自动语音识别( ASR )正在成为日常生活的一部分,从与数字助理交互到听写文本信息。由于以下方面的最新进展, ASR 研究继续取得进展:
- ASR 为多个架构建模以满足需求
- 在特定行业的行话、语言、口音和方言方面具有定制灵活性
- 云、预部署或混合部署选项
这篇文章首先介绍了常见的 ASR 应用程序,然后介绍了两个初创公司,他们正在探索 ASR 作为核心产品功能的独特应用。
语音识别系统的工作原理
自动语音识别 或语音识别,是计算机系统从音频中破译口语单词和短语并将其转录成书面文本的能力。开发人员也可以将 ASR 称为语音到文本,不要与文本到语音( TTS )混淆。
ASR 系统的文本输出可能是语音 AI 接口的最终产品,或 会话人工智能 系统可能会消耗文本。
常见 ASR 应用
ASR 已经成为新型交互式产品和服务的网关。即使现在,您也可以考虑使用下面详细介绍的用例的品牌系统:
现场字幕和转录
实时字幕和转录是兄弟。两者之间的主要区别是字幕产生字幕 根据需要,为流媒体电影等视频节目直播。相比之下,转录可以在现场或批处理模式下进行,其中录制的音频片段的转录速度比实时快几个数量级。
虚拟助理和聊天机器人
虚拟助手和聊天机器人与人们互动,既提供帮助,也提供娱乐。他们可以从用户输入的文本或 ASR 系统接收基于文本的输入,因为 ASR 系统识别并输出用户的单词。
助手和机器人需要足够快地向用户发出响应,因此处理延迟是不可察觉的。响应可能是纯文本、合成语音或图像。
语音命令和听写
语音命令和听写系统是社交媒体平台和医疗行业使用的常见 ASR 应用。
为了提供一个社交媒体示例,在移动设备上录制视频之前,用户可能会发出语音命令以激活美容过滤器:“给我紫色头发”。该社交网络应用程序涉及一个支持 ASR 的子系统,该子系统以命令的形式接收用户的话语,同时应用程序同时处理摄像机输入并应用过滤器进行屏幕显示。
听写系统存储语音中的文本,扩展了 语音人工智能系统 超越命令。为了提供医疗保健行业的一个例子,医生口述包含医学术语和名称的语音注释。准确的文本输出可以添加到患者电子病历中的就诊摘要中。
独特的 ASR 应用
除了这些常见用例之外,研究人员和企业家正在探索各种独特的 ASR 应用。以下两个初创公司正在开发以新颖方式使用该技术的产品。
互动学习: Tarteel AI
ASR 的创造性应用开始出现在教育材料中,特别是以互动学习的形式出现在儿童和成人中。
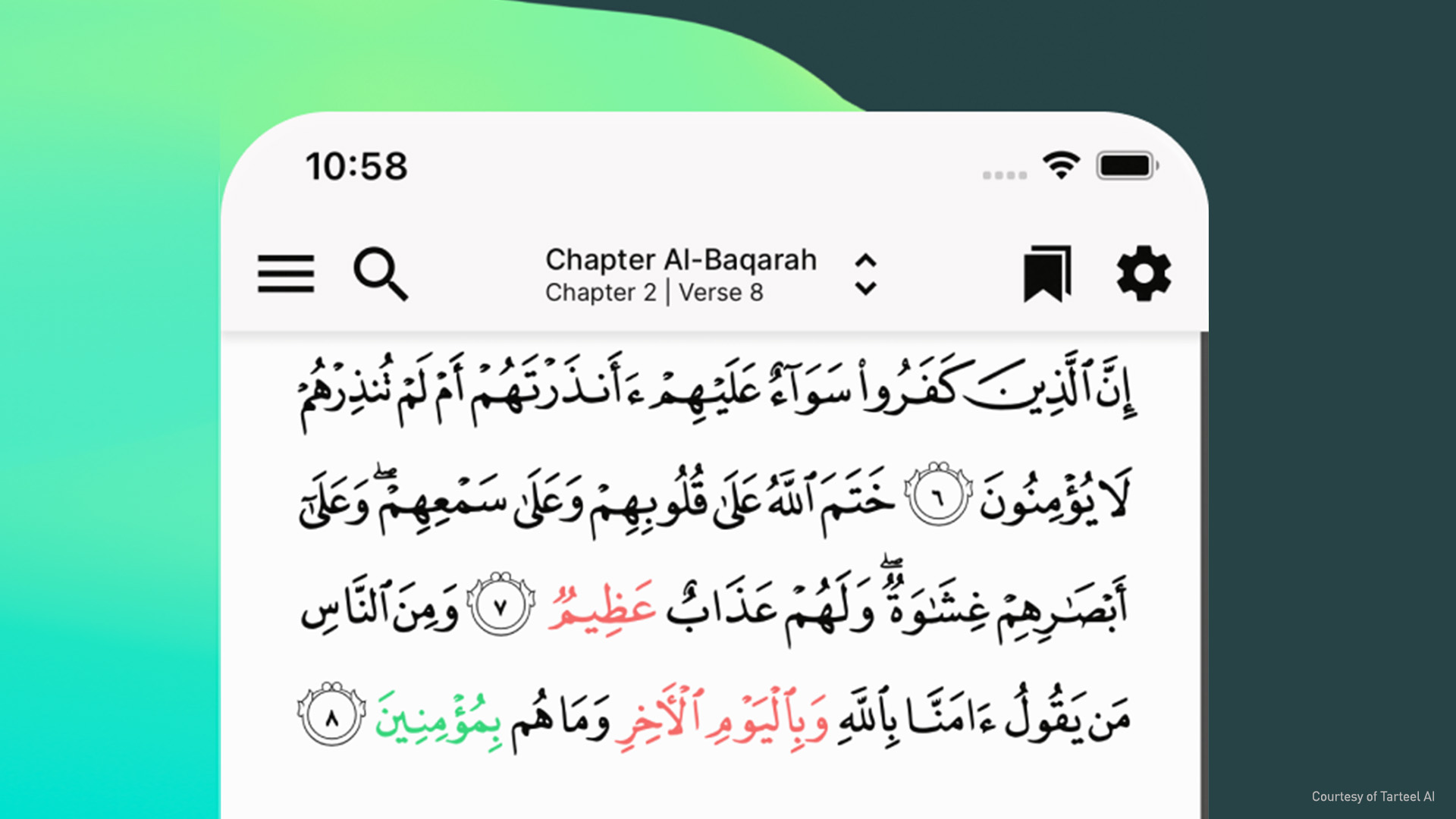
塔特尔。 ai 是一家初创公司,开发了一款移动应用程序,使用 NVIDIA Riva 帮助人们背诵和记忆《古兰经》。(“塔特尔” 是一个术语,用于定义使用旋律优美的音调在阿拉伯语中背诵古兰经。)应用程序应用 由 Tarteel 微调的 ASR 模型 古兰经阿拉伯语。要了解更多信息,请观看下面社交媒体帖子中的演示视频。
正如应用程序的屏幕截图所示,用户可以看到正确背诵的文本,从右到左、从上到下呈现。绿色的脚本是用户刚刚说出的单词(前沿)。如果在背诵中出现错误,不正确或遗漏的单词将被标记为红色,计数器将跟踪不准确之处,以进行改进。
用户的进度总结为背诵错误列表,包括可能帮助用户记住文本的类似段落的链接。挑战模式推动了用户的学习。
挑战和解决办法
虽然应用程序现在运行顺利,但 Tarteel 面临着一系列艰难的初始挑战。首先,古兰经阿拉伯语没有合适的 ASR 模型,最初迫使塔特尔尝试通用 ASR 模型。
Tarteel Anas-Abou Allaban 的联合创始人兼首席执行官说:“我们从设备上的语音人工智能框架开始,就像智能手机一样,但它们的设计更多是为了命令和短句,而不是精确的背诵。”。“它们也不是生产级别的工具,甚至不接近。”
为了克服这一挑战, Tarteel 构建了一个自定义数据集来完善现有的 ASR 模型,以满足应用程序的性能目标。然后,在他们的下一个原型中, ASR 模型确实以较低的字错误率( WER )运行,但仍不能满足应用程序的实际精度和延迟要求。
阿拉班指出,他在一些电话会议记录中看到了 10-15% 的正确率,但在古兰经研究中看到高正确率是另一回事。他说,应用程序中超过 300 毫秒的处理延迟“变得非常烦人”。
Tarteel 通过调整其在 NVIDIA NeMo 框架中的 ASR 模型并在使用 Riva 在 Triton 推理服务器上部署之前使用 TensorRT 进一步优化其延迟来应对这些挑战。
数字人类服务:Ex-human
创业公司 Ex human 正在创造超现实的数字人 与模拟人(你和我)互动。他们目前的重点是为娱乐利基开发 B2B 数字人类服务,使之能够创建具有独特个性、知识和现实说话声音的聊天机器人或游戏角色。
在公司 Botify AI 应用 ,人工智能实体包括名人,通过口头和图形交互与用户互动,无论您是在智能手机聊天窗口中打字还是使用语音。 NVIDIA Riva 自动语音识别为数字人类的自然语言处理子系统提供文本输入,作为大型语言模型( LLM )的一部分。
为了使虚拟交互可信,需要精确和快速的 ASR 。由于 LLM 是计算密集型的,并且需要大量的处理资源,因此对于交互来说,它们可能运行得太慢。
例如, Botify AI 应用最先进的 TTS 来产生语音音频响应,进而使用另一种 AI 模型驱动面部动画。该团队观察到,当响应的周转时间短于约三分之一秒时,机器人与用户的可信交互处于最佳状态。
挑战和解决办法
虽然 Botify 人工智能正在努力弥合人工智能生成的真实视频与真实人类之间的差距,但 Ex-human 团队对其客户行为数据的分析感到惊讶。“他们正在打造自己的新动漫人物,”Ex-human 的创始人兼首席执行官阿泰姆·罗迪切夫( Artem Rodichev )说。
通过使用为 Botify AI 生态系统微调的 ASR 模型,用户可以与自己喜爱的个性进行交流或创建自己的个性。在上传自定义人脸的背景下,构建新动画角色的令人惊讶的模式出现了,通过自定义角色将对话带入生活。 Rodichev 解释说,他的团队需要快速调整他们的人工智能模型,以处理例如在风格上只是一个点或一条线的嘴。
Rodichev 和他的团队通过仔细选择工具和 SDK 以及评估并行处理的机会,克服了 Ex-human 架构中的许多挑战。 Rodichev 警告说:“由于延迟非常重要,我们使用 NVIDIA TensorRT 优化了 ASR 模型和其他模型,并依赖于 Triton 推理服务器。”
Botify AI 用户是否准备好与数字人类而不是模拟人类互动?数据显示,用户平均每天花 40 分钟与 Botify 人工智能数字人在一起,在这段时间内发送他们最喜欢的数百条信息。
开始使用 ASR
您可以开始在自己的设计和项目中包括 ASR 功能,从免提语音命令到实时转录。 Riva 等高级 SDK 在世界级的准确性、速度、延迟和易集成性方面表现出高性能,所有这些都与您的新想法一致。
尝试 NVIDIA Riva 自动语音识别 在您的 web 浏览器上,或下载 Riva 技能快速入门指南 .
相关资源
- 了解您的组织如何从免费电子书中受益于语音识别技能 构建语音 AI 应用程序 .
- 使用以下工具探索语音人工智能和会话人工智能之间的差异: 基本语音人工智能术语理解指南 .
注册最新信息 人工智能新闻致辞 来自纽约。




