际成本的整体层面来看,性能的大幅提升降低了设备和维护要求,从而节省了大量资本和运营费用。
以下图表显示,与 A100 基准相比,GPT-J-6B 等小语言模型的性能提升 8 倍,总拥有成本降低 5.3 倍,能耗(节省电费)降低 5.6 倍:
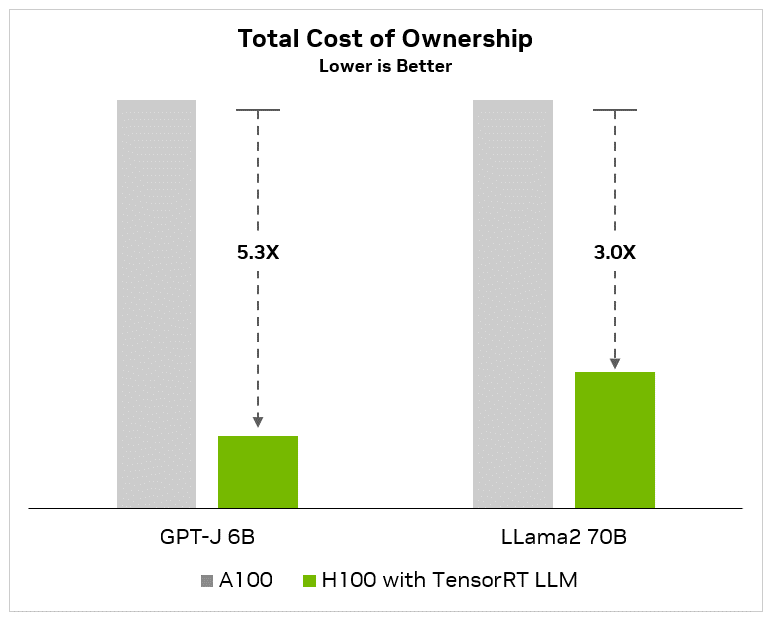
图 3. 相比 A100 与使用 TensorRT-LLM 的 H100 运行 GPT-J-6B 模型,所显示的总体拥有成本和能源成本效益。
替代文本:此柱状图显示了 A100 和 H100 总拥有成本和能源效益之间的 GPT-J-6B 模型性能比较。
同样,在最先进的 LLM(如 Llama2)上,即使有 700 亿个参数,与 A100 基准相比,客户也能将性能提高 4.6 倍,从而将总体拥有成本降低 3 倍,能耗降低 3.2 倍:
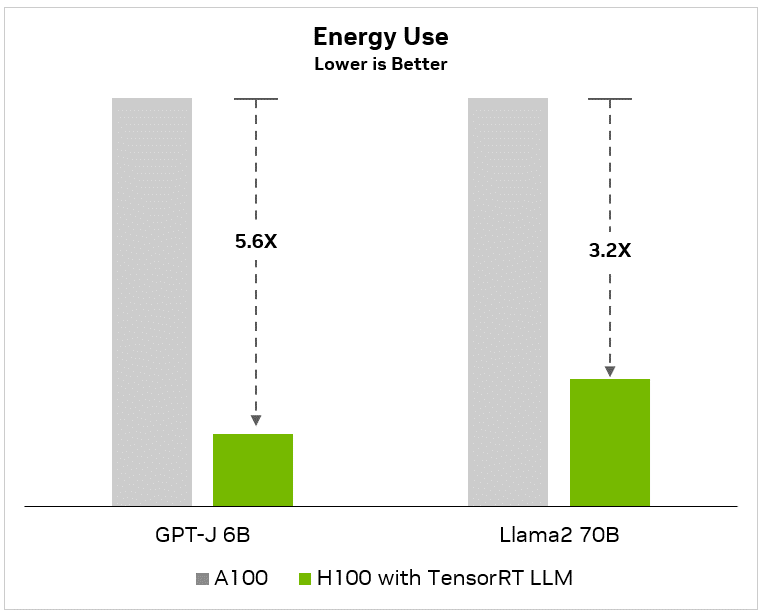
图 4. 相比 A100 与使用 TensorRT-LLM 的 H100 运行 Llama 2 70B 模型的 TCO 和能源成本效益比较。
替代文本:此柱状图显示了运行 Llama 2 70B 模型的A100 和 H100 总拥有成本和能源效益之间的性能比较。
除上述总体拥有成本外,与软件开发相关的大量人力成本也很容易超过基础设施本身的成本。NVIDIA 在 TensorRT、TensortRT-LLM、Triton 推理服务器和 NeMo 框架方面的投资为开发人员节省了大量时间,并缩短了产品上市时间。客户需要将这些人工成本考虑在内,以了解其 AI 总支出的真实情况——人工成本很容易超过资本和运营成本。
LLM 生态飞速扩张
该生态正在快速创新,开发各种各样的新模型架构。更大的模型解锁了新的功能和用例。一些最大、最先进的语言模型,比如 Meta 的 700 亿参数 Llama 2 等需要多个 GPU 协同工作才能作出实时回复。以前,开发人员如果想要获得 LLM 推理的最佳性能,必须重写并手动将 AI 模型分割成多个片段,然后协调各个 GPU 之间的执行。
TensorRT-LLM 使用的张量并行是一种将各个权重矩阵分割到不同设备上的模型并行模式,可实现大规模的高效率推理,每个模型在通过 NVLink 连接的多个 GPU 以及多个服务器上并行运行,无需开发人员干预或更改模型。
随着新模型和模型架构的推出,开发人员可以使用 TensorRT-LLM 中的最新 NVIDIA 开源 AI 内核优化他们的模型。支持的内核融合包括用于 GPT 模型执行中的上下文和生成阶段的最新版本 FlashAttention 和掩码多头注意力机制等等。
此外,TensorRT-LLM 还内置许多目前被广泛用于生产的 LLM,而且提供的是经过全面优化且可直接运行的版本,包括 Meta Llama 2、OpenAI GPT-2 和 GPT-3、Falcon、Mosaic MPT、BLOOM 以及其他十几种 LLM,所有这些都可以通过简单易用的 TensorRT-LLM Python API 实现。
这些功能帮助开发人员更加快速、精准地创建自定义 LLM,满足几乎所有行业的需求。
In-flight 批处理
当今的大语言模型用途极为广泛。一个模型可以同时用于多种看起来截然不同的任务。从使用聊天机器人简单回答问题,到文档摘要或生成长代码,工作负载十分多变,输出结果的大小会相差几个数量级。
这种多变性会导致难以有效批量处理和并行执行请求(一项常见的神经网络优化措施),而这可能导致某些请求比其他请求更早完成。
为了应对这些多变的负载,TensorRT-LLM 采用了一种称为“in-flight 处理”的优化调度技术,充分利用了 LLM 的整个文本生成过程可以分割成模型的多个执行迭代这一特点。
通过 in-flight 批处理,TensorRT-LLM 运行时不会等待整个批处理完成后再继续处理下一组请求,而是会立即驱逐批中已完成的序列。然后,它会在其他请求仍在传输时就开始执行新的请求。在 H100 Tensor Core GPU 上进行的实际 LLM 请求基准测试中,in-flight 批处理和增加的内核级优化措施不仅提高了 GPU 的使用率,还使吞吐量至少提高了一倍,帮助降低能源成本,最小化总体拥有成本。
使用 FP8 格式的 H100 Transformer 引擎
LLM 包含数十亿个模型权值和激活值,通常使用 16 位浮点(FP16 或 BF16)值进行训练和表示,每个值占用 16 位内存。但在推理时,大多数模型都可以通过现代量化技术,以较低的精度有效表示,比如 8 位甚至 4 位整数(INT8 或 INT4)。
量化是在不影响准确性的前提下,降低模型权值和激活值精度的过程。使用更低的精度意味着每个参数都更小,因此模型在 GPU 内存中占用的空间也就更小。这样就能在相同的硬件条件下实现更大模型上的推理,同时在执行过程中减少内存运行时间。
带有 TensorRT-LLM 的 NVIDIA H100 GPU 使用户能够轻松地将模型权值转换成新的 FP8 格式,并通过编译模型自动利用经过优化的 FP8 内核。这都是通过 Hopper Transformer 引擎技术实现的,不需要更改任何模型代码。
H100 引入的 FP8 数据格式使开发人员能够量化模型,并在不降低模型准确性的前提下大幅减少内存消耗。与 INT8 或 INT4 等其他数据格式相比,FP8 量化在保持更高准确性的同时,实现了最快的性能并提供了最简单的实现方式。
总结
LLM 的发展日新月异。每天都有不同的模型架构被开发出来,促进生态的不断发展。而更大的模型又会解锁新的功能和用例,推动各行各业的采用。
LLM 推理正在重塑数据中心。更强大的性能与更高的准确性优化了企业的总体拥有成本。模型创新提升了客户体验,进而提高收入和盈利。
在规划推理部署项目时,除了要使用最先进的 LLM 实现最高性能之外,还需要考虑许多其他因素。优化很少自动产生,用户必须考虑并行性、端到端流程和高级调度技术等微调因素,并且还需要一个在不降低准确性的前提下处理混合精度的计算平台。
TensorRT-LLM 将 TensorRT 的深度学习编译器、经过优化的内核、前处理和后处理以及多 GPU/多节点通信囊括到一个简单的开源 Python API 中,可定义、优化和执行用于生产级推理的 LLM。
开始使用 TensorRT-LLM
NVIDIA TensorRT-LLM 现已推出抢先体验版本,很快就将集成到 NVIDIA NeMo 框架中,该框架是 NVIDIA AI Enterprise 这一兼具安全性、稳定性、可管理性和支持性的企业级 AI 软件平台的一部分。开发人员和研究人员可以通过 NGC 上的 NeMo 框架或 GitHub 上的源代码库接入 TensorRT-LLM。
请注意,您必须先在 NVIDIA 开发者计划中注册,才能申请使用抢先体验版本。请使用贵司的电子邮件地址登录。暂不接受使用 Gmail、Yahoo、QQ 或其他个人电子邮件帐户提交的申请。
如欲申请,请填写简短的申请表并告知详细用途。