大语言模型(LLM)因其前所未有的规模理解和处理人类语言的能力,在全球引发轰动,改变了我们与技术互动的方式。
经过大量文本语料库的训练, LLM 可以在没有太多指导或训练的情况下为各种应用程序操作和生成文本。但是,生成的输出的质量在很大程度上取决于您给模型的指令,即提示。这对你来说意味着什么?如今,与模型交互是设计提示的艺术,而不是设计模型架构或训练数据。
考虑到构建和培训模型所需的专业知识和资源,处理 LLM 可能会付出代价。NVIDIA NeMo 提供了预训练的语言模型,可以灵活地适应几乎所有的语言处理任务,同时我们可以完全专注于从可用的 LLM 中获得最佳输出。
在本文中,我讨论了一些可以充分利用 LLM 的方法。要了解更多关于如何开始使用 LLM 的信息,请参阅《大型语言模型介绍:提示工程和 P-Tuning》。
提示背后的机制
在我进入生成最佳输出的策略之前,请退后一步,了解当您提示一个模型时会发生什么。提示被分解为称为令牌的较小块,并作为输入发送到 LLM ,然后 LLM 根据提示生成下一个可能的令牌。
符号化
LLM 将文本数据解释为令牌。标记是单词或字符块。例如,单词“ sandwich ”将被分解为标记“ sand ”和“ wich ”,而像“ time ”和“ like ”这样的常见单词将是单个标记。
NeMo 使用字节对编码来创建这些令牌。提示被分解为一个令牌列表,这些令牌被 LLM 作为输入。
一代
在窗帘后面,模型首先生成逻辑学家对于每个可能的输出令牌。 Logits 是一个函数,表示从 0 到 1 的概率值,以及从负无穷大到无穷大的概率值。然后,这些 logits 被传递到 softmax 函数,为每个可能的输出生成概率,从而在词汇表中给出概率分布。以下是用于计算令牌的实际概率的 softmax 方程:
在该公式中,是的概率
给定先前令牌中的上下文 (
到
和
是神经网络的输出
然后,模型将选择最有可能的单词并将其添加到提示序列中。

当模型决定什么是最可能的输出时,你可以通过上下转动一些模型参数旋钮来影响这些概率。在下一节中,我将讨论这些参数是什么,以及如何调整它们以获得最佳输出。
调整参数
为了释放 LLM 的全部潜力,探索提炼输出的艺术。以下是需要考虑调整的关键参数类别:
- 让模型知道何时停止
- 可预测性与创造性
- 减少重复
利用这些参数,找出适合您特定用例的最佳组合。在许多情况下,对温度参数进行实验可以获得您可能需要的结果。然而,如果您有一些特定的东西,并且希望对输出进行更精细的控制,请开始尝试其他的。
让模型知道何时停止
有一些参数可以指导模型决定何时停止生成任何进一步的文本:
- 代币数量
- 停止文字
代币数量
前面,我提到 LLM 的重点是在给定令牌序列的情况下生成下一个令牌。该模型在将预测的令牌附加到输入序列的循环中完成这一操作。你不会希望 LLM 继续下去。
虽然 NeMo 模型目前可以接受的令牌数量在 2048 到 4096 之间是有限制的,但我不建议达到这些限制,因为模型可能会产生偏离响应。
停止文字
停止文字是一组字符序列,告诉模型停止生成任何附加文本,即使输出长度尚未达到指定的标记限制。
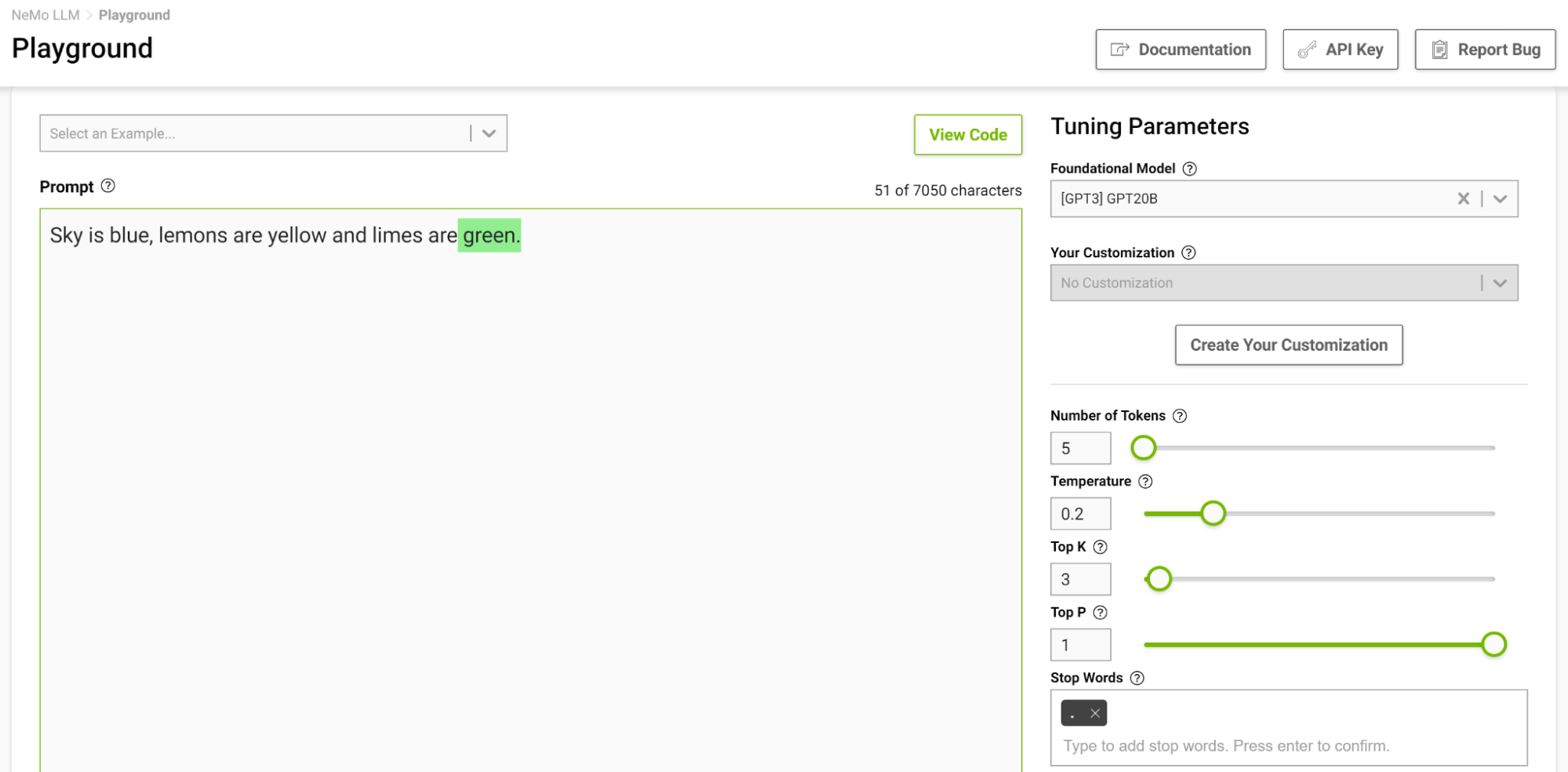
这是控制输出长度的另一种方法。例如,如果提示模型完成下面的句子“ Sky is blue , lemons is yellow and limes are ”,并且您将停止词指定为 just “.”,则模型在完成这句话后停止,即使令牌限制高于生成的序列(图 2 )。
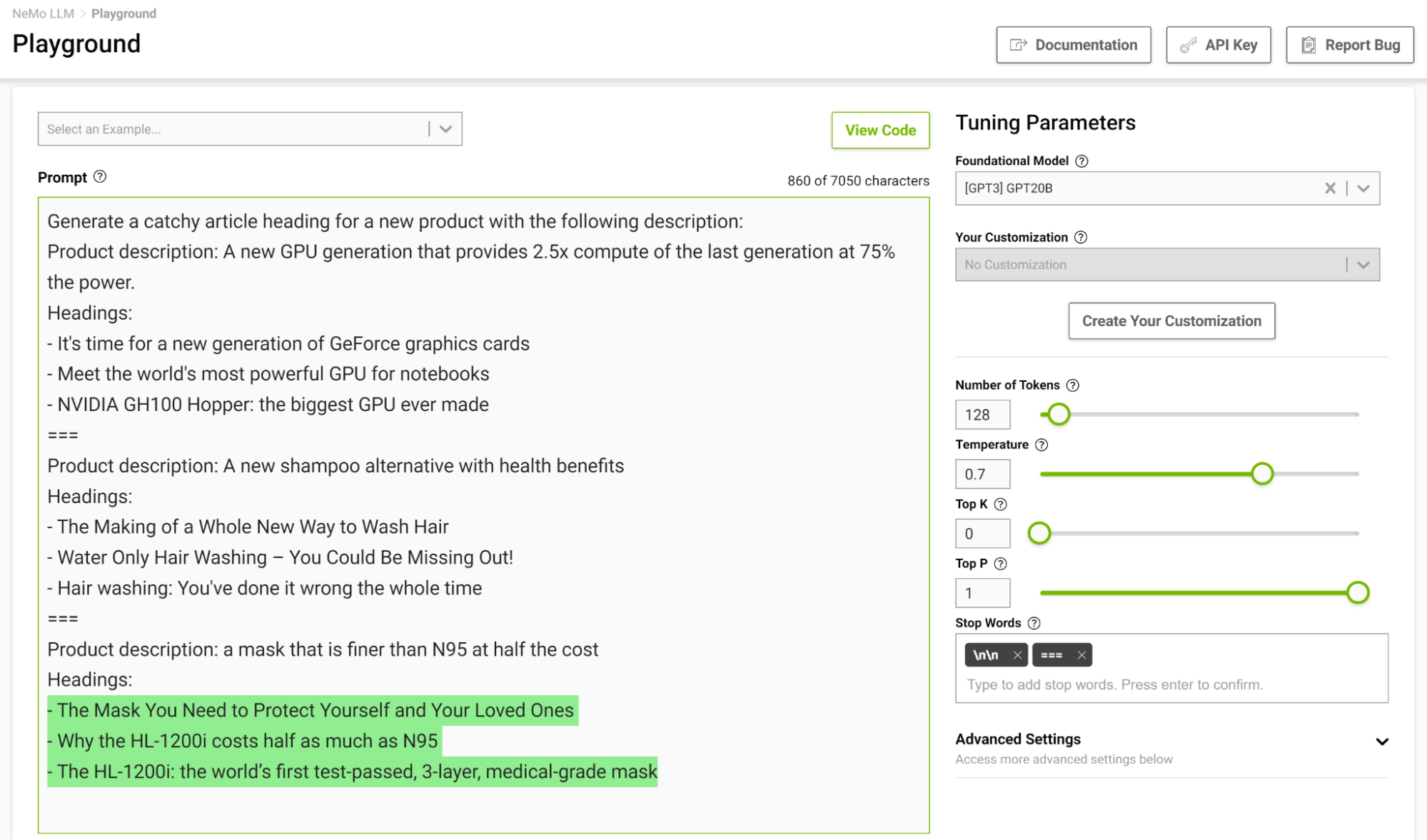
在几个镜头设置中设计一个停止模板尤其有用,这样模型就可以在完成预期任务时学会适当地停止。图 3 显示了用字符串“===”分隔示例,并将其作为停止字传递。
可预测性与创造性
如果有提示,可以根据您设置的参数生成不同的输出。基于 LLM 的应用,您可以选择增加或减少模型的创新能力。以下是一些可以帮助您做到这一点的参数:
- 温度
- Top-k 和 Top-p
- 波束搜索宽度
温度
此参数控制模型的创作能力。如前所述,在生成输入序列中的下一个令牌时,该模型会得出概率分布。温度参数可以调整这种分布的形状,从而使生成的文本更加多样化。
在较低的温度下,该模型更保守,并且仅限于选择具有较高概率的令牌。随着温度的升高,这个限制变得宽松,允许模型选择可能性较小的单词,从而产生更不可预测和更有创意的文本。
图 4 显示了让模型完成从“海洋”开始的句子,在这里你将温度设置为 0 . 1 。
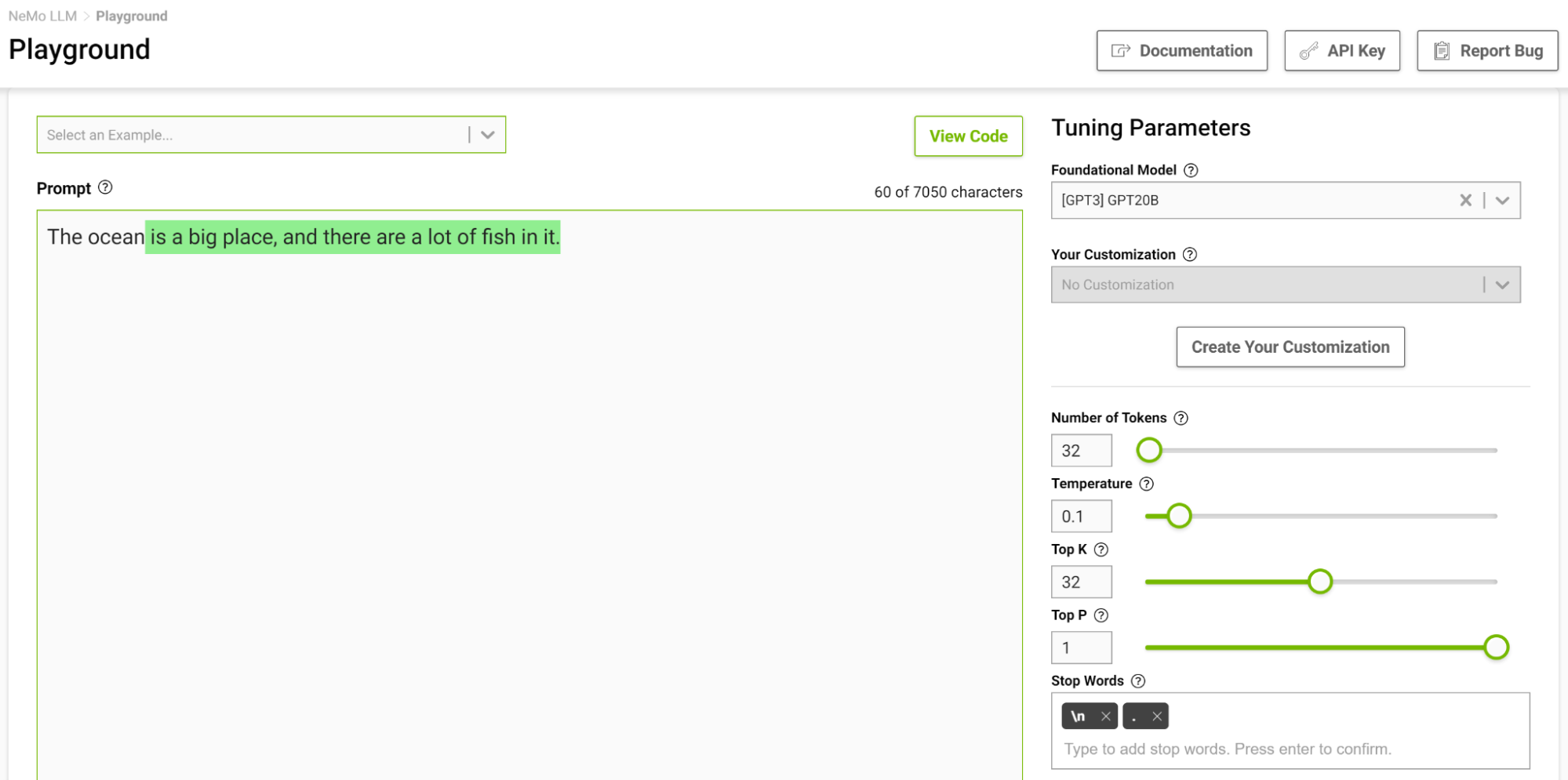
当你想到完成这样一个短语时,你可能会想到像“…是巨大的”或“…是蓝色的”这样的短语。产量很简单,海洋很大,有很多鱼。
现在,在温度设置为 1 的情况下再次尝试此操作(图 5 )。
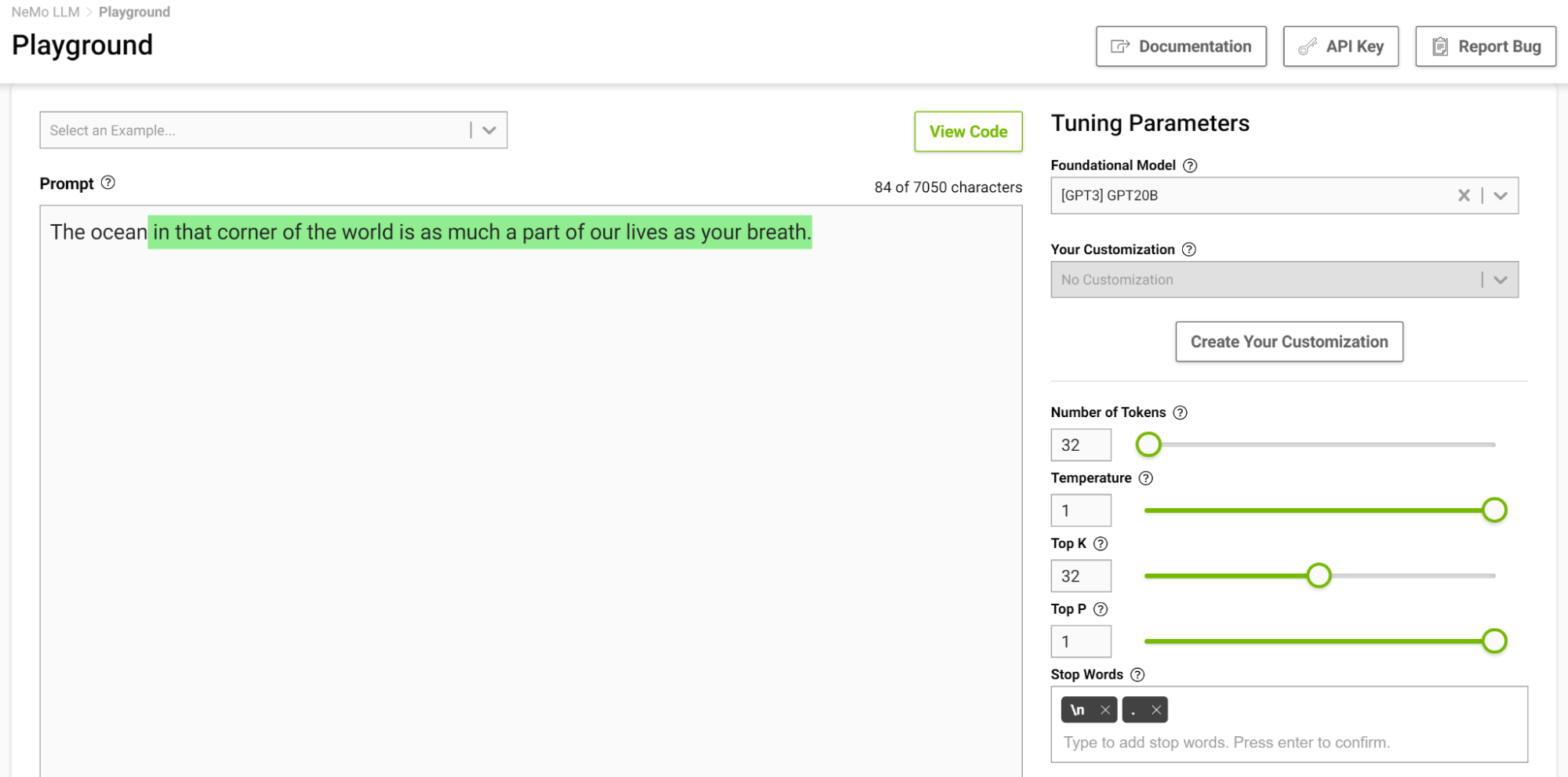
这个模型开始给你一些你通常不会想到的类比。较高的温度适用于诗歌和故事等需要创造性写作的任务。但要注意,生成的文本有时也会变得毫无意义。较低的温度适用于更明确的任务,如问答或总结。
我建议使用不同的温度值进行实验,以找到适合您的用例的最佳温度。范围[0.5, 0.8]应该是 NeMo 服务游乐场的一个良好起点。
Top-k 和 Top-p
这两个参数还控制选择下一个令牌的随机性。 Top-k 告诉模型它必须保持顶部k最高概率令牌,从中随机选择下一个令牌。较低的值会减少随机性,因为您正在剪切生成可预测文本的可能性较小的令牌。如果k如果设置为 0 ,则不使用 Top-k 。当设置为 1 时,它总是会选择下一个最可能的令牌。
在可能存在许多令牌的情况下,可能的令牌的概率分布可能很广。也可能存在分布狭窄的情况,其中只有少数代币更有可能。
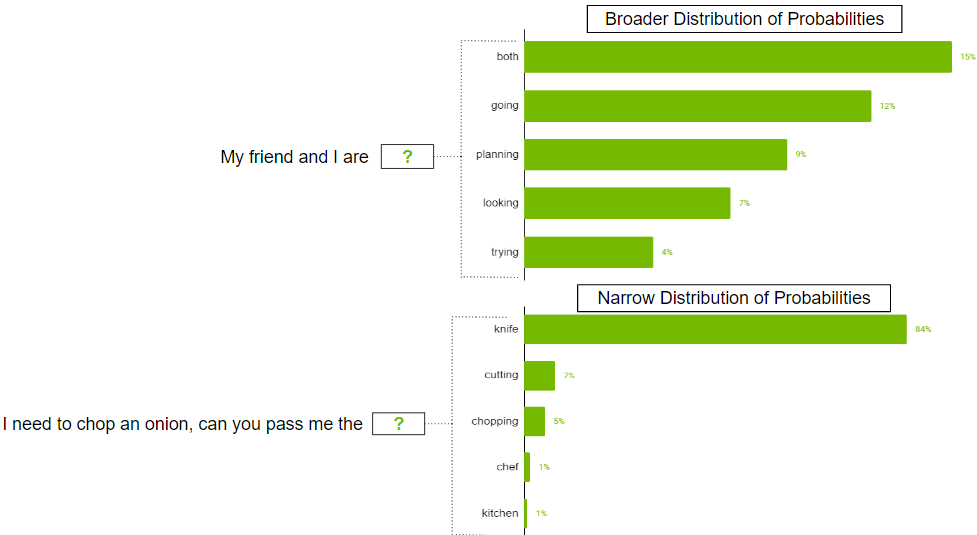
你可能不想严格限制模型只选择顶部k更广泛的分发场景中的令牌。为了解决这一问题,可以使用参数 top-p ,其中模型从概率总和等于或超过 top-p 值的最高概率令牌中随机挑选。如果 top-p 设置为 0 . 9 ,则可能出现以下情况之一:
- 在更广泛的分布示例中,它可以考虑概率之和等于或超过 0 . 9 的前 50 个令牌。
- 在窄分布场景中,仅使用前两个令牌可能会超过 0 . 9 。通过这种方式,您可以避免从随机代币中挑选,同时仍然保留多样性。
波束搜索宽度
这是另一个有用的参数,可以控制输出的多样性。波束搜索是许多 NLP 和语音识别模型中常用的一种算法,作为在给定可能选项的情况下选择最佳输出的最终决策步骤。波束搜索宽度是一个参数,用于确定算法在搜索的每个步骤中应该考虑的候选数量。
更高的值增加了找到良好输出的机会,但这也以更多的计算为代价。
减少重复
有时,输出中可能不希望出现重复的文本。如果是这种情况,请使用重复惩罚参数来帮助减少重复。
重复处罚
此参数可以帮助根据令牌在文本(包括输入提示)中出现的频率来惩罚令牌。已经出现五次的代币比只出现一次的代币受到的处罚更重。值为 1 意味着没有惩罚,大于 1 的值会阻止重复的令牌。
有效提示设计的少数射击策略
及时的设计对于 LLM 产生相关和连贯的输出至关重要。制定有效的提示设计策略可以帮助创建相关的提示,同时避免偏见、歧义或缺乏特异性等常见陷阱。在本节中,我将分享一些有效提示设计的关键策略。
带约束提示
通过仔细的提示设计来约束模型的行为可能非常有用。你知道,语言模型的核心是试图预测序列中的下一个单词。语言模型可能无法理解对人类来说完全有意义的任务描述。这就是为什么少镜头学习通常效果良好的原因:当你向模型演示一个模式时,它很好地遵守了它。
考虑以下提示:“将英语翻译成法语:今天是美好的一天。”
有了这个提示,模型可能会尝试继续句子或添加更多句子,而不是进行翻译。将提示更改为“将此英语句子翻译成法语:今天是美好的一天”。这增加了模型将此任务理解为翻译任务的可能性,并生成更可靠的输出。
角色很重要!
正如您在前面的翻译示例中看到的,微小的更改可能会导致不同的输出。另一件需要注意的事情是,令牌通常是用前导空格生成的,所以空格和下一行等字符也会影响您的输出。如果提示不起作用,请尝试更改其结构方式。
考虑某些短语
通常,当你想让你的模型合乎逻辑地回答你的提示并得出准确的结论,或者只是为了让模型取得一定的结果时,你可以考虑使用以下短语:
- 让我们一步一步地思考:这鼓励模型以逻辑的方式处理问题并得出准确的答案。这种提示方式也称为思想促进链( CoT )。
- 以<名人>的风格:这与这位名人的写作风格相匹配。例如,要生成像莎士比亚或埃德加·艾伦·坡这样的文本,将其添加到提示中,生成的文本将与他们的写作风格紧密匹配。
- 作为<职业/角色>:这有助于模型更好地理解问题的上下文。有了更好的理解,模型通常会给出更好的答案。
用生成的知识提示
为了获得更准确的答案,您可以在生成最终答案之前提示 LLM 生成关于给定问题的潜在有用知识(图 7 )。

这种类型的错误表明 LLM 有时需要更多的知识来回答问题。下面的例子展示了在几杆的情况下生成关于高尔夫得分的一些事实。
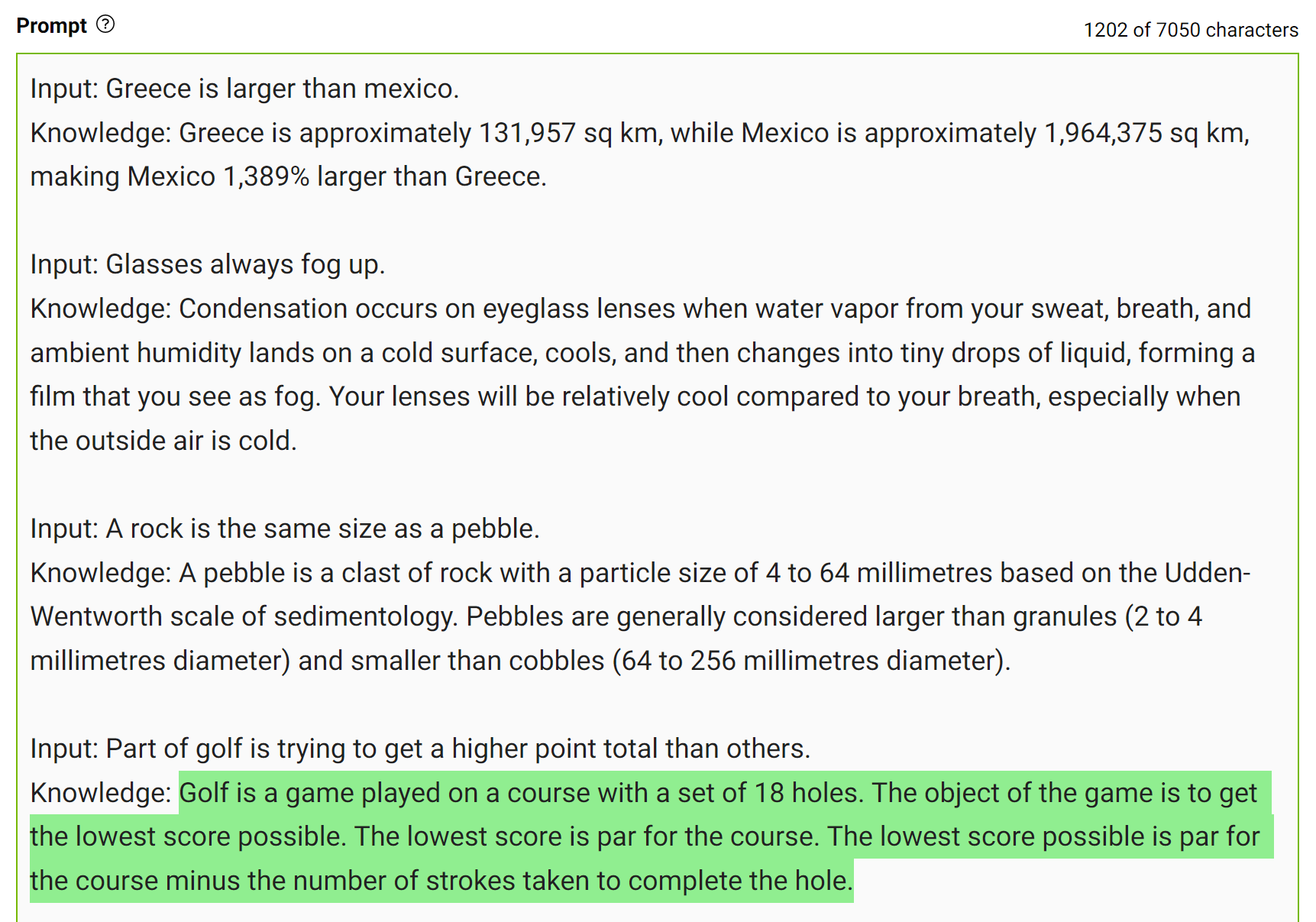
将这些知识整合到提示中,然后再次提问。
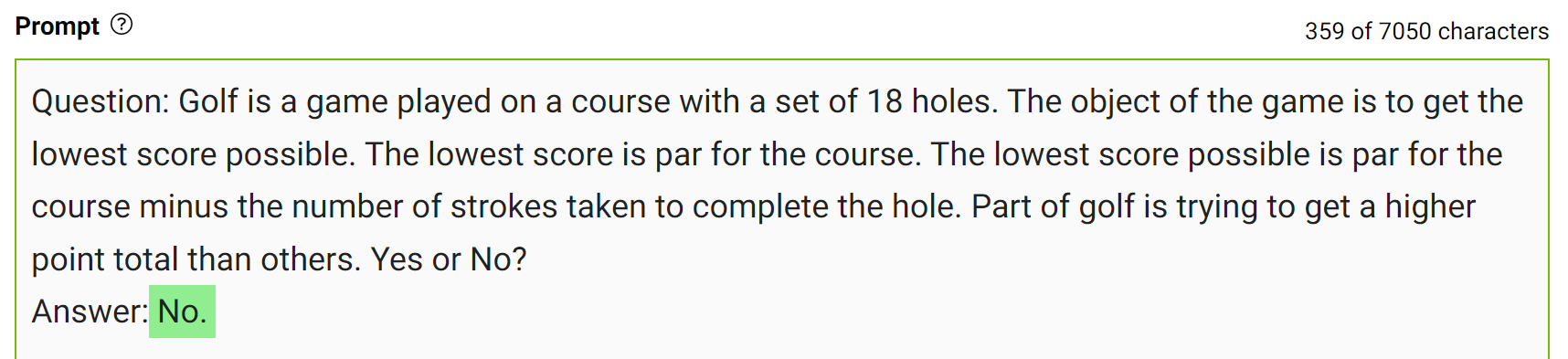
对于同样的问题,模特自信地回答“不”。这是一个简单的演示,但在得出最终答案之前,还有更多的细节需要考虑。更多详细信息,请参阅 Generated Knowledge Prompting for Commonsense Reasoning。
在实践中,您生成多个答案,并选择最频繁出现的答案作为最终答案。
试试看!
编写适合您的用例的提示的最好方法是进行实验和尝试。设计一个可以为您提供正确输出的提示是一种学习体验,无论是如何编写,还是如何设置模型参数。
如果您想进入 NeMo 服务游乐场,可以帮助您测试提示并设计用例,请参阅 NVIDIA NeMo Service。
结论
在这篇文章中,我分享了从 LLM 生成更好输出的方法。我讨论了如何调整模型参数以获得所需的输出,以及一些设计提示的策略。
注册了解 LLM 技术、学习和突破的最新情况,请订阅 LLM newsletter。