
人工智能正在迅速改变工业视觉检测。在工厂环境中,目视检查用于许多问题,包括在组装过程中检测缺陷和丢失或不正确的零件。计算机视觉可以帮助及早发现产品的问题,减少产品交付给客户的机会。
然而,对于边缘人工智能开发人员来说,开发准确且通用的物体检测模型仍然具有挑战性。稳健的对象检测模型需要访问全面且具有代表性的数据集。在许多制造场景中,真实世界的数据集在捕捉实际场景的复杂性和多样性时显得不足。狭窄环境和有限变化的限制对训练模型有效适应一系列情况提出了挑战。
团队可以利用合成数据在与现实世界场景非常相似的多样化随机数据上训练模型,以解决数据集差距。其结果是更准确、适应性更强的人工智能模型,可用于工业自动化、医疗保健和制造业等领域的广泛边缘人工智能应用。
从合成数据生成到人工智能训练
Edge Impulse 是一个集成开发平台,使开发人员能够为边缘设备创建和部署人工智能模型。它支持数据收集、预处理、模型训练和部署,帮助用户将人工智能功能有效地集成到应用程序中。
借助 NVIDIA Omniverse Replicator,这是 NVIDIA Omniverse 的核心扩展,用户可以在 Universal Scene Description 中,也称为 OpenUSD,创建图像。然后,这些图像可以用于在 Edge Impulse 平台上训练对象检测模型。
NVIDIA Omniverse 是一个计算平台,使个人和团队能够开发基于通用场景描述(OpenUSD )的 3D 工作流和应用程序。
OpenUSD 是一种高度通用且可互操作的 3D 可互换格式,由于其可扩展性、性能、版本控制和资产管理功能,它在合成数据生成方面表现出色,是创建复杂逼真数据集的理想选择。有一个庞大的 3D 内容工具生态系统,连接到 OpenUSD 和 基于 USD 的 SimReady 资产,这使得将基于物理的对象集成到场景中变得容易,并加速了我们的合成数据生成工作流程。
Omniverse Replicator 使 USD 数据能够在多个域中随机化,以表示反映对象检测模型可能遇到的现实世界可能性的场景。
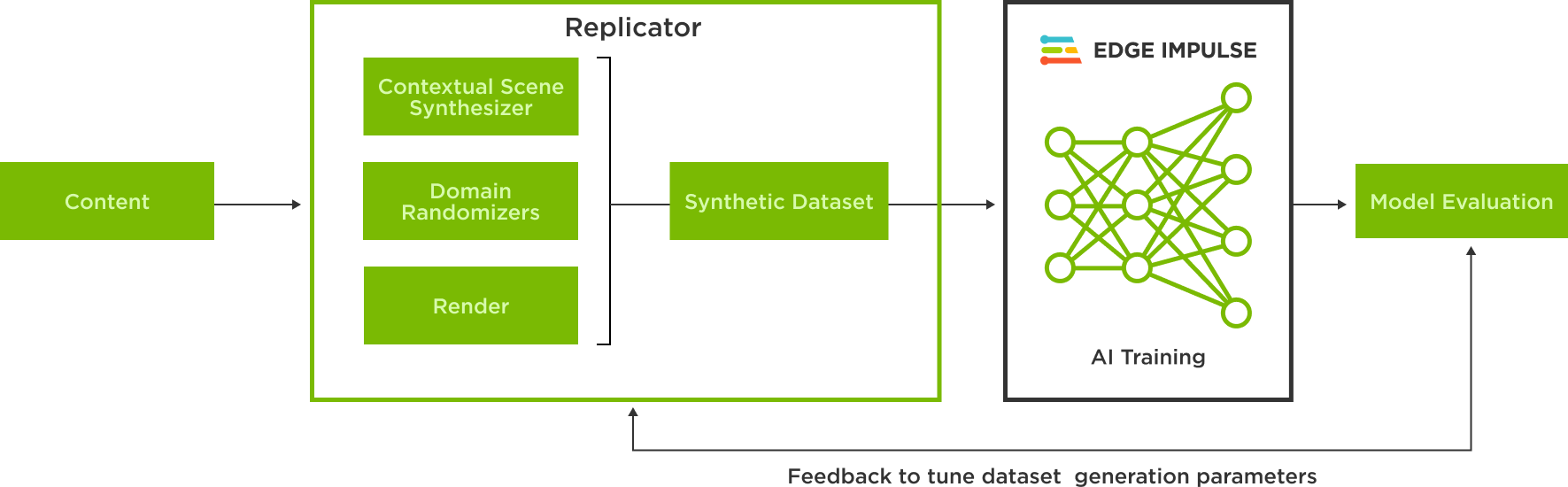
在新的 Edge Impulse Omniverse 扩展中,使用 USD 中合成生成的图像在 Edge Impulsion 中训练模型只需点击几下。
该扩展是使用 Omniverse Kit Python 扩展模板,用户可以连接到 Edge Impulse API 并选择数据集来上传他们的合成数据。Kit Python 扩展模板是一个简单明了的资源,用于代码片段选项和快速开发扩展。
生成对象检测模型的合成数据
要了解使用 Omniverse Replicator 生成合成数据并使用它在 Edge Impulse 中训练模型的工作流程,请以检测汽水罐模型为例。

该过程的第一步是构建一个虚拟复制品,或者说是代表真实场景环境的数字孪生。生成合成图像的场景由可移动和不可移动的物体组成。不可移动的设备包括灯、一条传送带和两台摄像机,而可移动的物体则由汽水罐组成。通过使用 领域随机化,可以更改许多属性,包括选定的不可移动和可移动对象的位置、照明、颜色、纹理、背景和前景。
这些资产通过 OpenUSD 在 Omniverse Replicator 中表示。3D 模型文件可以转换为 USD ,并使用 Omniverse CAD Importer 扩展名导入 Omniverse Replicator。
照明在真实感图像生成中起着关键作用。矩形灯光可以模拟面板生成的灯光,而圆顶灯光可以照亮整个场景。可以随机化灯光的各种参数,如灯光的温度、强度、比例、位置和旋转。
以下脚本显示了通过从正态分布中采样而随机化的温度和强度,以及按均匀分布随机化的量表。灯光的位置和旋转是固定的,以保持不变。
python
# Lightning setup for Rectangular light and Dome light
def rect_lights(num=1):
lights = rep.create.light(
light_type="rect",
temperature=rep.distribution.normal(6500, 500),
intensity=rep.distribution.normal(0, 5000),
position=(45, 110, 0),
rotation=(-90, 0, 0),
scale=rep.distribution.uniform(50, 100),
count=num
)
return lights.node
rep.randomizer.register(rect_lights)
def dome_lights(num=3):
lights = rep.create.light(
light_type="dome",
temperature=rep.distribution.normal(6500, 500),
intensity=rep.distribution.normal(0, 1000),
position=(45, 120, 18),
rotation=(225, 0, 0),
count=num
)
return lights.node
rep.randomizer.register(dome_lights)
大多数场景都有对环境很重要的不可移动物体,比如桌子,或者在这种情况下是传送带。这些对象的位置可以是固定的,而对象的材质可以随机化以反映真实世界的可能性。
下面的脚本在 USD 中生成一个传送带,罐子将放置在该传送带上。它还固定其位置和旋转。在这个例子中,我们没有随机化传送带的材料。
python
# Import and position the conveyor belt
conveyor = rep.create.from_usd(CONVEYOR_USD, semantics=[('class', 'conveyor')])
with conveyor:
rep.modify.pose(
position=(0, 0, 0),
rotation=(0, -90, -90),
)
为了保证高质量的数据集,最好使用多个不同分辨率的相机,并在场景中战略性地定位它们。摄影机的位置也可以随机化。该脚本设置了两个不同分辨率的相机,它们战略性地放置在场景中的不同位置。
# Multiple setup cameras and attach to render products
camera = rep.create.camera(focus_distance=focus_distance, focal_length=focal_length,
position=cam_position, rotation=cam_rotation, f_stop=f_stop)
camera2 = rep.create.camera(focus_distance=focus_distance2, focal_length=focal_length2,
position=cam_position2, rotation=cam_rotation, f_stop=f_stop)
# Render images
render_product = rep.create.render_product(camera, (1024, 1024))
render_product2 = rep.create.render_product(camera2, (1024, 1024))

最后一步是随机化可移动物体的位置,同时将它们保持在相关区域中。在这个脚本中,我们初始化了五个 3D 罐头模型实例,这些实例是从可用的罐头资产集合中随机选择的。
cans = list()
for i in range(TOTAL_CANS):
random_can = random.choice(cans_list)
random_can_name = random_can.split(".")[0].split("/")[-1]
this_can = rep.create.from_usd(random_can, semantics=[('class', 'can')])
with this_can:
rep.modify.pose(
position=(0, 0, 0),
rotation=(0, -90, -90)
)
cans.append(this_can)
然后,罐子的姿势被随机化并分散在两个平面上,使罐子保持在传送带上,同时避免碰撞。
with rep.trigger.on_frame(num_frames=50, rt_subframes=55):
planesList=[('class','plane1'),('class','plane2')]
with rep.create.group(cans):
planes=rep.get.prims(semantics=planesList)
rep.modify.pose(
rotation=rep.distribution.uniform(
(-90, -180, 0), (-90, 180, 0)
)
)
rep.randomizer.scatter_2d(planes, check_for_collisions=True)

注释数据、构建模型和使用真实对象进行测试
生成图像后,只需几次点击,就可以使用 Edge Impulse Omniverse 扩展将图像上传到 Edge Impulse Studio。在 Edge Impulse Studio 中,您可以使用模型对数据集进行注释和训练,例如 Yolov5 物体检测模型。版本控制系统实现了跨不同数据集版本和超参数的模型性能跟踪,以优化精度。
如果您想用真实世界的对象来测试模型的准确性,您可以流式传输实时视频,并使用 Edge Impulse CLI 工具。
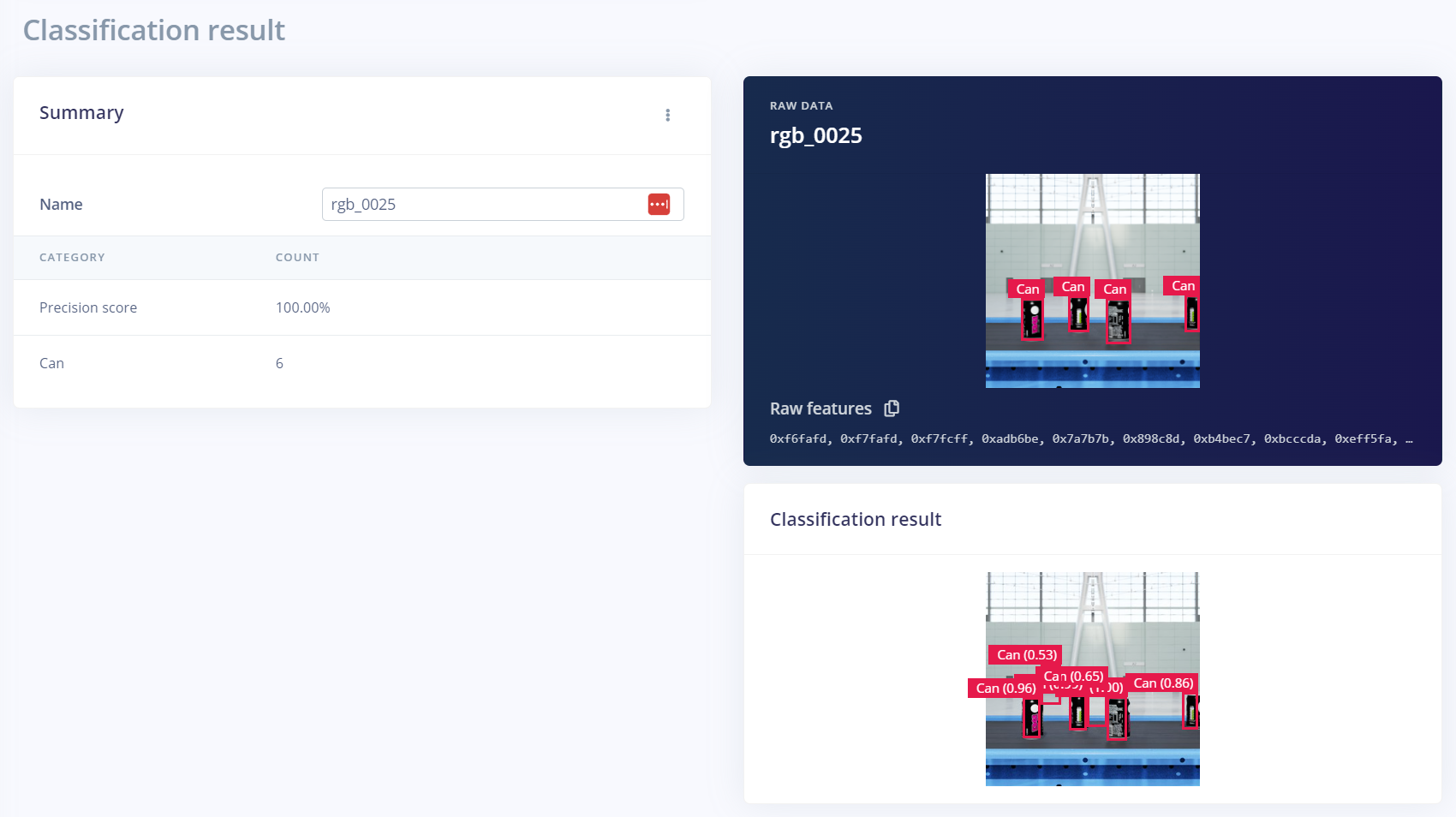
如果模型不能准确地检测到对象,则必须在其他数据集上对模型进行训练。当涉及到人工智能模型训练时,这种迭代过程是常态。合成数据的另一个好处是,可以通过编程完成后续迭代中所需的变化。
在本例中,生成了一个额外的合成数据集,用于训练模型以提高性能。额外的数据集使用了距离输送机更远的摄像机距离。其他参数,如相机的角度和材料,可以在额外的数据集中进行修改,以提高性能。
采用以数据为中心的方法,即围绕模型的故障点创建更多数据,对于解决 ML 问题至关重要。参数的额外训练和微调可以使模型在不同的方向、材料和其他相关条件下很好地推广。
开始使用合成数据训练和部署边缘人工智能
在 Omniverse Replicator 中生成物理上准确的合成数据非常容易。只需 下载 Omniverse 免费版 并按照以下说明 开始使用 Omniverse Code 中的 Replicator。
您可以使用 Edge Impulse 在 Omniverse 中生成的合成数据来训练 ML 模型。请注册并从今天开始使用嵌入式机器学习模型。
与 NVIDIA 产品管理总监 Amit Goel 一起参加Imagine 2023 基调。了解行业对人工智能和机器学习的见解,以及NVIDIA Omniverse 和 Omniverse 复制器。
通过订阅电子报,并继续关注我们 Instagram, Medium和 Twitter。有关更多资源,请查看我们的 论坛。




