从细胞新陈代谢到工业制造,酶是众多过程的重要生物催化剂。应用人工智能生成酶是一个令人兴奋的研究领域,可直接应用于生命科学。在这些科学挑战中取得进展对于进一步推动药物研发、环境科学和生物工程的发展至关重要。
目前,地球上大量生命形式中只有一小部分进行了测序,这阻碍了机器学习算法在序列设计的复杂领域中的广泛应用和泛化。改进的功能标记方法是酶研究的重要组成部分,能够识别和表征新发现的酶的功能。这是了解复杂的生物过程和增强用于生成工作流程的数据的关键。
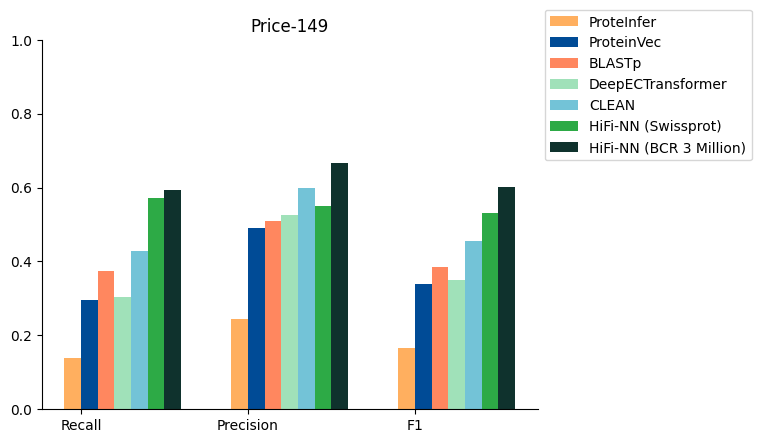
基地营研究,一家位于伦敦的 Bio-AI 公司,同时也是 NVIDIA 初创加速计划 的成员,最近利用 NVIDIA GPU 训练出了一种层次微调的最近邻方法(HiFi-NN)。这种方法在召回率、精确度和 F1 分数方面相较现有模型有显著提升,在酶标注任务上比先进的 SoTA 方法高出 15% 以上。
在全球探险活动中收集的独特数据
Basecamp Research 可以应对整个生物技术行业中最复杂的生物设计挑战。现有数据集存在重大缺陷:
- 代表性较小,仅涵盖了地球上 0.0001% 的生命形式
- 没有一致的元数据
- 在收集数据之前缺乏利益相关者的同意和参与
Basecamp 选择通过与五大洲和 23 个国家 地区的自然公园建立生物多样性合作伙伴关系来开发其专有的生物数据资源。他们派科学家进行全球探险,从最极端和非凡的生物群系中发现新的基因组、酶和生物关系。
在不到两年的时间里,他们创建了 BaseGraph,这是自然生物多样性的最大知识图,包含超过 55 亿个关系,每个蛋白质的基因组背景超过 70 千碱基。他们广泛的长读测序得到全面元数据收集的补充,使他们能够将感兴趣的蛋白质与特定反应和所需的工艺条件联系起来。
Basecamp Research 的 AI 策略以数据为中心,原因有二:其专有数据可在快速商业化的算法环境中增强模型性能,并显著弥补公开数据中缺乏多样性的问题。
他们从头开始构建的知识图捕获并重新创建了自然界中 40 亿年蛋白质进化的复杂性。这一数据优势使其 AI 和产品团队能够超越 SoTA 标注和设计模型,解决生物技术行业(从基因写入疗法到塑料降解)中的复杂设计挑战。
在虚拟模式下,函数标注
为了应对蛋白质和酶的硅功能标注挑战,Basecamp Research 的深度学习 (DL) 团队开发了 HiFi-NN 搜索工具。HiFi-NN 利用酶委员会 (EC) 编号来标注蛋白质序列,而目前首选的生物信息学工具是 blastp,此外还包括其他 SoTA DL 模型,例如 CLEAN,它们在精度和召回方面的表现见表 1。
| 方法 | 召回 | 精度 | F1 分数 |
| ECPred | 0.0197 | 0.0197 | 0.0197 |
| DEEPpre | 0.0403 | 0.0415 | 0.0386 |
| DeepEC | 0.0724 | 0.1184 | 0.0846 |
| ProteInfer | 0.1382 | 0.2434 | 0.1662 |
| ProteinVec | 0.2961 | 0.4901 | 0.3378 |
| BLASTp | 0.3750 | 0.5083 | 0.3852 |
| DeepECtransformer | 0.3026 | 0.5263 | 0.3511 |
| CLEAN | 0.4671 | 0.5844 | 0.4947 |
| HiFi-NN (Swissprot) | 0.5724 | 0.5505 | 0.5304 |
| HiFi-NN (Swissprot+300 万个精选序列) | 0.5921 | 0.6657 | 0.6015 |
BCR 3M 是指使用 Basecamp Research 的 BaseGraph 中 300 万个不同环境的序列重新训练的模型版本。
与顾问 Noelia Ferruz 和 Kevin Yang 合作开发的 HiFi-NN 在 2023 年 12 月的结构生物学机器学习研讨会上获得了著名 AI 会议 NeurIPS 的认可。
该模型使用 EC 编号的对比学习和用于自然增强的酶委员会标注系统的固有层次结构。该模型在 Lambda Labs 实例(CUDA 版本 11.8 和 NCCL 版本 2.14.3)上的 8 个 NVIDIA A100 GPU 上进行训练,采用 PyTorch Lightning 进行分布式数据并行训练。通过 Hydra 框架和 Weights and Biases 完成实验管理和跟踪。该模型拥有超过 300 万个参数。
HiFi-NN 在 SoTA 标注方法中的出色性能归功于使用 EC 编号系统中表示的酶功能的分层特性,以及使用 Basecamp 知识图中的专有序列补充训练集。
专有序列
作为对专有 Basecamp 序列的补充,HiFi-NN 来自五大洲的环境,oC 温度范围,以确保训练集中尽可能多的序列和环境多样性。因此,HiFi-NN 在基准测试数据集上的表现优于所有 SoTA 模型,并且在功能暗物质的蛋白质序列上的表现尤为出色,即那些与任何已知酶的相似性较低的序列。
实际上,Basecamp 团队利用 HiFi-NN 对MGnify数据库中之前未标注的微生物蛋白质进行了标注。
除了优于之前的所有标注模型外,HiFi-NN 还特别易于使用,并且能够快速生成标注标签。例如,它可以在单个 NVIDIA A100 GPU 上在 24 分钟内标注整个人类蛋白质组。
Johnson Matthey 的快速酶识别
HiFi-NN 等突破增强了我们预测生物实体物理性质的能力,旨在减少使用资源密集型实验室方法对候选对象进行广泛筛选的需求。
Basecamp Research 与 FTSE100 化学公司 Johnson Matthey 合作,强调了计算进步在应对行业挑战方面的重要性。在与该合作伙伴的一个项目中,研究人员在实验室花费了一年半的时间测试数千种酶变体,但未能取得成功。
Johnson Matthey 的目标是找到能够处理多个大型底物的具有广泛特异性的酶,与处理较小的底物相比,这项任务更加复杂。在一周内,Basecamp Research 完全采用了硅技术来识别符合这些标准的酶(图 2),从而将其定位为潜在的商业化。
该研究团队的负责人对 Basecamp Research 快速发现和开发一种酶的能力表示赞赏,这是他们多年来一直无法完成的任务。这一成功为扩大各种酶开发计划的协作努力奠定了基础。
推动生命科学领域的 AI 发展
功能标注对研究人员发挥着关键作用,尤其是在以下实际场景中:
- 在药物研发中,它通过阐明体内的酶相互作用来帮助创建有针对性的治疗方法。
- 在工业生物技术领域,它支持针对特定工业应用定制的酶设计,从而推广更环保的生产方法。
- 它还通过揭示不同物种中酶的发展轨迹,提供了有关进化生物学的重要见解。
从本质上讲,由机器学习驱动的功能标记超越了单纯的科学工具的作用。它是医疗健康和环境科学等各行各业创新和探索的催化剂。
Basecamp Research 与其他生命科学实体正在将其工作流程与 NVIDIA BioNeMo 集成, NVIDIA BioNeMo 是一个面向药物研发的生成式 AI 平台。该平台简化并加速了模型训练。借助 BioNeMo,组织可以为各种目的定制和部署 AI 模型,包括 3D 蛋白质结构预测、从头开始蛋白质和小分子生成、属性预测和分子对接。
如果您对探索 BioNeMo 感兴趣,可以通过 BioNeMo 框架的测试版或 API 抢先体验计划来获得相关机会。欲了解更多信息,请访问 NVIDIA BioNeMo 产品页面。