随着可用数据规模的不断增长,对可扩展的智能数据处理系统的需求也在不断增长,以快速利用有用的知识。尤其是在生命科学和金融等高风险领域,数据驱动流程的可扩展性和透明度对于确保高度可信赖至关重要。
Prometheux 是一家 NVIDIA 初创加速计划公司,由来自牛津大学知识图谱实验室和维也纳工业大学的科学家创立,致力于构建能够解释其精确逻辑过程的 AI.从 AstraZeneca 的药物再利用到意大利中央银行应用研究团队的金融数据处理,Prometheux 技术为一些世界上最大的知识图提供高度可扩展和可解释的推理。
Prometheux 已利用 NVIDIA GPU无缝集成 适用于 Apache Spark 的 RAPIDS 加速器 到他们专有的知识图管理系统 Vadalog 并行处理引擎。在处理包含数亿实体和数十亿关系的大型知识图时,他们为客户实现了显著的加速并节省了成本。
知识图和推理
在过去几十年中,由于可用数据的规模不断增长,大型企业知识图的受欢迎程度迅速上升。用于利用这些知识图的可扩展智能处理系统也相应增加。
知识图可作为数据集成的支柱,并提供通用的表示结构,以支持跨大型数据源的查询应答。A知识图可定义为由以下内容组成的半结构化数据模型:
- 一个扩展组件:整合来自异构数据源的知识,包括现有的实体和关系。
- 一个密集型组件:领域知识,可以采用统计和 ML 模型的形式,也可以是以逻辑规则声明方式定义的。
- 衍生的扩展组件:通过在所谓的推理过程中应用领域知识来生成扩展组件。
从复杂的公司所有权图到蛋白质交互网络,知识图可为各种领域提供简洁直观的抽象概念,并可用于为真实世界的实体及其相互关系建模。
Vadalog Parallel
类似于人类智能中直觉和逻辑思维的相互作用,AI 也朝着神经符号是 ML 和基于逻辑的推理的协同组合。
Prometheux 面向神经符号 AI 构建,提供 Vadalog Parallel,这是其知识图形管理系统 (KGMS),可提供演完全可解释框架。此 KGMS 将数据与域逻辑相结合,并以高可扩展性和透明度为核心,自动处理大型知识图形上的复杂推理任务。
Vadalog Parallel 充当异构企业数据源与基于这些数据源的应用程序之间的中间件。它充当数据集成的中坚力量,而无需迁移数据。在高级别对域逻辑进行编码,可以快速开发全新的解决方案,而无需对大量代码或设计算法进行编程。
Vadalog Parallel 提供与数据库无关的兼容性,可无缝连接到所有主要数据库(RDBMS、RDF 和 NoSQL,例如 Neo4j 和 Mongo 等)以及各种数据源(CSV、Parquet、JSON 等)。无论是处理元组、三元组还是n– 元组。
领域逻辑采用高级声明编码,使领域科学家能够以自动化、可解释和直观的逻辑方式直接从大型知识图形中提取见解,从而节省时间和计算资源。
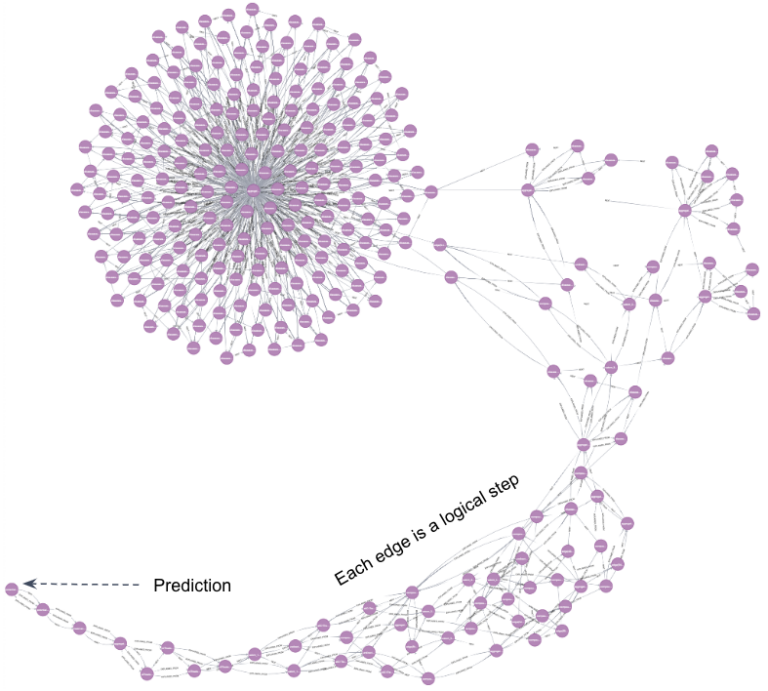
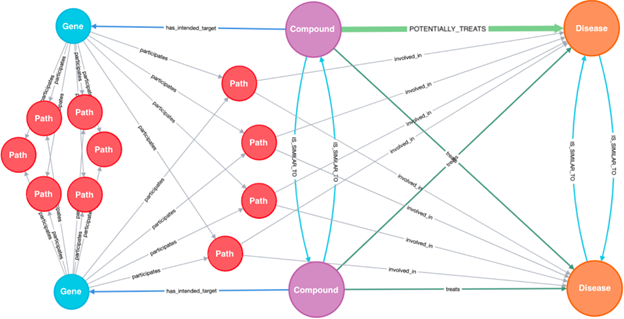
对于每项任务,Vadalog Parallel 都以原生方式提供推理过程的分步、逻辑完整解释。以闪电般的速度计算出多达数十亿个逻辑步骤,并伴随一个紧凑的视觉解释,以更快地与领域专家进行互动。
得益于其富有表现力的框架和分布式处理,Vadalog Parallel 在实践中实现了较低的计算复杂性和可扩展性,并能够使用高级数据分析功能对复杂领域进行建模。
事实上,它支持高效的图形遍历,并捕获常规路径查询(用于使用模式匹配(例如 Cypher)导航图形)和 OWL2 QL 机制下的 SPARQL (用于查询语义网络)。与其他先进系统不同,它支持反事实和时间推理、完全递归和存在量化,并且性能优于现有的大数据分析工具。
随着数据集规模空前,我们对推理引擎的可扩展性和灵活性提出了新的要求,因此 AI 技术可以足够快地执行。为了保证此类需求,Prometheux 精确地研究和开发了编译技术,将经典推理、推理方法和工具转移到大数据平台上。
即使仅在 CPU 上运行,Vadalog Parallel 也已经实现了无与伦比的可扩展性。但是,在对一些世界上最大的知识图(具有数亿个实体和数十亿个关系)进行推理时,GPU 成为不可或缺的资产。
可解释的药物再利用及其他用途
Vadalog Parallel 用于查找 各种应用 在计算生物学领域的研究成果,包括其对适应症扩展的实际影响。
Prometheux 使生命科学组织能够以自动化和逻辑可解释的方式,以可扩展的方式推理大型生物(和其他类型的)知识图。这有助于做出更明智的决策,并加快与领域专家的互动,从而加速全球流程开发,实现值得信赖的精准医疗。
通过对专有数据集和客户数据集的自动化分析,Prometheux 通过逻辑推理揭示了隐藏的见解,并释放了现有药物用于新治疗目的的潜力。通过以闪电般的速度计算数十亿个逻辑步骤,Vadalog Parallel 生成了数百个成功验证的适应症(以及更多待研究的适应症),有效地提供了一个动态和可解释的推荐系统,用于适应症扩展。
推荐内容的简洁直观解释能够加快与领域专家的互动,并能快速适应反馈,使每个人从最初的知识到新的适应症,所需的时间比传统技术快得多。
在以下各节中,我们还将为一系列推理任务提供 Vadalog Parallel 与 NVIDIA GPU 的实验分析。我们使用 Prometheux 的内部试点生物知识图 (BIO KG),这是尚未构建自己的知识图的生命科学组织的起点。
BIO KG 拥有约 470 万个数据点,涵盖化合物、疾病、基因、生物途径、症状等。Vadalog Parallel 借助 Spark RAPIDS 实现高达 9 倍的加速。
金融机构
Vadalog Parallel 的另一个引人注目的应用在金融和经济的动态领域中展开。Prometheux 的知识图形辅助方法可增强对金融实体之间复杂互联的理解,无论这些实体是机构、公司、金融中介机构、其他类型的股东还是交易。
它可用于编码国际法规的金融科技、RegTech、SupTech 和 InsurTech 应用程序以及其他领域逻辑。其目标是通过知识图形自动推理,并实现 AI 辅助的银行监督、合规性检查、信用评估、反洗钱、欺诈检测、冲击传播、公司控制、收购检测等。
这种全面的方法使分析师能够主动管理风险、应对挑战、优化策略并促进财务稳定。
对于此领域,我们还展示了 Vadalog Parallel 在推理公司所有权图(Company KG)时使用 NVIDIA GPU 的性能。
公司 KG 是一个综合构建的知识图谱,反映了 意大利公司的知名拓扑,其中公司和股东之间拥有 800 万股的优势关系。在这些图谱中,Vadalog Parallel 借助 Spark RAPIDS 实现了高达 3 倍的加速。
策略和解决方案设计
Vadalog Parallel 架构具有以下关键组件,可在 Spark、Flink、GraphX 等分布式框架上高效执行推理任务:
- 规则解析
- 逻辑优化
- 查询规划
- 规划器优化
- 查询编译
总体而言,Vadalog Parallel 公开了具有以下接口的推理 API:
reason(kg_ref,domain_logic)
客户端应用程序向推理 API 发出调用,指定对知识图的引用kg_refVadalog Parallel 连接并处理知识图形库,每个库都有唯一的标识符 kg_ref.推理引擎编码domain_logic转换为一组分布式操作(窄、宽 transformation,即 shuffling),并计算推理任务的答案。它可以使用新知识扩展知识图形,也可以在指定的输出数据源中实现输出。
为了确保更快速、更可靠的处理,Prometheux 已将 Spark-RAPIDS 无缝集成到 Vadalog Parallel 中,超越了传统的 Spark 功能。
RAPIDS Shuffle Manager 是 Spark-rapids 不可或缺的一部分,通过引入交换 shuffle 数据的自定义机制提供了显著优势。这项创新提供了两种不同的操作模式:多线程和 UCX,可配置为利用 GPU 到 GPU 通信和 RDMA 功能。它利用 Vadalog Parallel 为推理任务提供无与伦比的性能和效率水平。
场景和数据
如果没有强大的递归,浏览图形可能非常具有挑战性。例如,标准 SQL 缺乏对递归的原生支持。
Vadalog Parallel 框架支持完全递归。在本文中,我们将展示如何通过 Spark-RAPIDS 集成 GPU 来显著加速图形遍历和图形分析任务。
我们将这些任务分为以下不同类型:
- 非递归:执行计划的结构是一棵树,其中每个分布式操作都只执行一次。
- 递归:执行计划以图形方式构建操作集,并应用分布式操作集,直至彻底探索知识图谱。
在此过程中,我们使用递归运算对 NVIDIA Spark-RAPIDS 进行首次评估。
实验结果
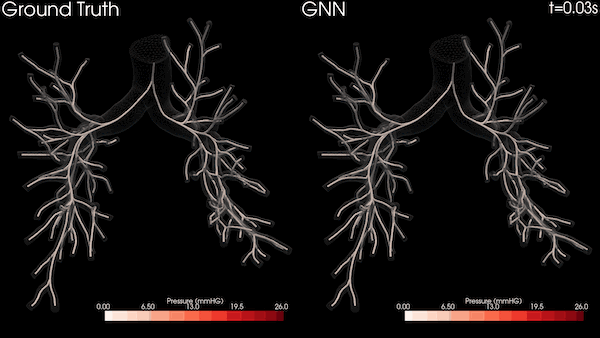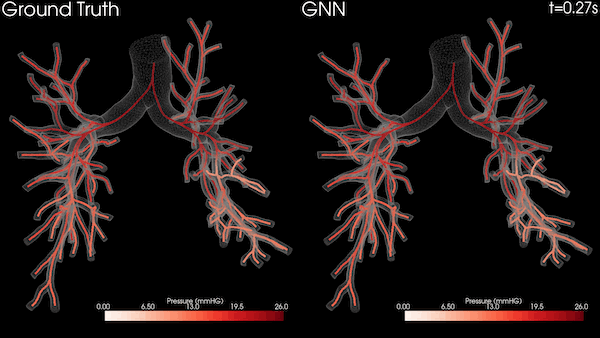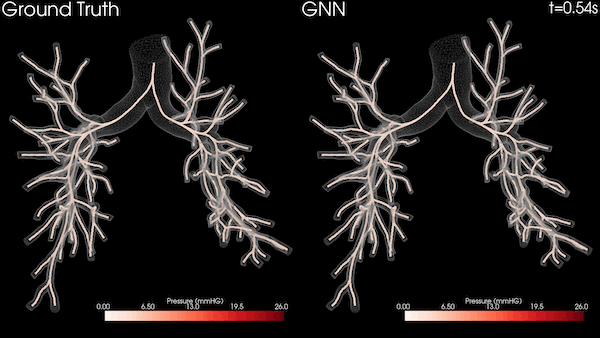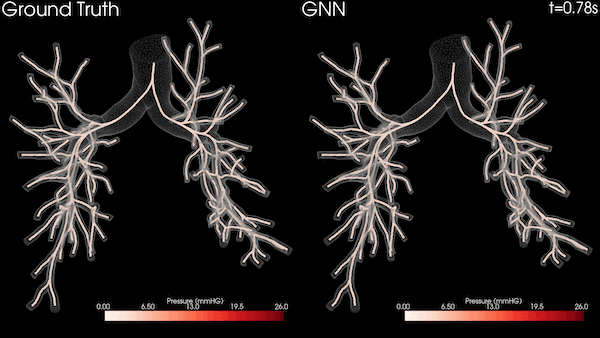
图 3 显示了四个包含递归和非递归运算的知识图分析任务,其中两个在 Bio KG 上,两个在 Company KG 上。对于所有测量,我们对每个实验运行了 10 次,并对结果求取了平均值。
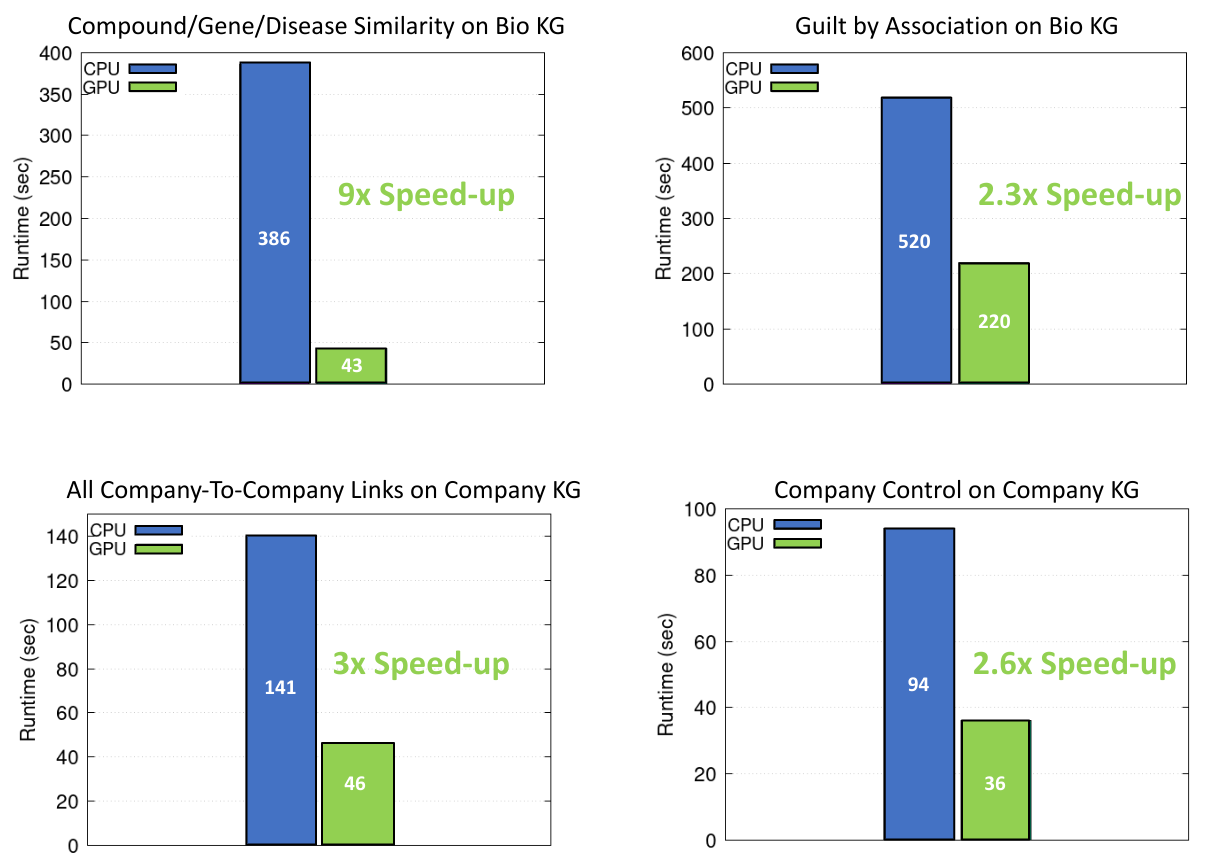
图 3 显示了之前介绍的知识图中的四项推理任务。我们在提供相关实验评估时特别关注使用 NVIDIA GPU 和 Spark RAPIDS 实现的加速。
硬件和软件配置
在所有实验分析中,Vadalog Parallel 均基于与 Spark-RAPIDS v23.08.1 集成并使用 CUDA v12.0 和 Java v8 作为 Spark 语言的 Spark 3.3.2 独立集群执行。该集群本地安装在 Amazon EC2 AMI p3.16 xlarge 上,具有 64 个 vCPU 8 GPU、480 GB RAM 和 8 个 NVIDIA V100 Tensor 核心,每个核心具有 16 GB GPU 核心内存。
测试设置
所有任务均需执行以下步骤:
- 调用 Vadalog Parallel 推理 API,在输入中传递描述任务的领域逻辑以及对两个知识图之一的引用。
- 与 Spark 集群建立连接。
- 从特定知识图中提取输入子图。
- 执行任务。
- 在 Parquet 文件中写入输出。
| KG | 边缘 | 任务 | 说明 | 运营 | 推理时间(秒) |
生物 KG |
470 万 |
化合物/基因/疾病相似性 | 根据常见特征确定基因、化合物和疾病的配对相似性 |
非递归宽转换:3 个连接,3 个聚合; 非递归窄带变换:3 个贴图,3 个滤波器; |
CPU:386 GPU:43 |
生物 KG |
470 万 |
关联犯罪 |
根据治疗一组类似疾病的相似化合物,为每种化合物推荐新的适应症 |
非递归宽转换:11 个连接,11 个聚合; 非递归窄带转换:52 个映射,26 个滤波器; |
CPU:520 GPU:220 |
公司 KG |
800 万 |
所有公司间链接 |
确定所有节点之间的成对连接 |
非递归 Wide Transformation:1 聚合; 非递归窄带变换:2 个映射,1 个滤波器; 递归宽转换:1 个连接,2 个聚合; 递归窄带变换:4 个贴图,4 个滤镜 |
CPU:141 GPU:46 |
公司 KG |
800 万 |
公司控制 |
查找每家公司的所有控制器对 |
非递归宽转换:2 次聚合; 非递归窄 transformation:2 个 Maps; 递归宽转换:1 个连接,1 个聚合; 递归窄变换:1 张地图 |
CPU:94 GPU:36 |
结束语
在本文中,我们讨论了使用逻辑推理在大型企业知识图以及用于利用这些知识的可扩展智能处理系统中的迅速普及。我们展示了 Prometheux 的知识图管理系统 Vadalog Parallel.Vadalog Parallel 是一个强大的框架,可将数据与域逻辑结合起来,并自动执行复杂的推理任务。这是一种解决方案,推动我们朝着神经符号式 AI是 ML 和基于逻辑的推理的协同组合。
我们还讨论了 Vadalog Parallel 在金融和生命科学领域的应用。在处理一些世界上最大的知识图时,集成 RAPIDS 可利用 NVIDIA GPU 显著加速并节省成本。
如需了解更多信息,请通过 Prometheux 的 LinkedIn 页面联系他们,或发送 电子邮件。有关 Spark 3.0 和 RAPIDS 的更多信息,请参阅 RAPIDS 开发者论坛。