计算世界正处于巨变的边缘。
对计算能力的需求,尤其是高性能计算 (HPC) 逐年增长,这也意味着能源消耗也在增长。然而,潜在的问题当然是,能源是一种具有局限性的资源。因此,世界面临的问题是,我们如何更好地将计算重点从性能转移到能效。
在考虑这个问题时,必须考虑到任务完成率与能耗之间的相关性。这种关系通常会被忽略,但它可能是一个关键因素。
本文将探讨速度与能效之间的关系,以及向更快完成任务转变所带来的影响*.
以交通运输为例。
在物体运动的情况下,在除真空之外的任何其他情况下,阻力与行驶速度的平方成正比。这意味着在给定距离内,行驶速度是行驶速度的两倍,所需的力和能量是行驶速度的四倍。人员和货物在地球周围移动意味着在空气或水(在物理学中,两者都是“流体”)中行驶,这个概念有助于解释为什么行驶速度更快需要更多的能量。
大多数运输技术都依赖矿物燃料,因为即使是现在,矿物燃料的能量密度和运行在这些燃料上的引擎的重量也难以美。例如,核能源技术带来的挑战包括废弃物、安全运行所需的专业人员以及重量,这意味着核动力汽车、公共汽车或飞机不会在短期内出现。
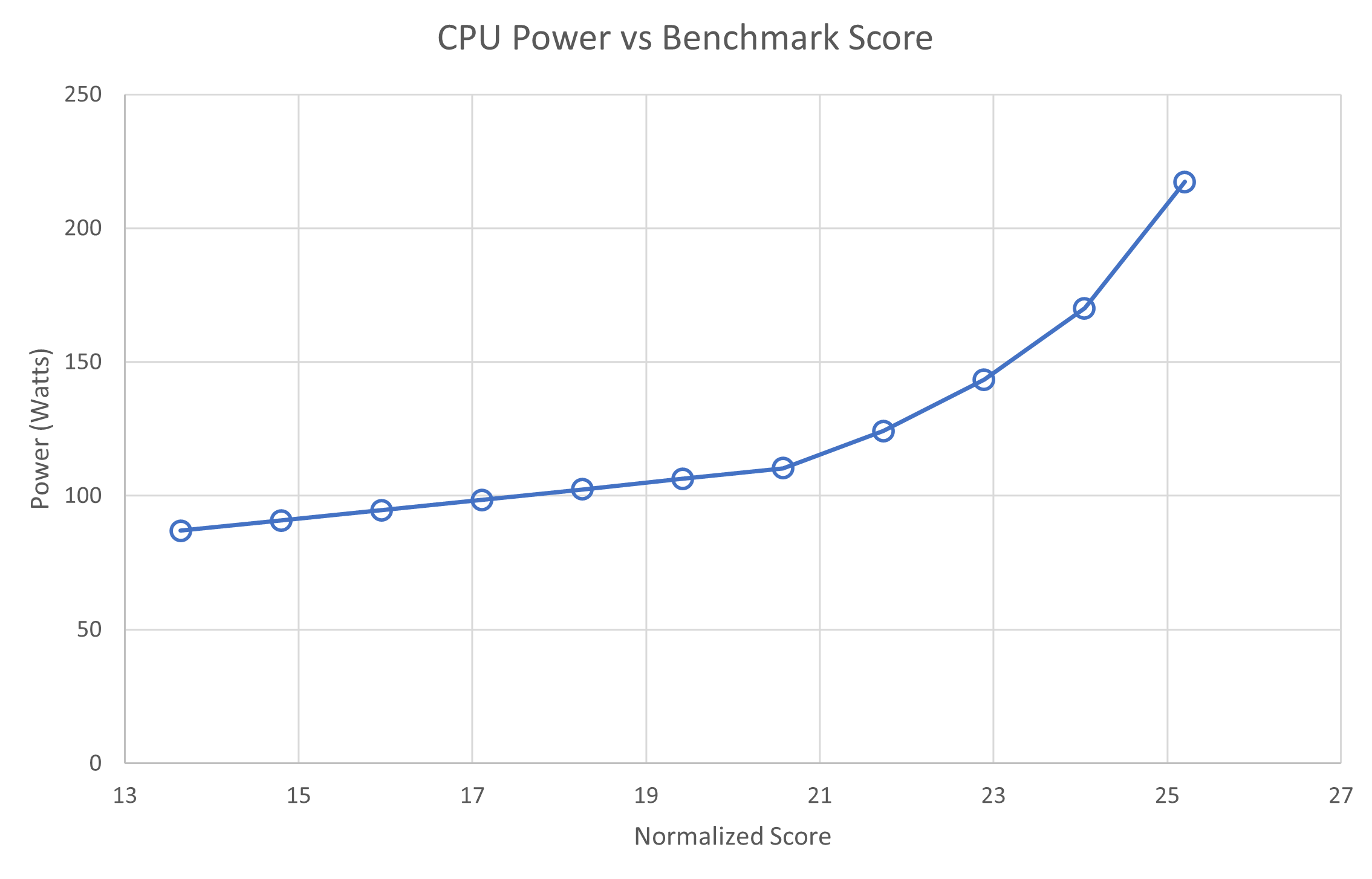
硅处理器与速度有着相同的关系。上一张图表显示,通过增加功率(单位时间能量)来提高整数处理速度。与运输类似,处理器运行得越快,消耗的能量就越多。
您可能会问,”如今,计算机何不以数十千瓦的功率运行呢?50 年来,计算机的运行速度会越来越快。”
答案是,随着处理器速度的不断提升,它们的体积也在变得越来越小。从能源效率的角度来看,硅元件的缩小使得它们能够更加高效地工作,因此在相同的功率消耗下,它们能以更高的时钟频率运行得更快。简而言之,这就是所谓的 Dennard 缩放。
多节点并行计算
HPC 中的一个关键概念是,并行计算以牺牲总计算时间为代价减少了挂钟运行时间。对于包含少量串行操作(对于未启动的,几乎全部执行)的 HPC 应用程序,随着添加更多计算资源,运行时逐渐接近串行操作的运行时。
这就是我们所说的 阿姆达尔定律。
在考虑并行计算消耗的能量时,这一点很重要。假设计算单元在执行计算时消耗的功率相同,这意味着计算任务在更大和更大的计算资源集合中并行执行时将消耗更多的功率。
这意味着,随着计算任务在越来越多的计算资源集合中并行执行,它将消耗更多的能量。同时,该任务运行的时间更短。本调查期间的假设是,通过添加资源来减少运行时间跟不上增量计算资源所需的额外能量,最终会消耗更多的能量。
或者,正如我们在简介中所讨论的那样,您想使用的速度越快,消耗的能量就越多。
测量能源使用情况
使用 Selene 系统,工程师可以基于 NVIDIA DGX A100 收集各种指标,这些指标通过 Grafana \cite{Grafana} 进行展示。借助其 API,用户可以查询单个 CPU、GPU 和电源单元在整个作业或特定时间范围内随时间变化的功耗。
将这些数据与模拟输出中的时间一起使用,可量化所用的能源。报告的能源消耗数据未考虑以下因素:
- 网络交换基础设施(包括服务器内部的网卡)
- 共享文件系统,用于数据分发和结果收集
- 从电源处的交流 (AC) 转换为直流 (DC),
- 数据中心冷却能耗中的CRAC 单位
其中最大的误差是风冷数据中心的第四个项目,与数据中心的用电效率 (PUE) (风冷+1.4,液冷+1.15)密切保持一致。此外,通过将测量的能耗增加 12%,可以近似计算交流到直流的转换。但是,本次讨论侧重于能源的比较,忽略了这两个误差。
对于单位和术语,在本文的其余部分中,我们使用瓦特(焦耳/秒)来表示功率,使用千瓦时(千瓦时)来表示能量。
实验设置
| 每个节点上有效的 NVIDIA InfiniBand 连接 | ||||
| 1 | 2 | 4 | ||
| 每个节点的 GPU 数量 | 1 | ✔ | ||
| 2 | ✔ | |||
| 4 | ✔ | ✔ | ✔ | |
鉴于全球 GPU 加速 HPC 系统的不同配置、HPC 模拟应用程序中加速技术的要求和采用阶段,使用不同配置的计算节点执行并行模拟非常有用。这进一步优化了性能和效率。
上表展示了每种应用程序五种不同扩展方式的对比。为了便于阅读,下面的图表采用了统一的视觉表示方法。单个 NVIDIA InfiniBand 连接用灰色虚线或黑色虚线表示。双 InfiniBand 连接用绿色实线表示,而四倍 InfiniBand 连接则用橙色虚线表示。
HPC 应用程序性能和能耗
本节深入介绍一些关键的 HPC 应用,这些应用代表计算流体动力学、分子动力学、天气模拟和量子色动力学等学科。
应用程序和数据集
| 应用 | 版本 | 数据集 |
|---|---|---|
| FUN3D | 14.0-d03712b | WB.C-30M |
| GROMACS | 2023 | STMV (h-bond) |
| 图标 | 2.6.5 | QUBICC 10 千米分辨率 |
| 灯 | develop_7ac70ce | Tersoff (85M 个原子) |
| MILC | gauge-action-quda_16a2d47119 | NERSC Large |
FUN3D
FUN3D 于 20 世纪 80 年代首次编写,旨在研究算法,并开发新的非结构化网格流体动力学模拟方法,用于至跨音速流态的不可压缩流。在过去 40 年中,该项目已发展成为一套工具,不仅涵盖分析,还涵盖基于伴随的误差估计、网格适应和设计优化。它还处理至高超声速的流态。
目前,美国公民代码、研究人员、学术界和行业用户都在利用 FUN3D.例如,波音、Lockheed、Cessna、New Piper 等公司已将这些工具用于高架、巡航性能和革命性概念研究等应用程序。
GROMACS
GROMACS 是一种分子动力学软件包,它将牛顿运动方程用于包含数亿到数百万个粒子的系统。它主要针对具有许多复杂键合作用的生化分子(如蛋白质、脂类和核酸)而设计。GROMACS 在计算非键合作用(通常在模拟中占主导地位)方面速度极快,许多团队还将其用于非生物系统(例如聚合物)的研究。
GROMACS 支持现代分子动力学实现中的所有常用算法。
ICOsahder 非流体静态建模框架
ICON 建模框架是 Deutscher Wetterdienst (DWD) 和 Max-Planck 气象研究所的联合项目,旨在开发统一的新一代全球数值天气预报 (NWP) 和气候建模系统。ICON 建模框架于 2015 年 1 月开始在 DWD 的预报系统中运行。
ICON 与其他 NWP 工具不同,因为它具有更好的保护特性,并且强制要求精确的局部质量保护和质量一致的传输。
它认识到气候是一个全球性问题,因此致力于在未来的大规模并行 HPC 架构上实现更好的可扩展性。
大规模原子/分子并行模拟器
大规模原子/分子大规模并行模拟器 (LAMMPS) 是一种经典的分子动力学代码。顾名思义,它专为在并行机器上良好运行而设计。
它的重点是材料建模。因此,它包含固态材料(金属、半导体)软物质(生物分子、聚合物)以及粗粒度或中间系统的潜在模型。LAMMPS 使用消息传递技术和模拟领域的空间分解实现并行性。其许多模型的版本在 CPU 和 GPU 上都提供加速性能。
MIMD 格点计算协作
MIMD 格点计算协作(MILC)是一个合作项目,由研究亚原子物理学中的强相互作用理论(也称为量子色动力学 (QCD))的科学家使用和维护。MILC 在 MIMD 并行机器上执行四维 SU(3) 格规理论的模拟。MILC 公开用于研究目的,使用 MILC 或基于此代码衍生的作品的出版物应承认这种用途。
并行可扩展性
在以下图形中,我们展示了一个无量次的加速,即以标准方式计算的“强扩展”:

Parallel SPEEDUP 通常使用“理想”的速度来绘制,其中使用一个计算资源的速度为 1,使用两个资源单元的速度为 2,以此类推。这里没有这样做,因为显示了多个缩放跟踪,当每个图形都有自己的理想速度参考时,数据会变得非常拥挤。
每个节点的 GPU 数量和每个节点扫描的启用 CX6 EDR InfiniBand 连接数量在图例中使用**GPU/节点*-**IB/节点*进行显示。
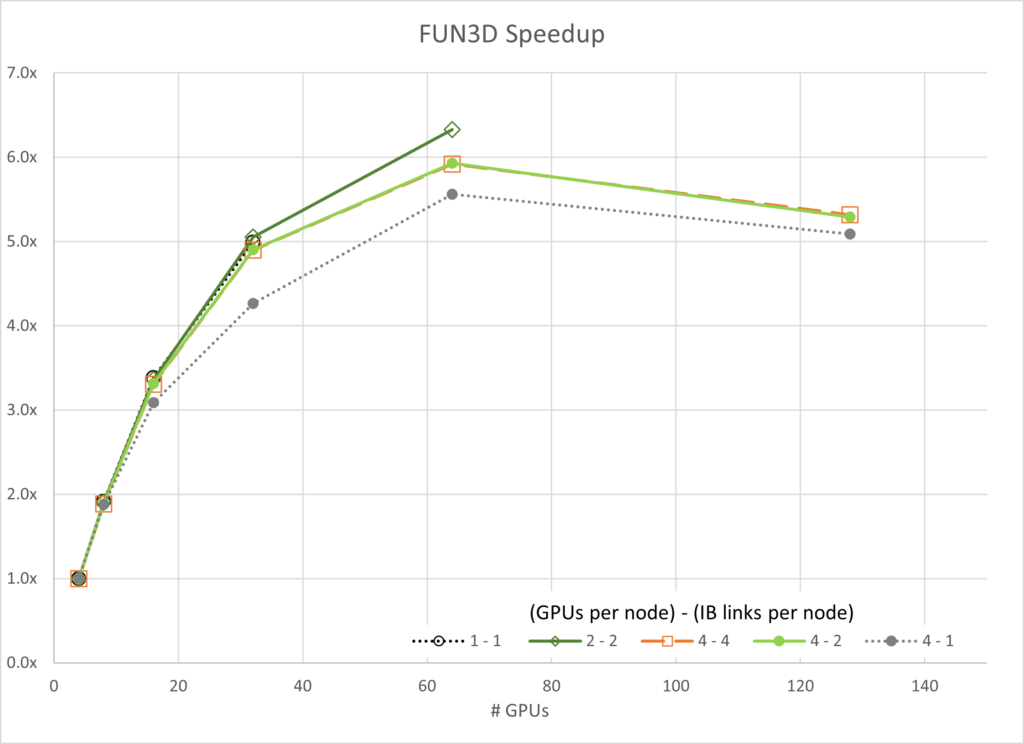
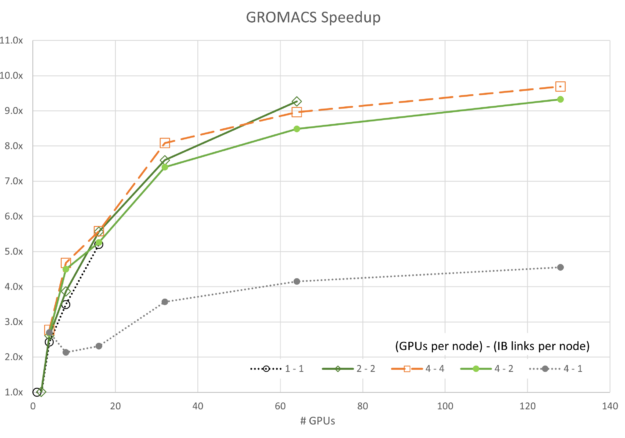
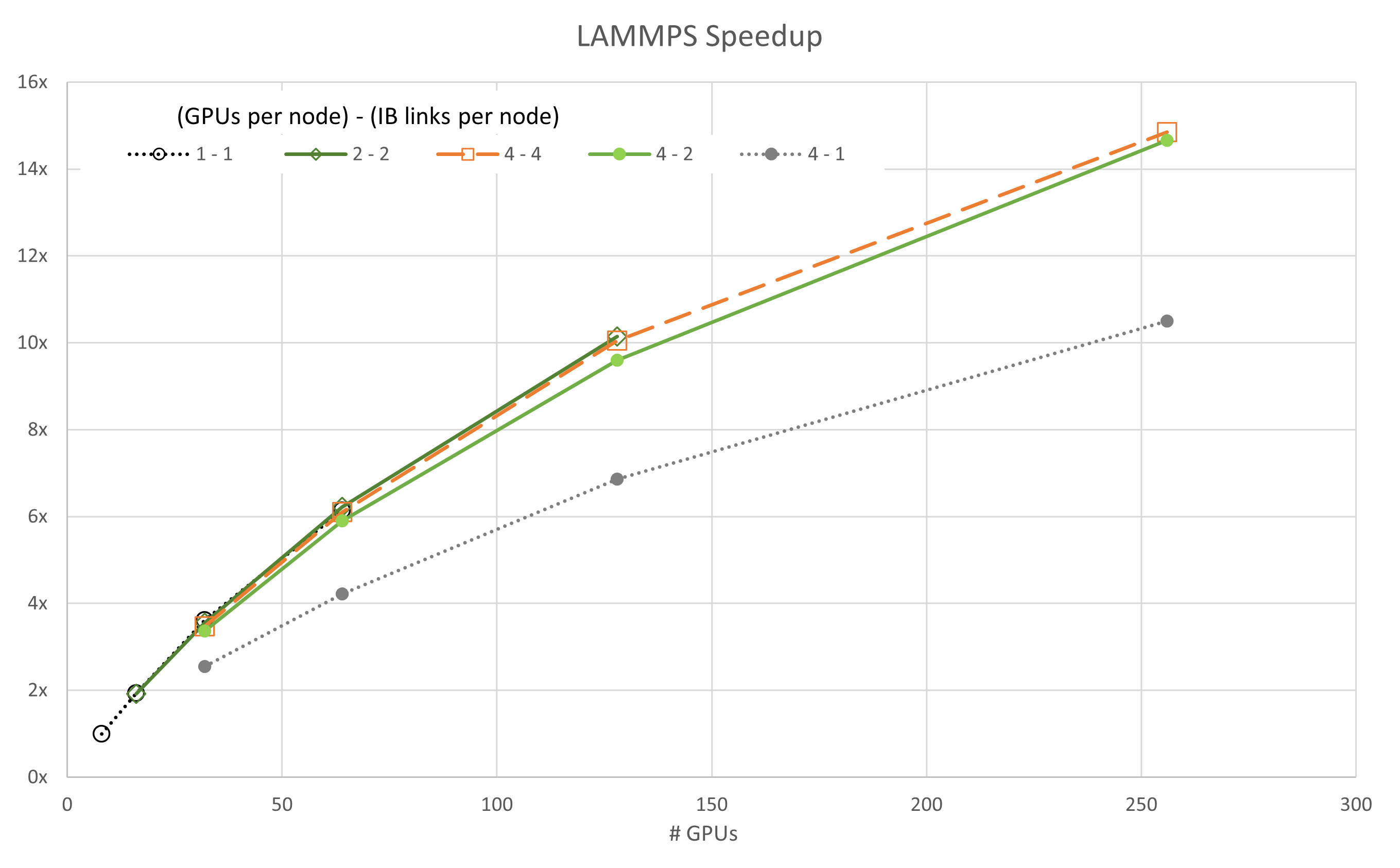
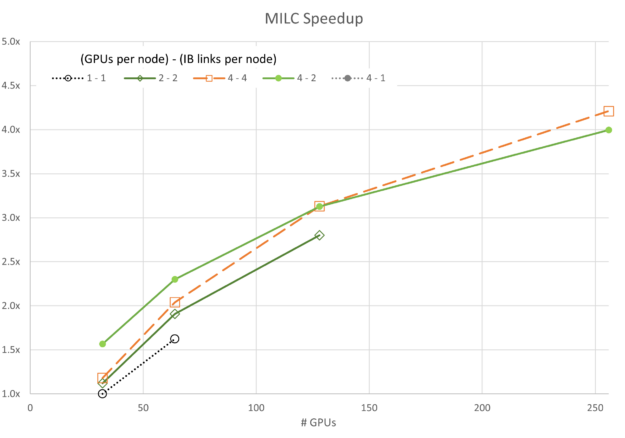
图 3 至图 7 显示了每个模拟的可扩展性。通常,大多数数据都遵循基于阿姆达尔定律的预期趋势。一个值得注意的例外是,使用四个 GPU 和一个 InfiniBand 连接的 GROMACS 配置(标记为 4-1)。此配置最初呈现负扩展,这意味着在开始扩展之前,随着资源的添加,其速度会降低。
给定网络配置,扩展似乎受网络带宽和每个并行线程尝试通信的数据的约束。随着资源数量在 16 到 32 GPU 之间增长,任务达到了不再受带宽限制的程度,并在一定程度上进行扩展。
对于 ICON 和 LAMMPS,4-1 配置也有类似的异常行为,尽管两者的扩展比 GROMACS 要容易得多。
同样值得注意的是,4-4 配置并不总是最佳性能。对于 FUN3D (2-2) 和 MILC 的一部分 (4-2) 而言,扩展其他配置会通过较小的利润空间显示出卓越的性能。但是,在所有情况下,4 – 4 配置都是最佳配置之一。
能源使用
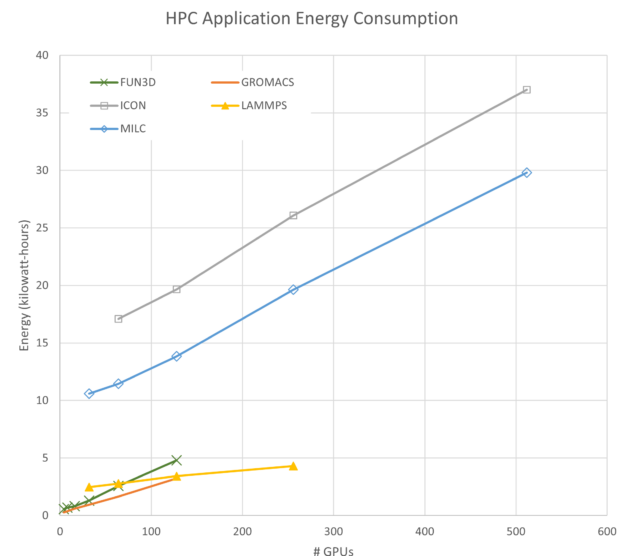
为简洁起见,图 8 仅显示了一个图中 4 个 GPU 和 4 个 IB 连接 (4-4) 的能耗。每次模拟使用的能耗是任意的,可以通过更改问题大小或分析类型来调整。需要注意两个相关特征:
- 每个应用程序的斜率为正,这意味着它们在扩展时消耗更多的能量。
- 一些应用程序(如 FUN3D)会迅速增加使用的能源,而其他应用程序(如 LAMMPS)则会逐渐增加。
与能源到解决方案相比,解决问题所需的时间
有人可能会从图 8 中得出结论,运行这些模拟的最佳配置是最大限度地减少每次模拟使用的资源数量。虽然从能源角度得出的结论是正确的,但除了能源之外,还有更多的目标需要考虑。
例如,在研究人员在项目截止日期前开展工作时,解决问题的时间至关重要。或者,在商业企业中,通常需要最终数据才能启动制造流程并准备好产品上市。在这种情况下,解决问题的时间也可能超过更早生成模拟输出所需的额外能源。
因此,这是一个具有多个解的多目标优化问题,具体取决于每个已定义目标的权重。
理想案例
在探索目标之前,请考虑以下理想情况:
完美并行(意味着没有序列化操作)加速的 HPC 应用程序,可随着添加其他处理器而线性扩展。以图形方式, 加速曲线就是一条从 (11) 开始,然后向上和向右倾斜 1.0 的线。
对于此类应用程序,现在考虑能耗。如果添加的每个处理器消耗相同的功耗,则运行期间的功耗仅为:


但时间是 n 的反函数,因此我们可以重写它:

n 的取消,我们可以看到,在理想情况下,能量不是 GPU 数量的函数,事实上常量。

在一些情况下,HPC 应用程序在并行加速或能源方面并不理想。由于加速是指随着资源的增加而收益递减,而能源会随着资源的增加而大致呈线性增长,因此应该有一定数量的 GPU,其中加速与能源比的比率是最大值。
更正式地说,假设能量和时间的权重相同:
![SPEEDUP_{Energy} = \frac{SPEEDUP}{EnergyRatio} = \frac{\left [ \frac{runtime_{1\ GPU \ and\ 1\ IB}}{runtime_{n\ GPUs\ and\ m\ IB}} \right ]}{\left [ \frac{energy_{n\ GPUs\ and\ m\ IB}}{energy_{1\ GPUs\ and\ 1\ IB}} \right ]}\\ = \left [ \frac{runtime_{1\ GPU \ and\ 1\ IB}}{runtime_{n\ GPUs\ and\ m\ IB}} \right ] \times \left [ \frac{energy_{n\ GPUs\ and\ m\ IB}}{energy_{1\ GPUs\ and\ 1\ IB}} \right ]](https://s0.wp.com/latex.php?latex=SPEEDUP_%7BEnergy%7D+%3D+%5Cfrac%7BSPEEDUP%7D%7BEnergyRatio%7D+%3D+%5Cfrac%7B%5Cleft+%5B+%5Cfrac%7Bruntime_%7B1%5C+GPU+%5C+and%5C+1%5C+IB%7D%7D%7Bruntime_%7Bn%5C+GPUs%5C+and%5C+m%5C+IB%7D%7D+%5Cright+%5D%7D%7B%5Cleft+%5B+%5Cfrac%7Benergy_%7Bn%5C+GPUs%5C+and%5C+m%5C+IB%7D%7D%7Benergy_%7B1%5C+GPUs%5C+and%5C+1%5C+IB%7D%7D+%5Cright+%5D%7D%5C%5C+%3D+%5Cleft+%5B+%5Cfrac%7Bruntime_%7B1%5C+GPU+%5C+and%5C+1%5C+IB%7D%7D%7Bruntime_%7Bn%5C+GPUs%5C+and%5C+m%5C+IB%7D%7D+%5Cright+%5D+%5Ctimes+%5Cleft+%5B+%5Cfrac%7Benergy_%7Bn%5C+GPUs%5C+and%5C+m%5C+IB%7D%7D%7Benergy_%7B1%5C+GPUs%5C+and%5C+1%5C+IB%7D%7D+%5Cright+%5D&bg=transparent&fg=000&s=0&c=20201002)
其中![\left [ runtime_{1\ GPU \ and\ 1\ IB} \times energy_{1\ GPU \ and\ 1\ IB}\right ]](https://s0.wp.com/latex.php?latex=%5Cleft+%5B+runtime_%7B1%5C+GPU+%5C+and%5C+1%5C+IB%7D+%5Ctimes+energy_%7B1%5C+GPU+%5C+and%5C+1%5C+IB%7D%5Cright+%5D+&bg=transparent&fg=000&s=0&c=20201002)
因此,最大化:
![\frac{1}{\left [ runtime_{n\ GPU \ and\ m\ IB} \times energy_{n\ GPU \ and\ m\ IB}\right ]}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B%5Cleft+%5B+runtime_%7Bn%5C+GPU+%5C+and%5C+m%5C+IB%7D+%5Ctimes+energy_%7Bn%5C+GPU+%5C+and%5C+m%5C+IB%7D%5Cright+%5D%7D&bg=transparent&fg=000&s=0&c=20201002)
或最小化:

如果在一个轴上绘制运行时图,而在另一个轴上绘制能量图,则要最小化的量就是通过运行时乘以能量来定义的区域。以这种方式定义问题还支持探索多个独立变量,包括但不限于并行运行中使用的资源数量、GPU 时钟频率、网络延迟、带宽以及影响运行时和能源使用量的任何其他变量。
平衡速度和能耗
以下图形是运行时和能耗的乘积,其中自变量是并行运行中的 GPU 数量。这些图形提供了一种方法,用于在 Pareto 前端解决方案中确定一个解决方案,以优化运行时和能耗。
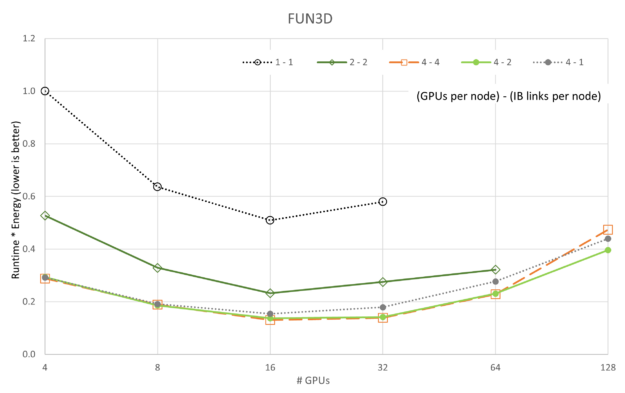
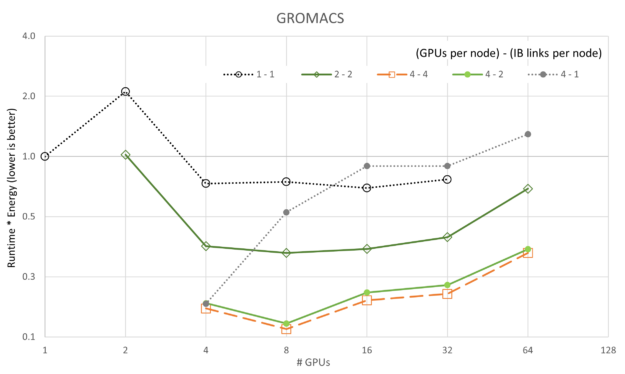
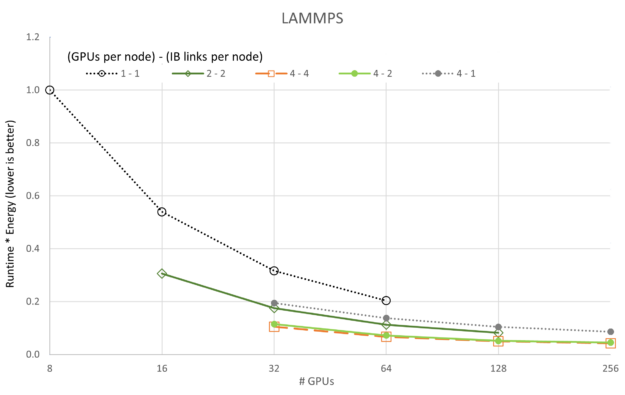
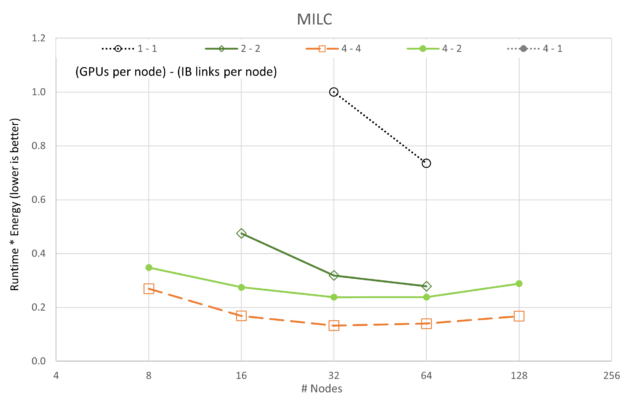
前面的图显示了运行时=能量的变化,因为 5 个应用程序和 5 个 GPU/网络配置中的每个都根据 GPU 数量进行了扩展。与性能的可扩展性图不同,我们可以看到,在所有情况下,4-4 配置(提醒,“4 – 4”是指**GPU/节点*-**IB/节点*)都是最好的,4-2 配置偶尔会接近一秒。与可扩展性图一致,1-1 配置始终是最差配置,这可能是因为每个服务器上的开销主要是空闲的(即每个节点都有 8 个 A100 GPU 和 8 个 CX6 InfiniBand 适配器)。
也许更有趣的是,LAMMPS 和 ICON 都表明,对于我们收集的数据,它们在运行时=能量中没有达到最小值。应该对 LAMMPS 和 ICON 执行更大的运行,以显示最小值。
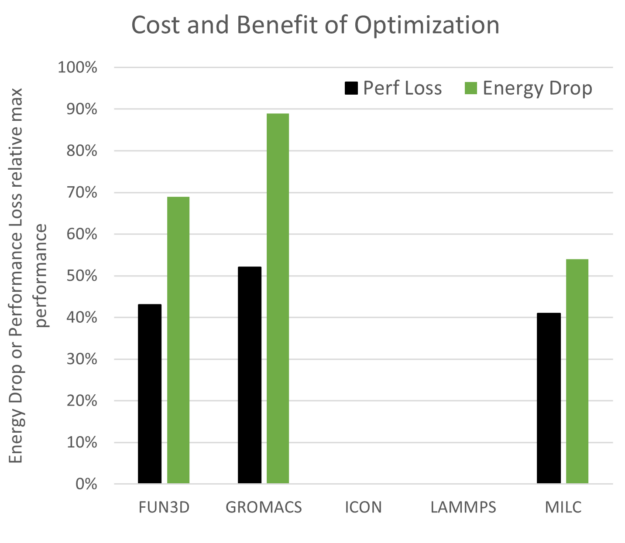
与最大性能点相比,有机会节省能源和性能成本。如图 14 所示。未绘制 ICON 和 LAMMPS 是因为它们未显示优化中的最小值。预期结果是,性能下降幅度小于每次模拟所用的能源,而这正是 FUN3D、GROMACS 和 MILC 的情况。
探索多节点可扩展性与能源的交叉
数据中心的发展以及对 AI 探索和使用的扩展将推动对数据中心、数据中心空间、冷却和电能的需求增加。鉴于矿物燃料产生的电力所占的比例,数据中心能源需求驱动的温室气体是一个必须管理的问题。
NVIDIA 继续专注于内部变革并影响未来产品设计,最大限度地提高 AI 革命对社会的积极影响。通过使用 NVIDIA 加速计算平台,研究人员在每单位时间内能够为每个科学成果消耗更少的能源。节省的能源相当于相应减少的二氧化碳排放量,这将造福地球上的每个人。
阅读近期文章,借助 NVIDIA Magnum IO 优化多节点 VASP 仿真的能效,以更深入地了解 VASP 和能效。
这些简短的讨论和一组结果旨在快速启动有关改变 HPC 中心分配和跟踪提供给研究社区的资源的方式的对话。它还可能影响用户在运行大型并行模拟时考虑其选择的影响,以及下游影响。
是时候开始讨论 HPC 和 AI 模拟的能源到解决方案以及多目标优化与解决方案时间的平衡了。总有一天,HPC 社区可能会测量每兆瓦时的科学进步,甚至可能是每毫吨 CO2eq 的科学进步,但这在对话开始之前是无法实现的。
欲了解更多信息,请访问 NVIDIA 可持续计算 页面。了解 NERSC 对 NVIDIA 加速平台的评价。或者查看 Alan Gray 在 NVIDIA 2023 GTC 会议 上关于优化加速平台以提高效率的演讲。