超低延迟与可靠的数据包传输是金融服务、云游戏以及媒体和娱乐等现代应用的关键需求。在这些领域中,微秒级的延迟或单个数据包的丢失都可能带来显著影响,导致经济损失、用户体验下降或媒体流出现明显中断。
低延迟和无数据丢包传输为何重要
以下是一些通常需要低延迟解决方案的常见用例示例:
- FSI: 算法交易和市场数据分布需要确定性的低延迟网络。延迟或丢包会导致错过交易机会或错误决策。
- 云游戏: 云游戏平台必须提供实时渲染和输入反馈。高延迟或丢包会导致延迟、响应速度差和用户不满,考虑到云游戏市场的快速增长,这尤其是个问题。
- 媒体和娱乐: 专业视频直播制作和广播工作流程 (例如 SMPTE ST 2110) 需要精确计时和零丢包,以避免可见伪影并确保符合行业标准。
对于这些用例而言,实现高数据包速率、以线速持续提供带宽,并尽可能减少甚至消除丢包至关重要。传统网络堆栈难以满足这些需求,尤其在网络速率扩展至 10/25/50/100/200 GbE 及更高水平时更为明显。
NVIDIA Rivermax:高性能串流解决方案
NVIDIA Rivermax 是一个基于 IP 的高性能跨平台软件库,专为媒体和数据流应用设计,旨在提供卓越的传输效率与系统响应能力。借助先进的 NVIDIA GPU 加速计算技术和高性能网络接口卡(NIC),Rivermax 实现了高吞吐量、硬件级数据包精确同步、低延迟以及更低的 CPU 占用率。这些特性使其成为对效率和实时性要求较高的关键任务工作负载的理想选择。
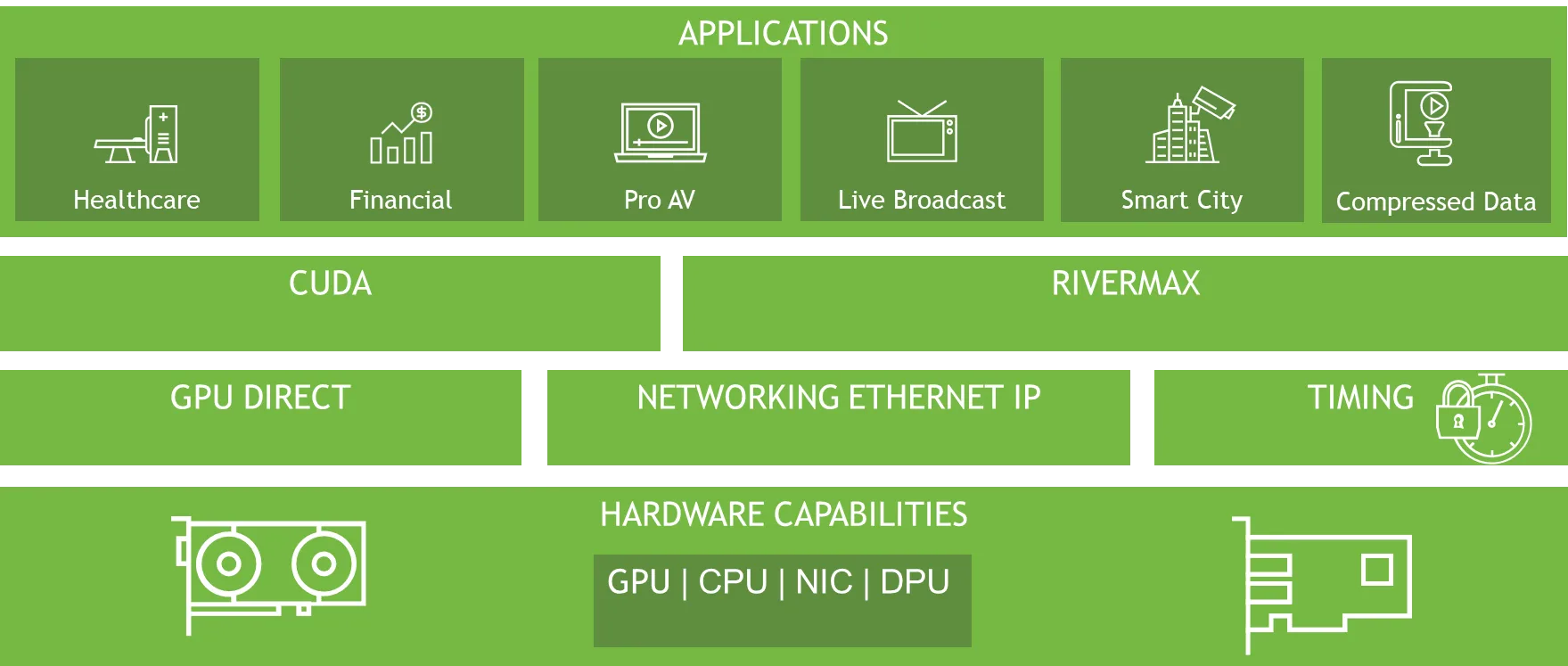
Rivermax 的创新架构依托于多项关键技术。
- 内核旁路:通过绕过传统的操作系统内核,它可以最大限度地减少开销,并实现用户空间内存和 NIC 之间的直接数据传输。这可降低延迟并更大限度地提高吞吐量,从而实现高性能流式传输。
- 零拷贝架构:Rivermax 通过在 GPU 和网卡之间直接传输数据来消除不必要的内存拷贝。这种方法可减少 PCIe 事务、降低 CPU 占用率并加速数据处理。
- GPU 加速:使用 NVIDIA GPUDirect 技术,Rivermax 可在不使用 CPU 的情况下促进 GPU 和网卡之间的数据移动。这种卸载机制可确保高效利用资源,同时保持高吞吐量。
- 基于硬件的数据包同步: Rivermax 通过直接在硬件中实现数据包同步,确保数据流的精确计时。对于需要严格遵守 SMPTE ST 2110-21 等专业媒体工作流标准的应用程序而言,这一点至关重要。
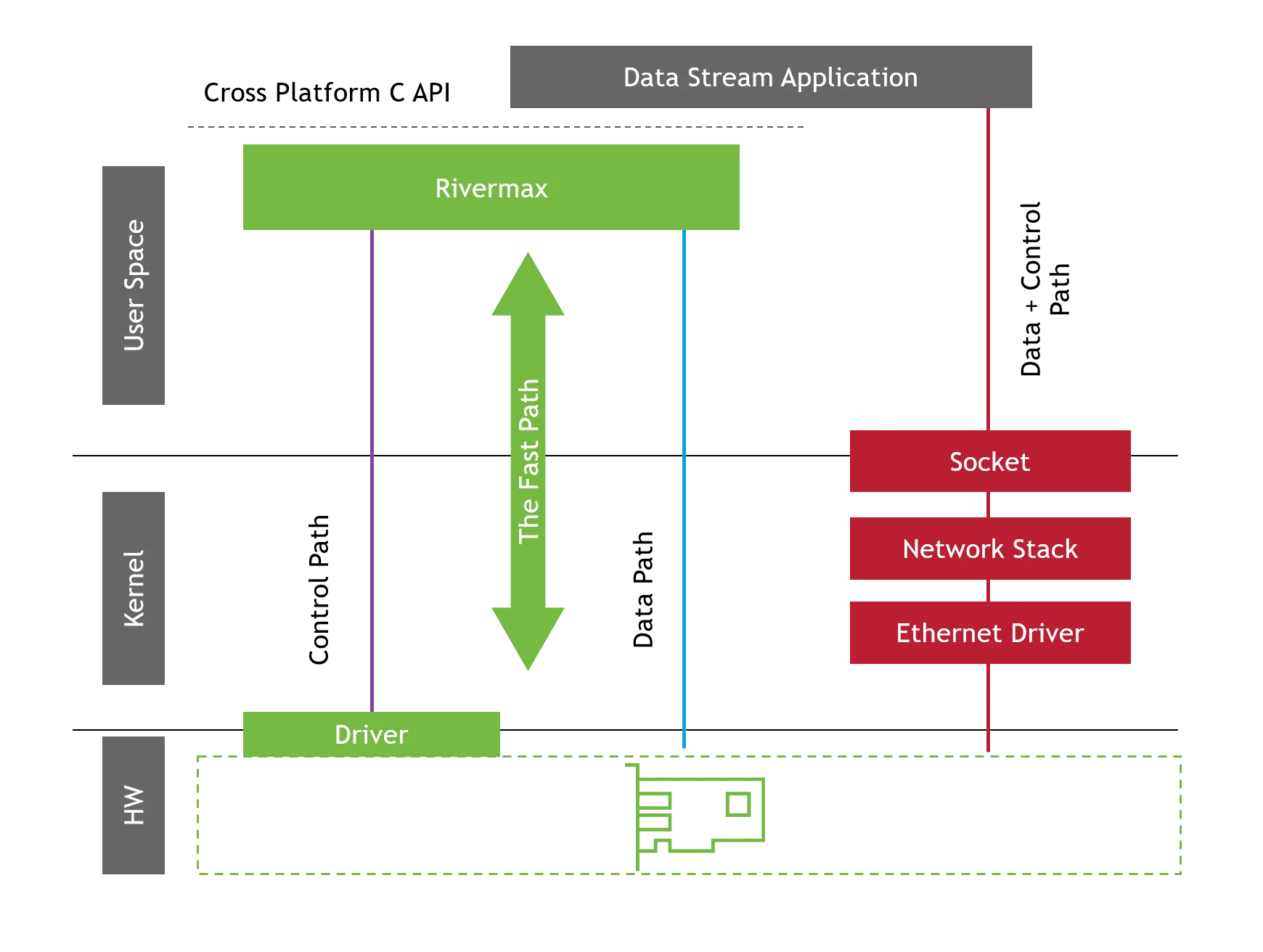
基于 Rivermax 技术的 NEIO FastSocket:可靠的低延迟插槽
随着网络速度的快速提升,传统的基于插槽的通信方式已难以满足需求,尤其在 10/25 GbE 及更高速度的场景下。 NEIO Systems Ltd. 推出的 FastSockets 是一个灵活的中间件库,专为实现高性能的 UDP 和 TCP 通信而设计,有效克服了这些瓶颈。该技术致力于提供超低延迟、高带宽和稳定流畅的数据传输体验。
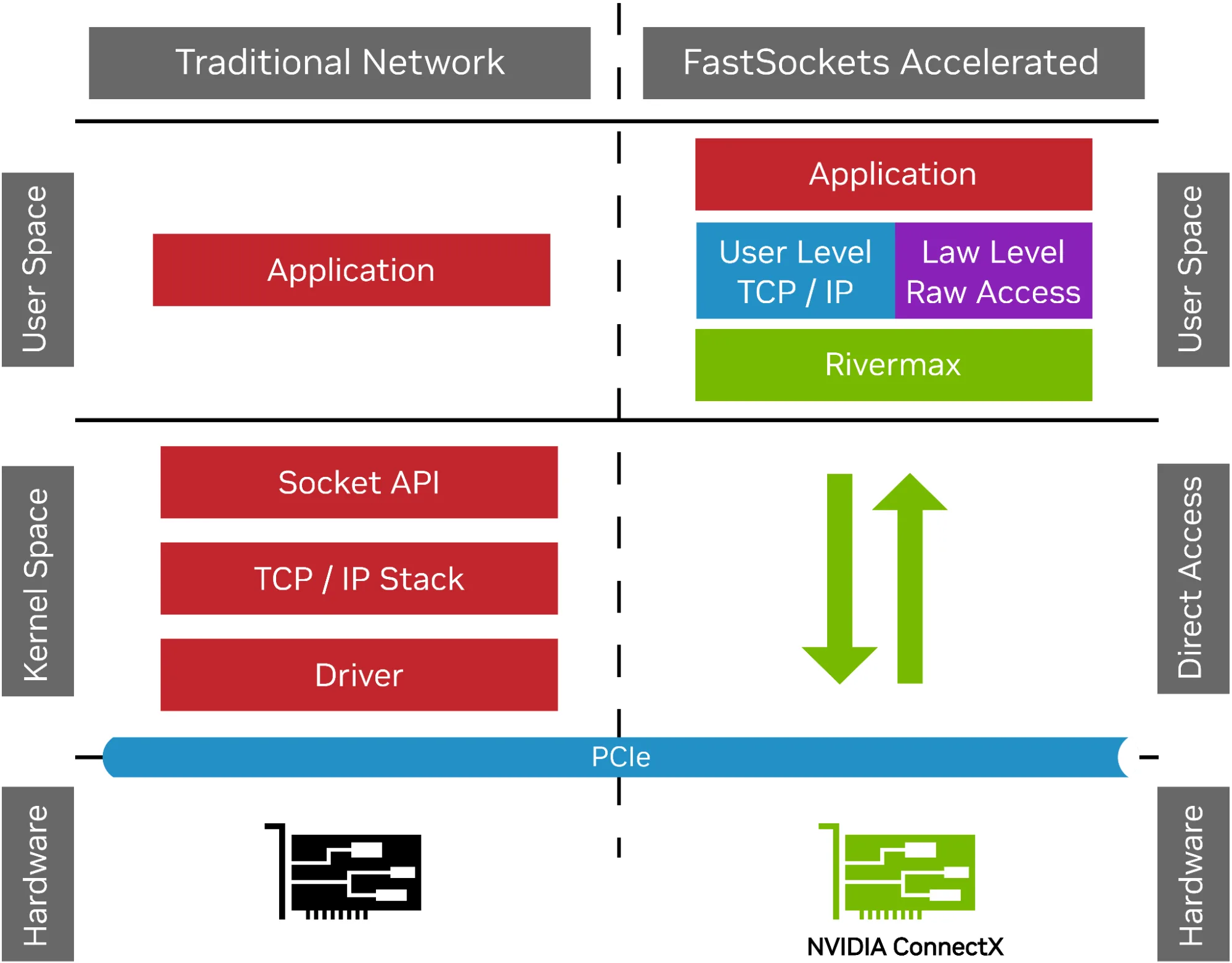
图 3。传统网络与 FastSockets 加速比较
通过采用 NVIDIA ConnectX 网卡并结合 Rivermax 技术,FastSockets 实现了内核旁路,将数据直接从网卡传输至应用程序,显著降低了延迟,同时大幅提升了数据包处理速率。
确保用户数据报协议接收顺畅,实现高性能网络
在现代网络应用中,速度与效率至关重要,可靠的数据传输也因此成为关键。用户数据报协议(UDP)因其低延迟特性,被广泛应用于对实时性要求较高的场景,如机器视觉中的视频流传输和金融市场数据分发。
UDP 的一个关键特征是其无连接的特性,与 TCP 等协议不同,它不提供可靠的传输保障。尽管这种设计有助于提升数据传输速度,但也可能导致数据包丢失。在时间敏感型应用中,实现 UDP 的无丢包接收对于确保高性能至关重要。
防止重传并降低延迟
UDP 不具备内置的数据包恢复机制,因此数据丢失必须由应用程序自行处理。一旦发生丢包,可能需要手动重传,或导致数据缺失。当需要重传时,往往会产生显著的延迟,对延迟敏感的应用造成直接影响。例如,FastSockets 媒体扩展模块支持用于机器视觉的 GigE Vision(GVA)协议,即使轻微的丢包也可能引发明显的画面故障或缓冲延迟。
另一个例子是算法交易系统,在这类系统中,毫秒级的延迟就可能导致交易机会的错失或决策失误。若数据转发过晚,其时效性可能已丧失,因此延迟问题至关重要。FastSockets 利用 Rivermax 提供的核心功能,将数据包直接从网卡传输至应用程序,显著降低传输延迟。
更大限度地提高吞吐量并更大限度地减少系统开销
尽管已采用 CPU 绑定、扩大套接字缓冲区等优化措施,基于内核的套接字仍因系统开销过大而难以应对极高的数据包速率。随着数据包速率上升,内核逐渐成为性能瓶颈,导致数据包丢失。Rivermax 支持的内核旁路技术可将数据直接写入应用程序缓冲区,支持动态缓冲区大小调整和零复制机制,有效避免不必要的数据拷贝。更低的系统开销不仅减少了序列化延迟,还提升了数据包的分发效率。
基准测试
本节介绍的基准测试重点展示了采用 Rivermax 技术所实现的出色性能。FastSockets 支持 Linux 和 Windows 系统,本文主要关注其在 Windows 平台上的表现,因为 Rivermax 在该平台具有显著优势。需要注意的是,由于 RIO 功能存在限制,无法开展全面的网络性能评估,因此 RIO 的基准测试范围较为有限。
指标和方法
该基准测试评估了三个关键的网络性能指标:持续吞吐量、平均数据包速率和端到端延迟。这些指标对于高吞吐量与极低延迟要求较高的应用场景至关重要,例如金融交易、云游戏以及专业媒体工作流。我们使用运行在25 GbE速率下的NVIDIA ConnectX-6网卡,对Rivermax、带寄存器的I/O(RIO)和FastSockets进行了对比测试。由于RIO在此测试环境中的功能较为有限,其评估结果也反映了其在当前场景下的能力局限。
持续吞吐量
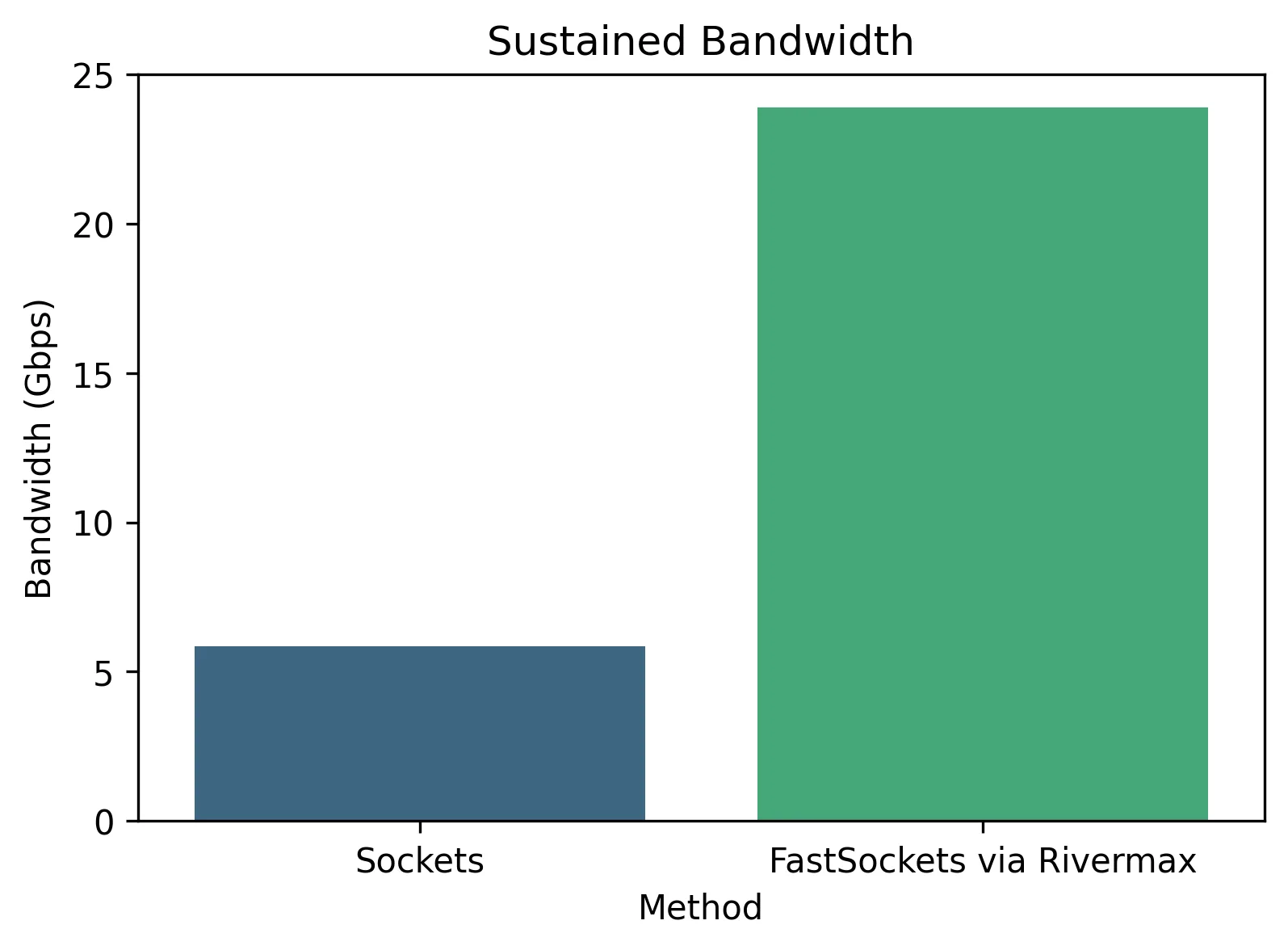
持续吞吐量用于衡量网卡与应用程序之间能够稳定维持的最高数据传输速率。实现线速吞吐量对于高性能流媒体传输和实时数据传输至关重要。如图4所示,采用Rivermax的FastSockets可实现持续的线速吞吐量,而传统套接字则明显无法达到这一水平。
平均数据包速率
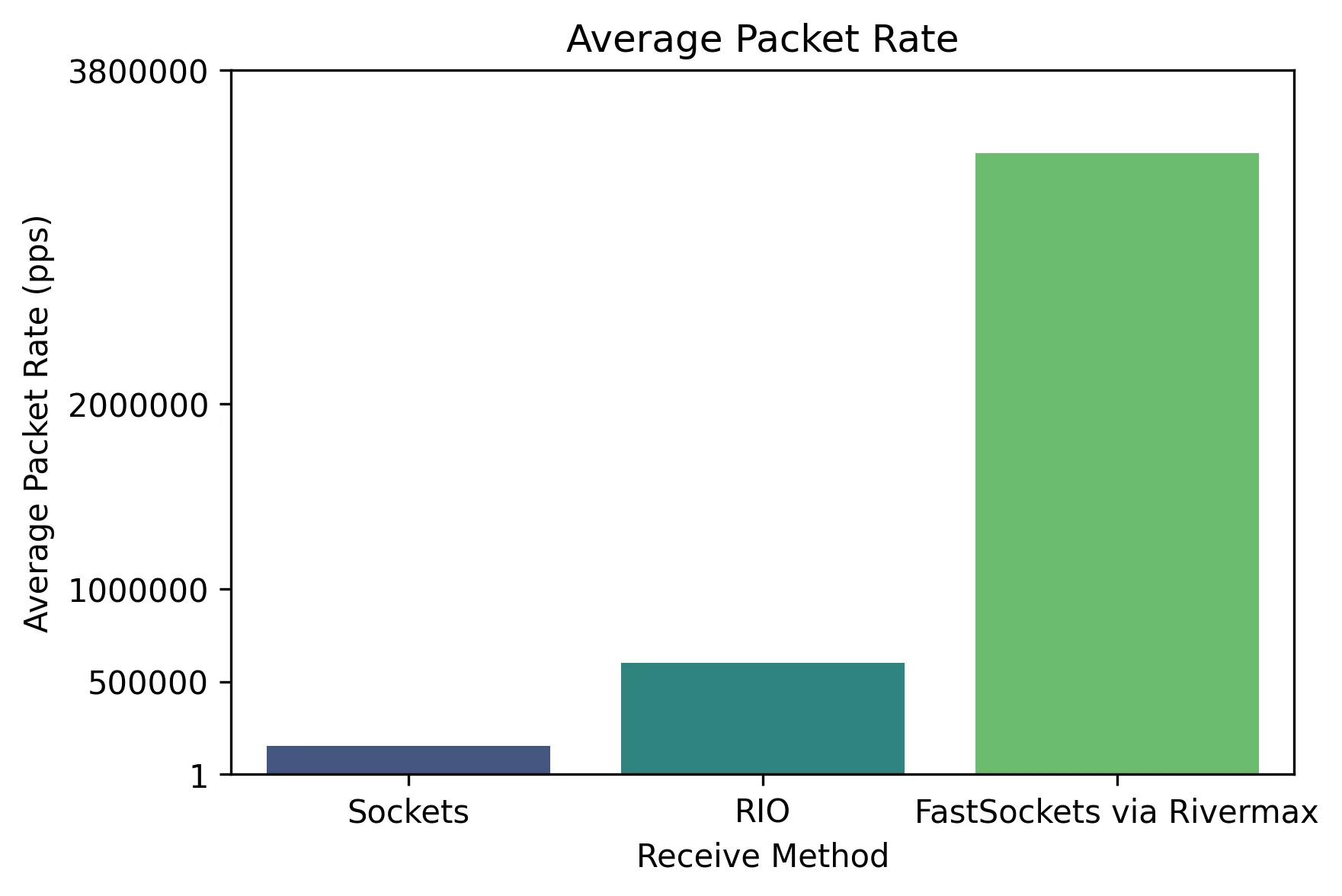
平均数据包速率反映了每秒处理的数据包数量,对于频繁进行小规模数据传输的工作负载而言,这一指标尤为关键。较高的数据包速率有助于降低序列化延迟,从而实现更及时的数据传输。如图5所示,采用Rivermax实现的FastSockets在提升平均数据包速率方面表现显著,明显优于Socket和RIO方案。
延迟
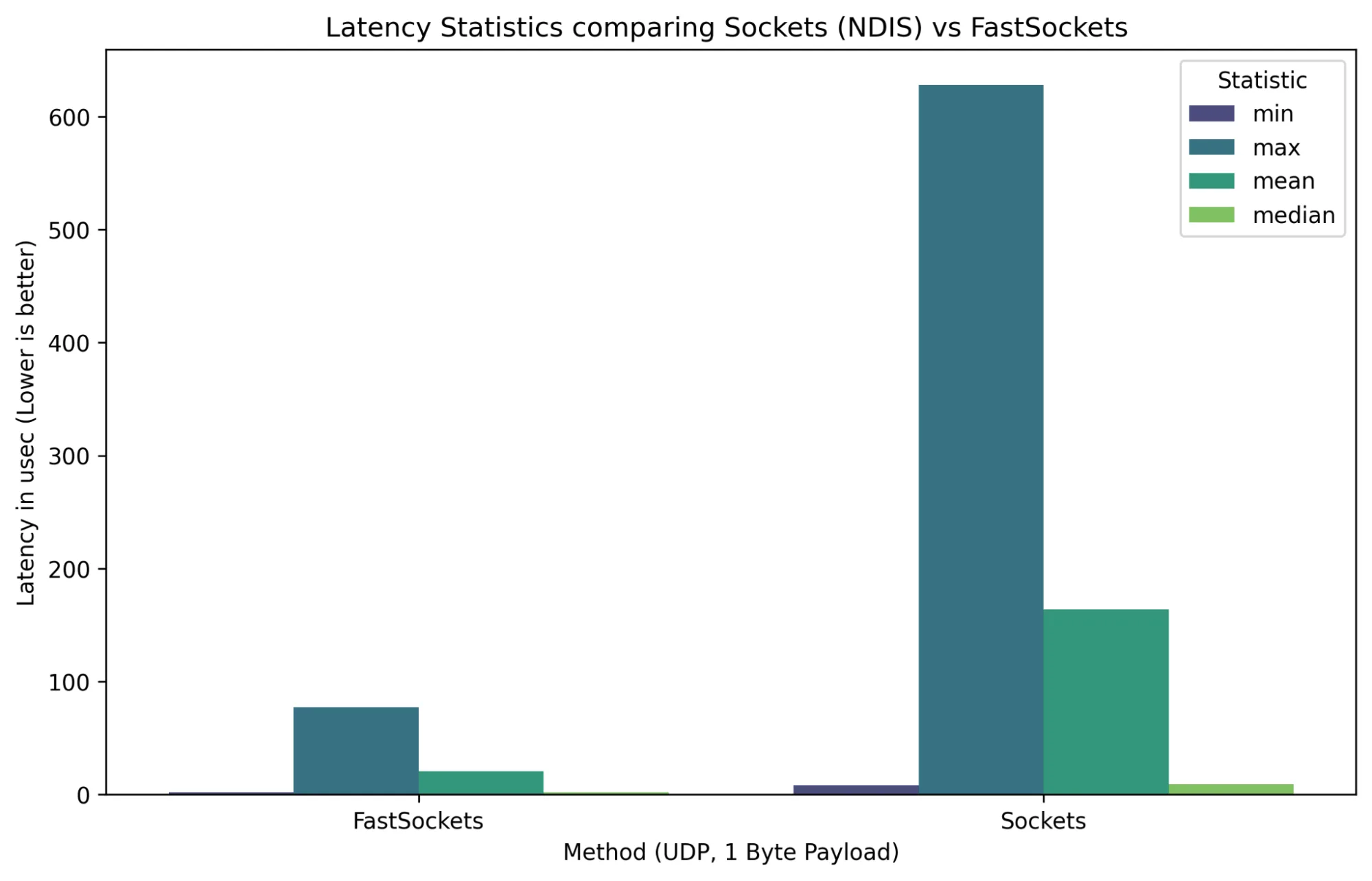
延迟是指数据从网卡传输到应用程序并返回所需的时间,直接影响实时应用的响应速度。在此场景下,延迟可定义为往返时间的一半,从而提供对数据包单向延迟的合理度量。对于算法交易和媒体直播等应用场景,降低延迟至关重要。如图6所示,与传统插槽相比,FastSockets在最小延迟、平均延迟、中位延迟和最大延迟方面均有显著改善,更适用于对延迟敏感的环境。
序列化延迟
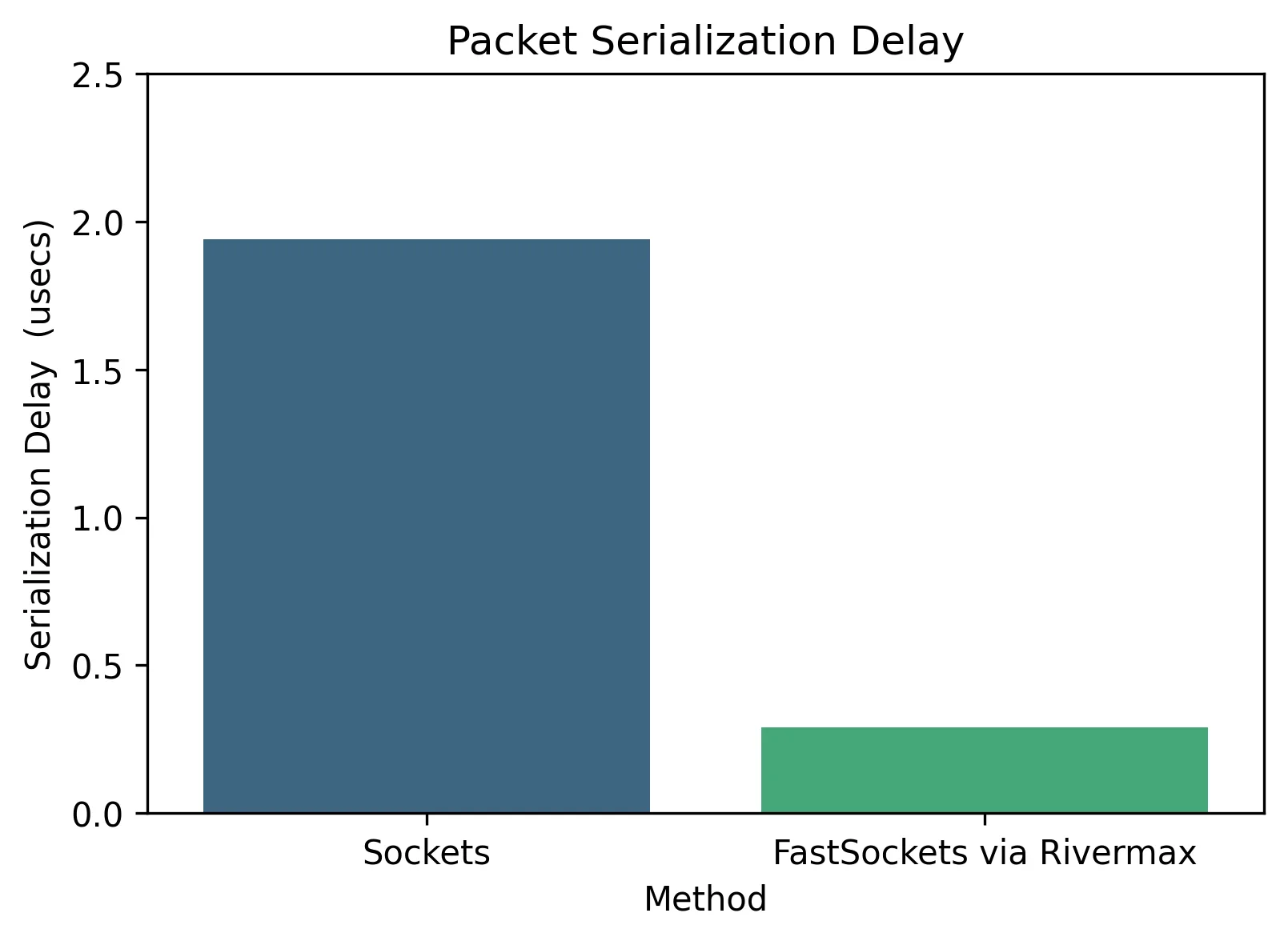
序列化延迟是指将数据包放置到网络介质上所需的时间,直接影响数据从应用层传输至网络的速度。较低的序列化延迟对于提升整体吞吐量、降低端到端延迟具有重要意义,尤其在高性能和实时应用场景中更为关键。如图7所示,与传统套接字相比,Rivermax的FastSockets实现了更低的数据包序列化延迟,进一步提升了其在高要求网络环境中的适用性。
GPUDirect 技术的未来是什么?
GPUDirect 技术通过实现网卡与 GPU 之间的直接内存访问,绕过 CPU,有效降低数据传输延迟,从而提升交易系统的性能。该技术能够将从交易所接收的高频市场数据直接流式传输至 GPU 显存,便于快速运行 AI 模型,识别关键市场模式,例如价格的急剧波动或订单簿的失衡情况。
通过加速该数据管道,系统能够更快地完成推理,使交易软件在高风险或高交易量时期可直接调用高级报价算法(如暂停、取消或扩大市场),同时无需增加CPU负担。
为这些用例部署的 AI 模型经过精心优化,能够利用 GPUDirect 等技术在 GPU 上实现极低延迟的推理。这些模型通常包括:
- 异常检测模型 (自动编码器、隔离森林、VAE) ,用于识别可能在波动或操纵之前出现的异常模式,例如订单动态的突然变化。
- 时间序列预测模型 ( LSTM、TCN、基于 Transformer 的模型) ,用于预测短期市场波动,并在预测价格大幅波动时触发响应。
- 用于事件检测的分类模型 ( CNN、梯度提升树、简单神经网络) ,用于对市场状态进行分类,并在风险或异常事件期间停止引用。
- 强化学习代理 ( DQN、策略梯度、演员 – 评论家) ,可根据不断变化的市场自适应学习最佳行动 (引用、调整、停止) ,以更大限度地提高收益或降低风险。
对实时订单库快照、订单流失衡、交易统计及其他相关数据进行特征工程。推理阶段采用 ONNX、NVIDIA TensorRT 和 NVIDIA CUDA 进一步优化,并通过模型蒸馏与量化,显著降低模型体积与延迟。
借助 Rivermax 与 GPUDirect 提供的零拷贝访问能力,市场数据可直接从高速网卡流式传输至 GPU 显存,有效避免 PCIe 带宽瓶颈。该架构使 AI 模型能够近乎实时地处理市场变化并迅速做出响应,对于在波动期间判断报价时机或执行退出策略具有关键意义。
随着AI和GPU加速技术的持续发展,其与Rivermax等高性能网络解决方案的融合将显著提升速度、智能化水平和适应能力,不仅将重塑交易领域,也将深刻影响所有对延迟敏感的应用场景。
开始使用 Rivermax 和 FastSockets,实现超低延迟与零数据包丢失的应用体验。