人工智能处理需要跨硬件和软件平台的全栈创新,以满足神经网络日益增长的计算需求。提高效率的一个关键领域是使用较低精度的数字格式来提高计算效率,减少内存使用,并优化互连带宽。
为了实现这些好处,业界已经从 32 位精度转换为 16 位,现在甚至是 8 位精度格式。 transformer 网络是人工智能中最重要的创新之一,尤其受益于 8 位浮点精度。我们相信,拥有一种通用的交换格式将使硬件和软件平台的快速发展和互操作性得以提高,从而推动计算。
NVIDIA 、 Arm 和 Intel 联合撰写了一份白皮书 FP8 Formats for Deep Learning ,描述了 8 位浮点( FP8 )规范。它提供了一种通用的格式,通过优化内存使用来加速人工智能的开发,并适用于人工智能训练和推理。此 FP8 规格有两种变体, E5M2 和 E4M3 。
该格式在 NVIDIA 料斗体系结构中本地实现,并在初始测试中显示出出色的结果。它将立即受益于更广泛的生态系统所做的工作,包括 AI 框架,为开发者实现它。
兼容性和灵活性
FP8 通过硬件和软件之间的良好平衡,最大限度地减少了与现有 IEEE 754 浮点格式的偏差,以利用现有实现,加快采用速度,并提高开发人员的生产力。
E5M2 使用五位表示指数,两位表示尾数,是一种截断的 IEEE FP16 格式。在需要更高精度而牺牲某些数值范围的情况下, E4M3 格式进行了一些调整,以扩展用四位指数和三位尾数表示的范围。
新格式节省了额外的计算周期,因为它只使用 8 位。它可以用于人工智能训练和推理,而不需要在精度之间进行任何重铸。此外,通过最小化与现有浮点格式的偏差,它为未来 AI 创新提供了最大的自由度,同时仍坚持当前的惯例。
高精度训练和推理
测试提议的 FP8 格式显示,在广泛的用例、架构和网络中,其精度相当于 16 位精度。变压器、计算机视觉和 GAN 网络的结果都表明, FP8 训练精度与 16 位精度相似,但可以显著提高速度。有关精度研究的更多信息,请参阅 FP8 Formats for Deep Learning 白皮书。

在图 1 中,不同的网络使用不同的精度度量( PPL 和 Loss ),如图所示。
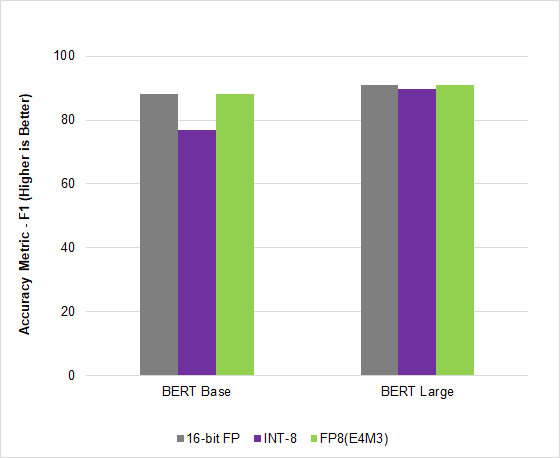
在人工智能行业领先的基准 MLPerf Inference v2.1 中, NVIDIA Hopper 利用这种新的 FP8 格式在 BERT 高精度模型上实现了 4.5 倍的加速,在不影响精度的情况下获得了吞吐量。
走向标准化
NVIDIA 、 Arm 和 Intel 以开放、无许可证的格式发布了此规范,以鼓励行业广泛采用。他们还将向 IEEE 提交该提案。
通过采用一种保持准确性的可互换格式,人工智能模型将在所有硬件平台上持续高效地运行,并有助于推动人工智能的发展。
鼓励标准机构和整个行业建立能够有效采用新标准的平台。这将通过提供通用的、可互换的精度,帮助加速 AI 的开发和部署。