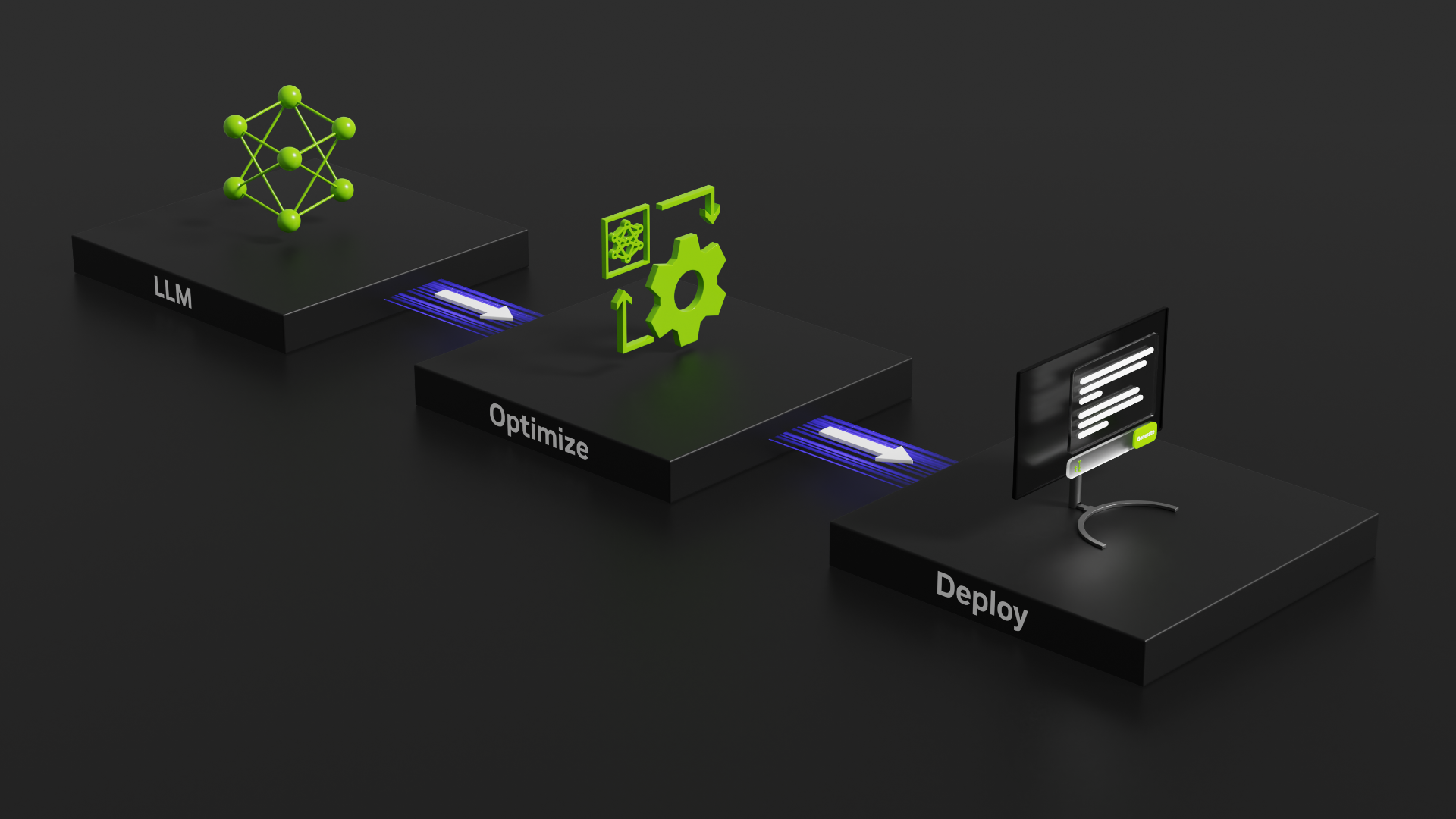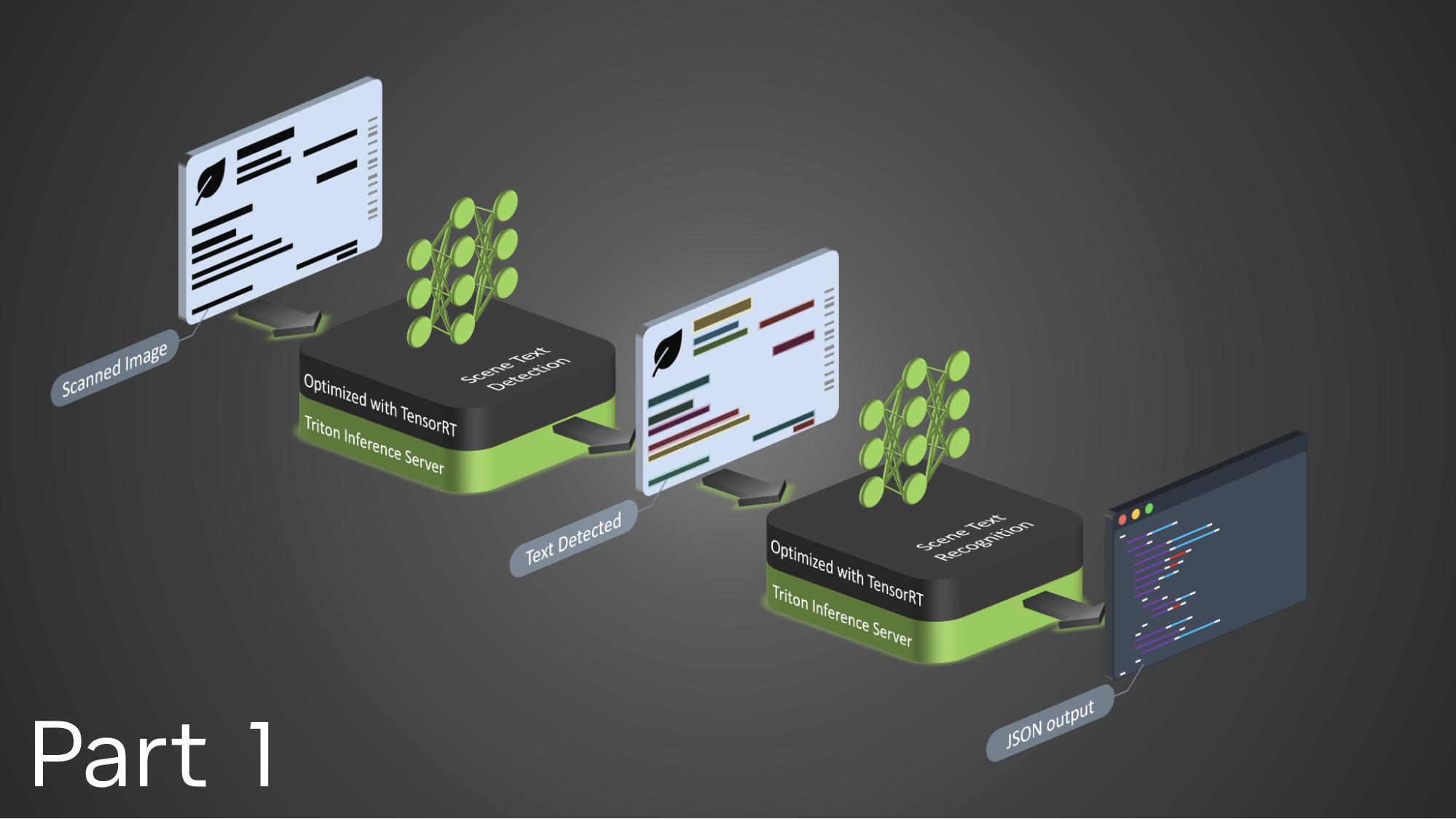
在 2023 年的 NVIDIA GTC 2023 上, NVIDIA 公布了其 NVIDIA AI 软件套件的显著更新,供开发者加速计算。这些更新降低了几个领域的成本,例如使用 NVIDIA RAPIDS 的数据科学工作负载、使用 NVIDIA Triton 的模型分析、使用 NVID IA CV- CUDA 的人工智能成像和计算机视觉等。
为了跟上 NVIDIA 最新的 SDK 进步,请观看首席执行官黄仁勋的 GTC keynote 。
NVIDIA RAPIDS Apache 加速器 Spark
NVIDIA RAPIDS Accelerator for Apache Spark 现已在 NVIDIA AI Enterprise 3.1 软件套件中提供。使用 Apache Spark 3 在不更改代码的情况下加快数据处理和分析或模型培训,同时降低基础设施成本。
亮点:
- 与主要平台的集成:谷歌云平台( GCP ) Dataproc 、 Amazon EMR 、 Azure 和 AWS 上的 Databricks 以及 Cloudera
- Accelerated Spark Analysis Tool 进行成本节约预测,并建议优化 GPU 参数,以最大限度地加快工作负载
- 借助 NVIDIA AI Enterprise ,充分利用 NVIDIA 有保证的响应时间、优先级安全通知和数据科学专家
立即申请 ,获得 evaluate your Spark workloads 的 GPU 加速免费咨询,并学会以平均 4 倍的加速配置集群。
将此 GTC 会话添加到您的日历中:
视频 RAPIDS
在大型语言模型、推荐系统和计算机视觉等用例中,矢量搜索正成为越来越重要的一步。在 GTC 2023 上, NVIDIA 宣布 RAPIDS RAFT ,一个提供加速、可组合 ML 构建块的工具包,现在可以进行矢量搜索。
通过集成 RAPIDS RAFT ,矢量数据库和搜索引擎现在可以为构建索引、加载数据和执行许多不同的查询类型等任务提供显著更快的性能。
亮点:
- RAFT 通过在 GPU 上提供加速的精确和近似最近邻基元来加速矢量搜索用例
- RAFT 支持的索引构建时间比 CPU 实现快 95 倍,每秒查询速度快 3 倍
NVIDIA 已经在与 FAISS 、 Milvus 和 Redis 合作,通过在 RAFT 的基础上进行构建,为其用户带来更好的矢量搜索性能。 Milvus 的 GPU 电源后端经过 RAFT 优化后不久将上市。
有关 RAPIDS RAFT 矢量搜索功能及其所能提供的其他一切的更多信息,请参阅 RAPIDS RAFT User’s Guide 和 /rapidsai/raft GitHub 回购。
将这些 GTC 会话添加到您的日历中:
- Improving Dense Text Retrieval Accuracy with Approximate Nearest Neighbor Search
- Graph-Based, GPU-Optimized Approximate Nearest Neighbor Search Library for Both Batch Processing and Online Services
- Accelerate Data Science Workloads in Python with RAPIDS
CV- CUDA NVIDIA 公司
CV- CUDA 将于 2023 年 4 月进行公测,它是一个新的开源库,用于构建 GPU 加速的云级人工智能计算机视觉预处理和后处理管道。
亮点:
- 30 多名具有 C / C ++和 Python API 的计算机视觉操作员,可加速对象检测、分割和分类工作流程
- 支持批量处理可变形状的图像
- 使用 DLPack 和 PyTorch 阵列接口与 TensorFlow 和 PyTorch 进行零拷贝集成
- 单线 PIP 安装和 PyPi 可用性
- NVIDIA Triton 使用 CV- CUDA 、 TensorRT 和 VPF 进行视频编码和解码的推理服务器示例
有关更多信息,请参阅 /CVCUDA/CV-CUDA GitHub 回购。
将这些 GTC 会话添加到您的日历中:
- Overcoming Pre- and Post-Processing Bottlenecks in AI-Based Imaging and Computer Vision Pipelines
- Building AI-Based HD Maps for Autonomous Vehicles
- Connect with the Experts: GPU-Accelerated Data Processing with NVIDIA Libraries
- Advancing AI Applications with Custom GPU-Powered Plug-ins for NVIDIA DeepStream
基托恩维迪亚
cuLitho 是一个用于计算光刻的软件库,它在 NVIDIA Hopper GPU s 上将半导体制造中的最大工作量提高了 40 倍。
随着半导体行业继续推动制造技术的发展,由于物理的限制,它越来越面临挑战。需要光学邻近校正( OPC )和其他计算光刻方法来创建补偿这些挑战的掩模。这些复杂方法的应用已经成为业界最大的计算工作量。
NVIDIA cuLitho 是一个库,包含优化的工具和算法,用于 GPU – 在基于 CPU 的电流方法的基础上,将计算光刻和半导体制造过程加速几个数量级。
亮点:
- 将生产口罩的时间从 2 周缩短到通宵 8 小时
- 精简数据中心: 1 / 8 的空间、 1 / 4 的成本和 1 / 9 的功率
- 实现新的光刻解决方案,如曲线 OPC 和高 NA EUV
有关更多信息和合作伙伴报价,请参阅 NVIDIA cuLitho 。
将这些 GTC 会话添加到您的日历中:
- Accelerating Computational Lithography: Enabling our Electronic Future
- AI for Microelectronics Design
印度 Triton
开源推理服务软件 NVIDIA Triton Inference Server 的关键更新为生产中的每个应用程序带来了快速且可扩展的人工智能。去年增加了超过 66 个功能。
软件更新:
- PyTriton 作为一个简单的接口,可以在本机 Python 代码中运行 NVIDIA Triton ,实现基于 Python 的模型的快速原型设计和轻松迁移
- 支持 Model Analyzer 中的模型集成和并发模型分析。
- Paddle Paddle 支持并与 Paddle Paddle-FastDeploy 集成
- FasterTransformer backend 支持 GPT 中的 BERT 、拥抱脸 BLOOM 和 FP8
- NVIDIA Triton 管理服务( early access ),用于大规模推理的模型的自动化和资源高效编排
在 NVIDIA LaunchPad 中使用短期访问开启您的推理之旅,而无需设置自己的环境。
开始使用 NVIDIA Triton 并获得 enterprise-grade support 。
将这些 GTC 会话添加到您的日历中:
- Taking AI Models to Production: Accelerated Inference with Triton Inference Server
- Efficient Inference of Extremely Large Transformer Models
- Connect with the Experts: Accelerating and Deploying Deep Learning Models to Production
印度 TensorRT
NVIDIA TensorRT 是一款用于高性能深度学习推理的 SDK ,其更新包括深度学习推理优化器和运行时,为推理应用程序提供低延迟和高吞吐量。
新功能:
- 生成人工智能扩散和 transformer 模型的性能优化
- 增强了硬件兼容性,可在不同的 GPU 体系结构( NVIDIA Ampere 体系结构及更高版本)上构建和运行
- 版本兼容性,使您可以在 TensorRT 8.6 及更高版本的不同 TensorRT 版本上构建和运行
- 早期访问中 GPT-3 模型的多 GPU 、多节点推理
在 NVIDIA LaunchPad 中使用短期访问开启您的推理之旅,而无需设置自己的环境。
开始使用 TensorRT 并获得 enterprise-grade support 。
将这些 GTC 会话添加到您的日历中:
- TensorRT 8.6: Hardware & Version Compatibility
- Exploring Next Generation Methods for Optimizing PyTorch models for Inference with Torch-TensorRT
- Accelerating Transformer-Based Encoder-Decoder Language Models for Sequence-to-Sequence Tasks
NVIDIA TAO 工具包
通过对 TAO Toolkit 的集中更新,您可以利用迁移学习的强大功能和效率,为任何平台实现最先进的精度和生产级吞吐量。这个低代码人工智能工具包加速了从初学者到专家数据科学家的所有技能水平的视觉人工智能模型开发。
亮点:
- 用于图像分类、对象检测和分割任务的最先进的新视觉 transformer
- 用于自动生成分割掩码的人工智能辅助注释工具
- ONNX 模型导出,使 TAO 模型能够部署在任何设备上,如 GPU 、 CPU 和 MCU
- 通过提供 TAO 作为开源,提高了人工智能的透明度和可解释性
有关更多信息,请参阅 Access the Latest in Vision AI Model Development Workflows with NVIDIA TAO Toolkit 5.0 。开始使用 TAO Toolkit 定制您的人工智能模型,并在 LaunchPad 上试用。
将这些 GTC 会话添加到您的日历中:
- AI Models Made Simple Using TAO
- Running TAO Toolkit API in NetsPresso for Effortless Vision AI Model Development and Optimization
- Solving Computer Vision Grand Challenges in One-Click
印度 DeepStream
NVIDIA 推出了最新版本的 DeepStream ,增加了一个新的运行时。它启用了新的功能,并释放了需要严格调度解决方案的新用例。现有的 DeepStream 开发人员在解锁智能自动化和 Industry 5.0 用例的同时,继续受益于硬件加速插件。
更新:
- 新的加速扩展
- 具有高级调度选项的新运行时
- 更新了加速插件。
有关更多信息,请参阅 Get Started with the NVIDIA DeepStream SDK 。试试 LaunchPad 。
将这些 GTC 会话添加到您的日历中:
- An Intro into NVIDIA DeepStream and AI-streaming Software Tools
- Advancing AI Applications with Custom GPU-Powered Plug-ins for NVIDIA DeepStream
NVIDIA 量子
NVIDIA 宣布了最新版本的 NVIDIA 量子平台,用于加速量子计算模拟、混合量子经典算法开发和混合系统部署。
cuQuantum 使量子计算生态系统能够以未来量子优势的规模解决问题,从而实现算法的开发以及量子硬件的设计和验证。
cuQuantum 亮点:
- DGX cuQuantum 设备中的多节点、多 GPU 支持。
- 支持近似张量网络方法。
- cuQuantum 的采用势头持续增强,包括 CSP 和工业量子集团。
NVIDIA 还公布了 NVIDIA CUDA Quantum 的全面可用性,这是一个用于混合量子经典计算的开放、 QPU 不可知平台。这种混合的量子经典编程模型可以与当今最重要的科学计算应用程序互操作,使一大批新的领域科学家和研究人员能够对量子计算机进行编程。
CUDA 量子亮点:
- 单源 C ++和 Python 实现,以及用于混合系统的编译器工具链和量子算法基元的标准库
- QPU 不可知论者,与量子硬件公司在广泛的量子位模式上合作
- 与同样在 NVIDIA A100 GPU 上运行的领先 Python ic 框架相比,可实现高达 300 倍的加速
在 GTC 2023 上, NVIDIA 和 Quantum Machines 宣布了 DGX Quantum ,这是一项合作伙伴关系,将世界上最强大的加速计算平台与世界上最先进的量子控制器结合在一起。量子机器和 NVIDIA 将推出首个用于高性能和低延迟量子经典计算的同类架构,从而推动该领域的发展。
DGX Quantum 亮点:
- 一种参考体系结构,具有 PCIe 连接的 OPX + NVIDIA Grace Hopper 系统,可根据 QPU 的大小进行扩展。
- CUDA 与 QUA 和量子机器堆栈的量子集成,具有一个或多个 POC 基准
- 宣布 QCC 作为 QGX 在 2023 年第四季度的首次部署
有关更多信息,请参阅 NVIDIA CUDA Quantum 页面。
将这些 GTC 会话添加到您的日历中:
- Defining the Quantum-Accelerated Supercomputer
- Inside QODA, the Quantum Optimized Device Architecture
印度 Modulus
NVIDIA Modulus 是一个开发物理知情机器学习( physics ML )模型的平台,现在包括数据驱动的神经算子系列架构,用于训练全球范围的天气预测模型,如 FourCastNet 。它使用 NVIDIA 人工智能软件堆栈提供最佳性能和可扩展性,以服务于工业规模的人工智能研究和生产部署。
NVIDIA Modulus 具有扩展的功能,可覆盖不同的领域以及数据驱动和物理驱动的方法。它可以解决从计算流体动力学( CFD )、结构分析到电磁学等广泛应用中的问题。
它可以在简单的 Apache2.0 许可证下以开源形式提供。
除了为参考应用程序开发物理 ML 模型的配方外, Modulus 现在可以自由使用、开发和贡献,无论你在哪个领域。它包括适合不同工作流程的开源存储库,从 modulus-launch 的本地 PyTorch 开发人员到 modulus-sym 的符号偏微分方程工程师。
从 /NVIDIA/modulus GitHub repo 下载 Modulus 源代码。
有关 Modulus 开源的更多信息,请参阅 Physics-Informed Machine Learning Platform NVIDIA Modulus Is Now Open Source 。
将此 GTC 会话添加到您的日历中: