
当您在网页上看到与上下文相关的广告时,它很可能是由 Taboola 数据管道提供的内容。作为世界领先的内容推荐公司, Taboola 面临的一大挑战是经常需要扩展 Apache Spark CPU 集群容量,以满足不断增长的计算和存储需求。
数据中心容量和硬件成本总是面临压力。
是什么导致了扩展挑战? Taboola 使用一个复杂的数据管道,从用户浏览器或移动设备延伸到多个数据中心。部署了复杂的深度学习算法、数据库、基础设施服务(如 Apache Kafka )和数千台服务器,为世界各地的用户提供最合适的广告。
这篇文章描述了 Taboola 加入 RAPIDS Apache 加速器 Spark 以优化处理成本的动机,以及对迁移过程、挑战和迄今为止吸取的经验教训的见解
满足计算需求的管道面临的挑战
要计划解决方案,您必须充分了解问题的严重性。在提供广告内容时, Taboola 构建了一个独特的页面视图其识别每个用户及其与系统的交互。页面视图是一种大而宽的数据结构,使用全球数据中心收集的数据构建在一个巨大的 CPU 集群中。该结构包含 1500 多个不同的列,总计超过 1 TB 的每小时数据,所有这些数据都在我们的 Apache Spark CPU 集群中处理。
许多不同的分析器和 SQL 查询以每小时 1 TB 的原始数据的速度处理传入的页面视图,并以 2 、 6 、 12 和 48 小时的速度进行追赶。不断创建新的分析器,以增加 Apache Spark 集群的负载。人们越来越需要更多的计算能力。
我们的主要任务是使需要计算的复杂管道更具可扩展性,同时具有成本效益。为了应对这一挑战, Taboola 开始努力将数千个 CPU 核心迁移到 GPU ,以帮助我们应对不断增加的待处理数据负载。
我们考虑的一个加速 Taboola 的 Apache Spark 环境的工具是 GPU 上的 RAPIDS 加速器。因此,与 CPU 相比,尝试在 GPU 上实现更大的可扩展性是一个自然的决定
主要注意事项
首先,我们定义了成功迁移数千个 CPU 核心以利用 GPU 加速所需的测试内容:
- 真实生活数据集
- 硬件规格
- 最小 X 系数
- 复杂查询测试
真实生活数据集
我们使用 Cyber Monday 的真实生产数据来测试和基准测试一个大型数据集。数据是每小时 1 . 5 TB 的 ZSTD 压缩 Parquet 文件。它有 1500 多个所有本机类型的列,包括数组、结构和带数组的嵌套结构。
硬件规格
对于硬件,我们从以下资源开始:
- 具有三个 A30 GPU 的 72 CPU 核心 Intel 服务器
- 一个 900-GB 的本地 SSD 驱动器,用于 Apache Spark 存储其中间文件
- 380 GB 内存
- 10 Gb / s NIC 卡
最小 X 系数
将项目从 CPU 迁移到 GPU 时的主要问题通常是,“ X 因素是什么?”对于具有多个 GPU ‘的真实世界集群,问题是,“我需要多少 GPUXCPU 芯?”答案是你的 X 因素。
我们为 GPU 解决方案设置了一个 X 因子为 3 的最小条,在成本方面被认为是成功的。这一因素有助于保证我们的移民努力会得到回报。
复杂查询测试
我们从多个研发部门的生产中挑选了 15 个查询,与生产中的数百个查询一样多。
查询大多很复杂,包括许多 SQL 操作:
- 聚合
- 排序
- 横向视图爆炸
- 分发者
- 窗口功能
- UDFS
图 1 显示了一个示例查询。
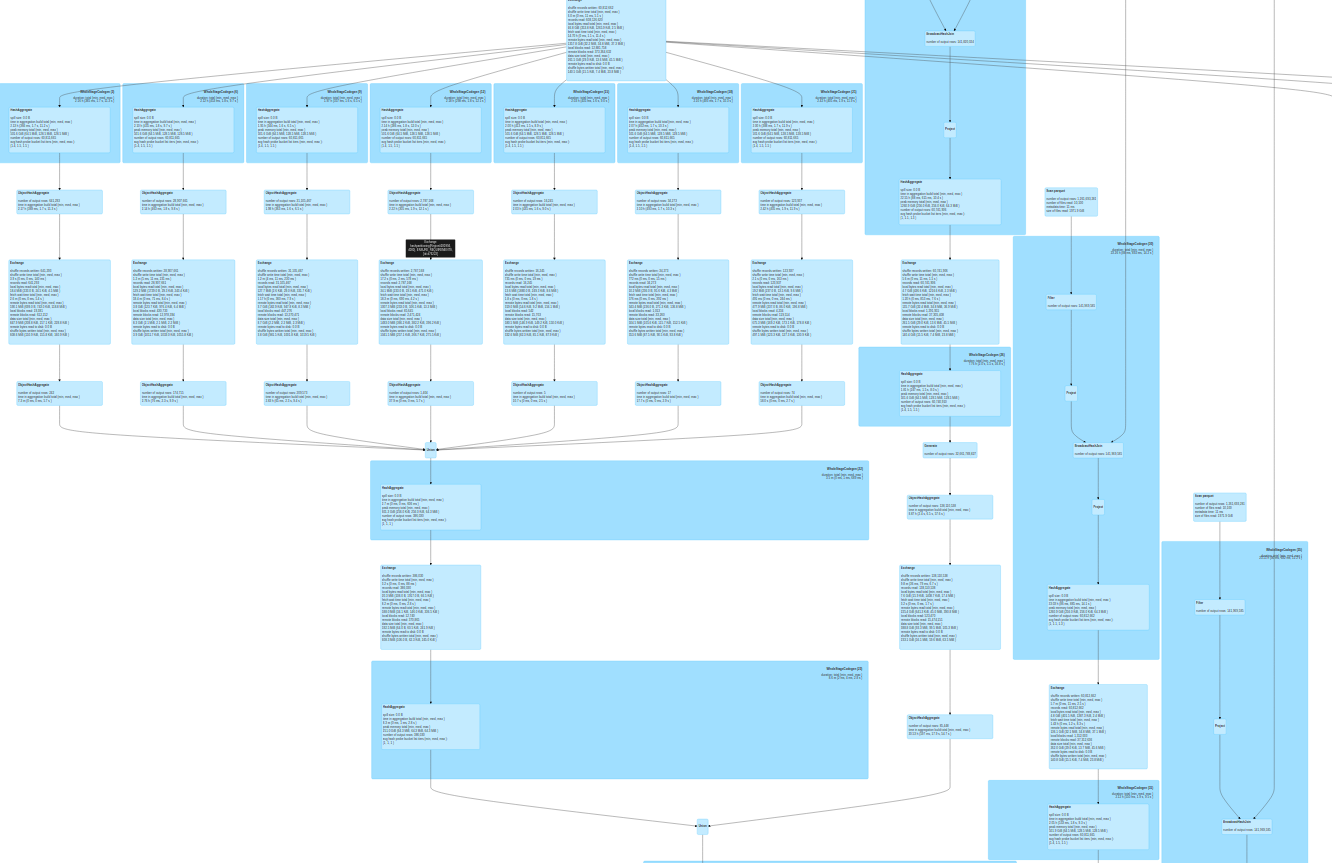
表 1 显示了 Taboola 的因素。
| 分析仪名称 | 平均生产时间 CPU | 平均 GPU 时间 | GPU 因子 |
| 播发器维度(按请求) | 586 . 41 | 31 . 91 | 18 . 38 |
| 经验分析页面 | 3021 . 6 | 102 . 92 | 29 . 36 |
| 经验分析安置 | 680 . 84 | 47 . 12 | 14 . 45 |
| 实验分析请求库 | 6605 . 44 | 362 . 68 | 18 . 21 |
| 实验分析会话 | 207 . 87 | 23 . 01 | 9 . 03 |
| 媒体数据趋势数据库 | 222 . 94 | 9 . 8 | 22 . 75 |
| 性能测量 | 397 . 17 | 86 . 22 | 4 . 61 |
| 发布者性能 | 965 . 63 | 108 . 95 | 8 . 86 |
| RBoxAB 测试 | 63 . 04 | 2 . 4 | 23 . 88 |
| 每小时由主人狂欢 | 487 . 44 | 95 . 03 | 5 . 13 |
| SlaUnit 可用填充率 | 1199 . 93 | 152 . 38 | 7 . 87 |
| 供应数据趋势 | 529 . 92 | 45 . 28 | 11 . 7 |
CPU 到 GPU 迁移目标
我们从能够扩展到多 GPU 和多服务器集群的单个服务器(如前所述)开始。该集群将由 Kubernetes 管理,而不是目前的 Mesos 集群。 Mesos 即将过时, NVIDIA 环境支持 Kubernetes 。
软件和硬件环境中的任何更改都必须忽略 Taboola 的代码。在 GPU 上运行的查询应该以 CPU 的确切结果执行。该团队意识到了这一挑战,因为生产稳定性是一个关键目标。
最后,我们希望 GPU 的性能优于 CPU ,最小系数为 3 。我们对几个 GPU 进行了基准测试,包括 NVIDIA P100 、 NVIDIA V100 、 NVID IA A100 和 NVIDIA A30 。我们了解到 A30 GPU 为我们提供了最佳性价比。
RAPIDS 加速器首次实验
我们使用 RAPIDS 加速器运行 SQL 查询,结果有些令人失望。一些不太复杂的查询,主要是横向视图爆炸,给出了 CPU 的 3x 到 5x 因子。一些查询显示的因子要低得多,而其他查询则崩溃了。
在 RAPIDS GitHub 回购中提出问题后,我们尝试了相关的 Apache Spark 和 RAPIDS 加速器参数,并开始看到更好的结果:
sql.files.maxPartitionBytes: CPU 使用 128 MB 的默认值。这对于 GPU 来说太低了。我们使用的是 1 – 2 GB 。sql.shuffle.partitions:我们发现在大多数情况下, 200 的默认值就足够了。rapids.sql.concurrentGpuTasks:确定可以在 GPU 上同时运行的任务数。至少两项任务似乎是最好的。
调整这些参数可以帮助查询更平稳地运行,在某些情况下性能更佳。此外,NVIDIA 加速 Spark 分析工具可以自动生成调整建议。
挑战# 1 – Parquet 解析开销
我们在一些性能较差的 SQL 查询中遇到了瓶颈,其中大多数查询在解析 CPU 上的 Parquet 页脚数据时都浪费了时间。 Parquet 数据包含 1500 多列。很明显,用于解析页脚的常规 Java 代码对于如此大的页脚来说是不够的。
图 2 显示了 9 秒 Apache Spark 任务的 NVIDIA 探查器输出的一小部分,其中 GPU 大部分处于空闲状态(仅工作 330ms )

图 3 显示了遭受这种行为的查询的火焰图。紫色条表示在org.apache.parquet.hadoop.ParquetFileReader班当 GPU 空闲时,几乎 50% 的查询时间都花在了解析 Parquet 的页脚上。
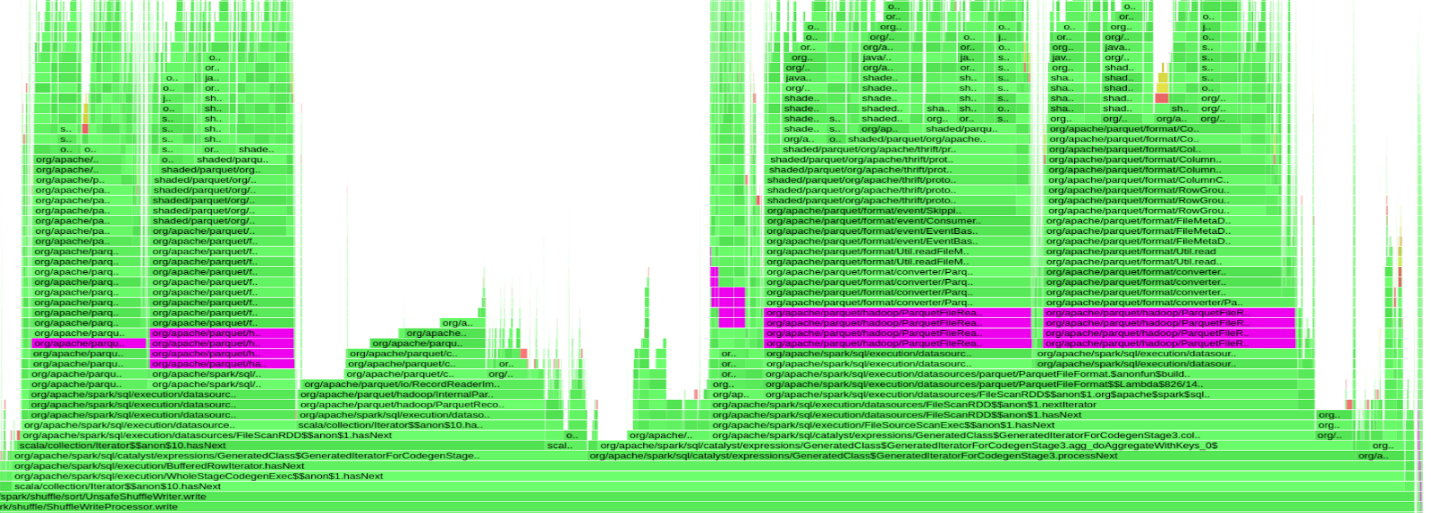
因此,我们开始测试另一种解决方案。在解析页脚时, Parquet 代码会对每个行组的页脚元数据进行串行迭代。我们调整了 Parquet 参数以减少每个文件中的行组数量。这给了我们大约 10-15% 的改善。我们发现这种改进是不够的。
每次读取元数据时,即使每次查询只要求 50-100 列,也会连续读取和解析所有 1500 列元数据。我们想索引页脚元数据,这样我们就可以直接访问它,而不是串行读取整个 1500 个数据列。我们通过改变Parquet-mrC ++和 Java 中的公共代码。尽管我们得到了不错的性能结果,但这太麻烦和复杂了。
幸运的是, NVIDIA RAPIDS 团队有一个更好的想法。解决方案是优化 Parquet 文件解析。他们用 Arrow 的 C ++实现取代了 Java 代码。我们现在有了rapids.sql.format.parquet.reader.footer.type 对于我们的 GPU 实现,默认设置为 NATIVE 。瓶颈已经解决,由于 CPU 上的页脚解析开销, GPU 不再有空闲的查询。
挑战# 2 –网络瓶颈
一个薄弱的网卡导致了下一个瓶颈。当 10 Gb / s 以太网卡承受 CPU 负载时,它无法承受 GPU 负载
该解决方案是 GPU 负载的最佳网卡。将 10 Gb / s 以太网卡更换为 25 Gb / s 以太网卡消除了这一瓶颈。
挑战# 3 —磁盘 I / O 瓶颈
即使消除了这两个瓶颈,查询仍然运行缓慢。在 Apache Spark 用户界面上,我们看到了关于发生了什么的清晰指示。
| 公制 | 最小值 | 第 25 百分位 | 中值的 | 第 75 百分位 | 最大值 |
| 期间 | 0 . 4 秒 | 0 . 6 秒 | 0 . 8 秒 | 1 秒 | 1 . 2 分钟 |
| GC 时间 | 0 . 0 毫秒 | 0 . 0 毫秒 | 0 . 0 毫秒 | 90 . 0 毫秒 | 0 . 5 秒 |
| 无序读取大小/记录 | 214 毫巴/ 1000 | 22 . 3 毫巴/ 1000 | 22 . 5 毫巴/ 1000 | 22 . 7 毫巴/ 1000 | 27 . 3 毫巴/ 1000 |
| 无序写入大小/记录 | 175 毫巴/ 1000 | 17 . 9 毫巴/ 1000 | 18 毫巴/ 1000 | 181 毫巴/ 1000 | 181 毫巴/ 1000 |
| 计划程序延迟 | 3 . 0 毫秒 | 5 . 0 毫秒 | 5 . 0 毫秒 | 7 . 0 毫秒 | 3 秒 |
| 峰值执行内存 | 6400 万 | 6400 万 | 6400 万 | 6400 万 | 6400 万 |
| 无序写入时间 | 9 . 0 毫秒 | 13 . 0 毫秒 | 18 . 0 毫秒 | 21 . 0 毫秒 | 59 秒 |
在表 2 中最大值列中,任务的持续时间为 1 . 2 分钟,而无序写入时间耗时 58 秒。当 GPU 处于空闲状态时,大量时间被浪费在进行混洗工作上。
图 4 和图 5 显示了相应的事件时间线图。橙色部分表示读或写的混洗时间。绿色部分是计算时间。我们在阅读或编写 shuffle 文件时浪费了很多时间。
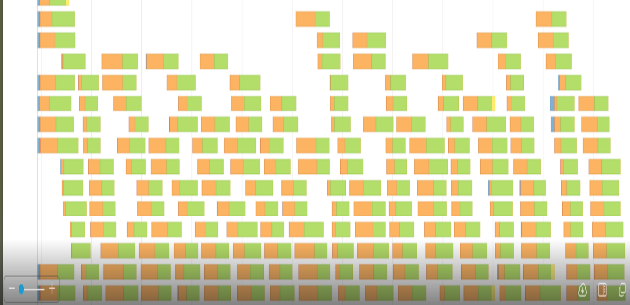
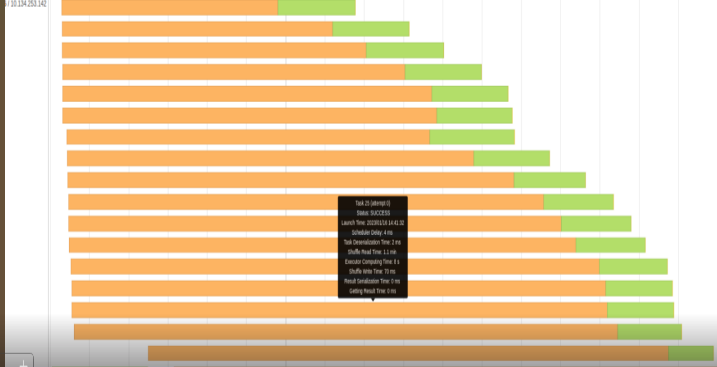
我们的 shuffle 文件在某些查询中可以达到 500 GB 甚至更高。我们显然无法将如此大量的数据保存在服务器的 RAM 中,因此 shuffle 文件存储在本地 SSD 驱动器中。
在与我们的团队进行快速调查后,我们发现 SSD 驱动器被配置为使用 RAID-1 。每个临时混洗文件被保存两次到磁盘。这浪费了很多时间,切换到 RAID-0 在一定程度上改善了这种情况。
GPU 比 CPU 对 SSD 驱动器施加了更大的压力,因此我们不得不用 NVMe 驱动器更换 SSD 。解决方案是切换到 6 TB NVMe 驱动器。我们删除了其中一个 GPU ,为 NVMe 驱动器创建了一个插槽。之后,我们没有出现混洗读写性能问题。我们还了解到,一个 NVMe 驱动器可以承受两个 A30 GPU 的工作负载。
迁移到 Kubernetes
因为我们的 Mesos 集群将变得过时,所以必须从独立的 POC 机器迁移到 Kubernetes 。这涉及到大量的配置工作和其他次要工作。尽管如此,实施起来还是很简单。
其基本思想是 Apache Spark 驱动程序位于非 GPU 机器上,而每个 K8s Pod 将与单个 GPU 相关联。想要了解更多信息,请访问 RAPIDS 和 Kubernetes 的入门指南。
下面的代码示例展示了一些主要的相关 Kubernetes 配置。
spring:
profiles:
include: spark_k8s_extra_files
spark:
driver:
sparkConnector:
sparkOpts:
spark.kubernetes.container.image.pullPolicy: Always
spark.kubernetes.authenticate.serviceAccountName: spark
spark.kubernetes.executor.deleteOnTermination: true
spark.deploy.mode: client
spark.executorEnv.preLoadMemoryLibraryName: "/usr/libjemalloc.so"
spark.executorEnv.xmxPercentage: 80
spark.kubernetes.memoryOverheadFactor: 0.1
spark.mesos.fetcherCache.enable: false
spark.executor.extraJavaOptions:
-XX:-UsePerfData
-XX:-OmitStackTraceInFastThrow
-verbose:gc
-XX:+UseParallelGC
-XX:+UseParallelOldGC
-XX:+PrintFlagsFinal
-Dmapreduce.fileoutputcommitter.algorithm.version=2
-XX:NativeMemoryTracking=detail
spark.plugins: "com.nvidia.spark.SQLPlugin"
spark.kubernetes.executor.podTemplateFile: /conf/k8GPUPodTemplateProduction.yml
spark.executor.resource.gpu.vendor: "nvidia.com"
spark.executor.resource.gpu.discoveryScript: /conf/getGpusResources.sh
spark.executor.resource.gpu.amount: 1
# GPU task configuration
spark.rapids.sql.variableFloatAgg.enabled: "true"
spark.rapids.sql.castFloatToDecimal.enabled: "true"
spark.rapids.sql.rowBasedUDF.enabled: "true"
spark.rapids.sql.format.parquet.reader.footer.type: "NATIVE"
spark.rapids.sql.explain: "all" # For debug.
# Most common
spark.rapids.sql.concurrentGpuTasks: 4
spark.sql.files.maxPartitionBytes: "2048m"
spark.rapids.sql.batchSizeBytes: "1g"
spark.sql.shuffle.partitions: 200
要加速多少 GPU ?
如果目标是使用 GPU 比 CPU 更经济高效地加速工作负载,那么我们首先必须了解 GPU 的速度有多快。我们用两个 A30 GPU 建立了一个测试系统,并将生产数据与我们的大型 CPU 核心生产环境并行传输到该系统。
图 6 显示了在生产 CPU 集群上以及在具有两个 A30 GPU 的服务器上运行的两个最重的查询。
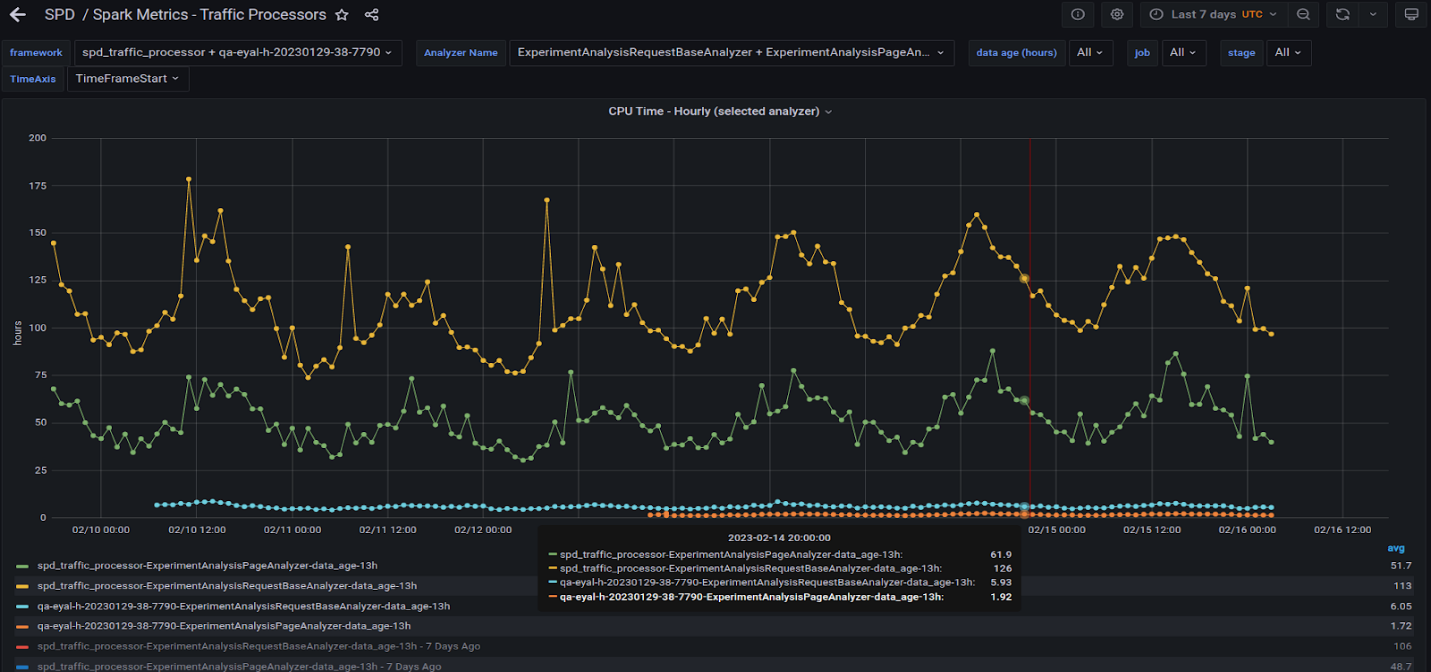
黄线和绿线表示 CPU 集群上运行的两个查询的所有任务编号的每小时总时间。蓝色和橙色线表示在 GPU 服务器上运行的相同查询。 GPU 因子为 20 倍或更高。
图 7 显示了在图 6 所示的 GPU 上运行的两个查询。观察到它们的行为与 CPU 相似,因为波峰和波谷在一天中的不同时间大致对齐。
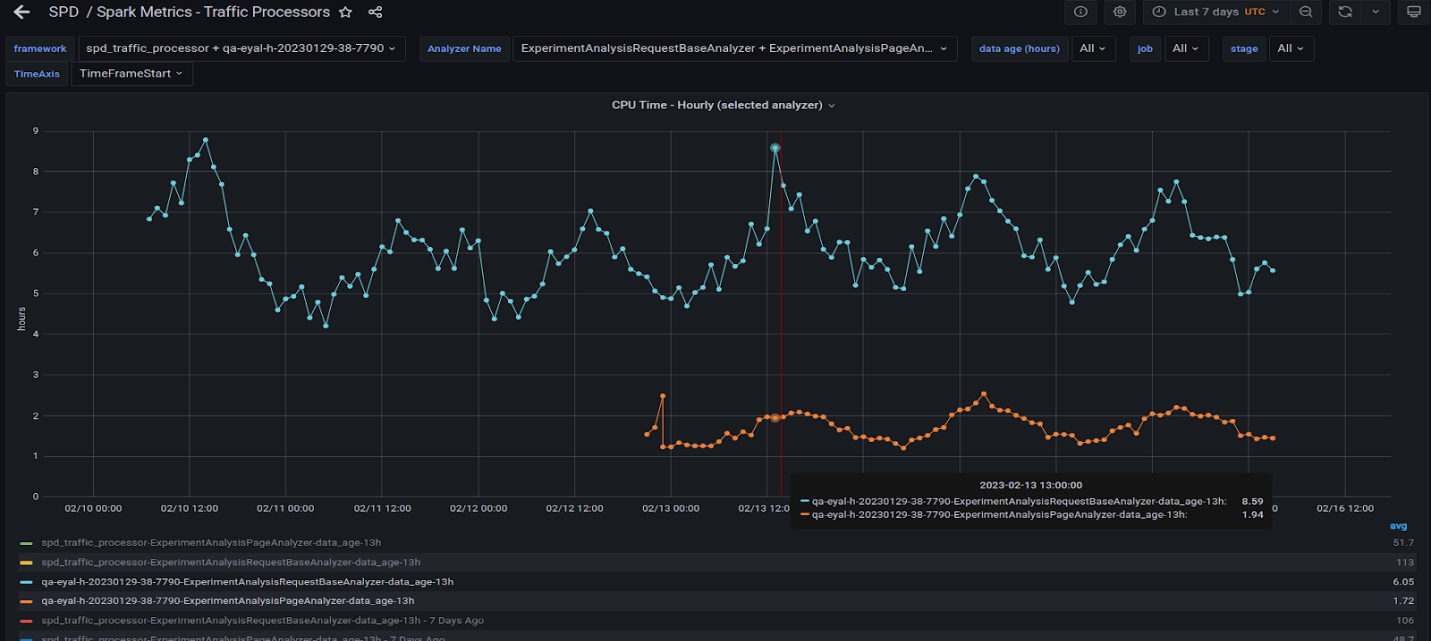
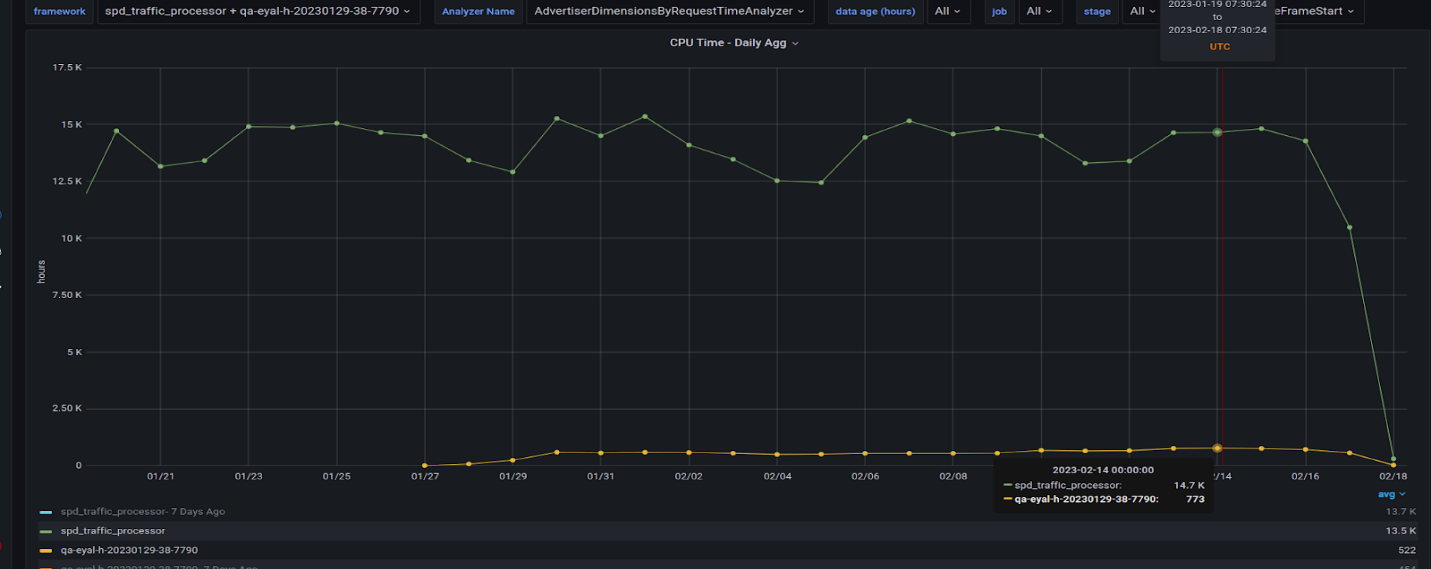
图 8 很有趣,因为它显示了我们迁移到 GPU 的所有查询及其在 CPU 上的对应查询的因子。 GPU 运行缺少最大的查询,我们仍在将其迁移到 GPU 。这可能会使 GPU 的总时间每天增加 200 小时。
经验教训
展望我们的下一步迁移步骤, Taboola 希望将查询从其他研发部门转移到 GPU ,从而在生产中产生更多的 GPU 。这意味着 QA 必须在生产过程中更密切地监控系统。
熟悉 RAPIDS Apache 加速器 Spark 是一项令人惊叹的“快乐之旅”。从处理 Parquet 文件到将 GPU 推向极限,我们在处理大型数据管道以及管理数据中心容量和硬件成本方面变得更加得心应手。用这种方法识别和应对硬件限制被证明是有益的。
以下是 Taboola 为那些考虑 CPU 到 GPU 迁移的人提供的最重要的收获:
- 在具有多个变量的复杂环境中调整参数从来都不是一件简单的事。尽可能将此任务自动化。使用 NVIDIA Accelerated Spark 分析工具来帮助解决这一挑战可能是个好主意,因为它可以很容易地建议优化的参数。
- 超越 CPU 和 GPU 寻找瓶颈的解决方案。再多的 GPU 马力也无法解决基本上与网络、磁盘、带宽或配置和解析相关的问题。
- 多个 GPU 并不妨碍性能,但 GPU ‘非常强大,因此您可能会使用比最初想象的更少的 GPU 来获得良好的性能。最好对此进行测试以降低成本。
- 我们通过 RAPIDS 加速器和 NVIDIA GPU 实现了我们的 20 倍因子。最大的教训是,在受益于 GPU 加速之前,我们需要更好地了解现有环境中发生了什么。一个 A30 GPU 在某些工作负载下保持与~ 200- CPU 核心测试集群相同的生产负载。
想要了解如何在基于 Apache Spark CPU 的环境中实现性能倍数的更多信息,请访问 GPU 加速 Apache Spark。
鸣谢
在两个伟大群体的支持、援助和耐心下,我们的巨大努力更加成功。在塔布拉:安德烈·古林、吉拉德·扎莫钦斯基、伊戈尔·伯曼、科伦·科西亚、利奥尔·查加和迈克尔·塔拉诺夫。 NVIDIA RAPIDS 团队成员: Alessandro Bellina 、 Hao Zhu 、 Karthikeyan Rajendran 、 Robert Evans 和 Sameer Raheja 。




