无论您的组织是数据科学新手还是有成熟的战略,许多人都有类似的认识:大多数数据并非源自核心。
科学家通常希望访问大量的数据,而这些数据对于安全地实时传输到数据中心来说是不合理的。无论距离是 10 英里还是数千英里,传统 IT 基础设施的边界根本就不是为了延伸到固定校园之外而设计的。
这使组织认识到,没有边缘战略,任何数据科学战略都是不完整的。
继续阅读以了解业界对耦合数据科学和边缘计算的好处、面临的挑战、这些挑战的解决方案的见解,并注册以查看边缘体系结构蓝图的演示。
边缘架构
Edge computing 是一种 IT 体系结构,通常用于创建能够容忍地理分布数据源和高延迟低带宽互连的系统。
由于操作环境的限制,以这种方式设计的计算系统通常可以通过牺牲计算速度和高可用性来识别。
如今,组织通常使用三种边缘体系结构:
- 流数据
- 边缘预处理
- 自治系统
流数据
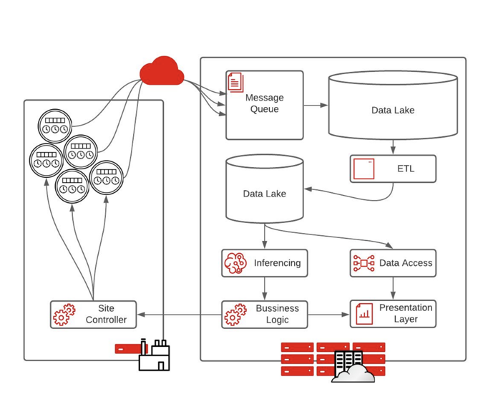
如今,流式数据,即经典的“大数据”体系结构,是刚刚开始实施边缘战略的组织最流行的原型体系结构。这种架构从物联网设备开始,通常是传感器,放置在工厂、医院或零售店的任何位置。然后,数据通过云发送到 IT 系统。
随着数据处理能力的提高,这种体系结构可能会成为一种障碍,因为需要的基础设施水平以及需要从边缘移动到核心的大量数据。
边缘预处理
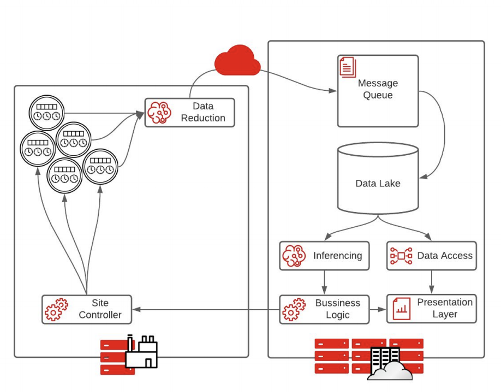
边缘预处理模型是向边缘过渡的组织最常见的体系结构。
传感器数据不是直接输入数据中心运行的管道,而是输入智能数据简化应用程序。这通常是一种智能机器学习算法,它决定哪些数据是重要的,哪些数据必须发送回数据中心。
提取、转换和加载( ETL )过程在该体系结构中不太重要,因为数据缩减已经在边缘发生。因此,不需要两个数据湖,推理可以更快地进行。结果是更快地执行业务逻辑。
这是创建完全自治系统的良好垫脚石,允许无限量的数据压缩。
自治系统
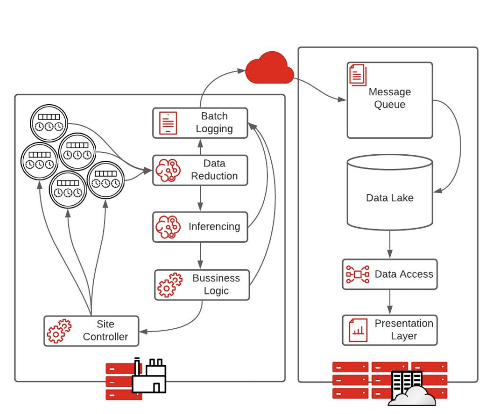
完全自治系统的特点是传感器在边缘收集数据,以低延迟快速做出决策。由于没有时间将数据发送回数据中心或云以做出正确的决策,处理在边缘进行,并自动采取行动。
使用此体系结构,管道的每一步都被发送到日志机制,以记录在边缘做出的决策。批记录将消息发送到云或核心数据中心,以便对所做的决策进行分析和系统调整。
构建智能边缘的行业见解
构建智能边缘解决方案不仅仅是将一个容器推送到数十或数千个站点。虽然这似乎是一项微不足道的任务,但您的组织的成功在很大程度上取决于您所建立的基础设施,而不仅仅是数据科学。
构建智能边缘解决方案 运行时需要考虑许多复杂性,例如规模、互操作性和一致性。
构建智能解决方案的建议技术包括:
- Linux 边缘系统
- 容器
- Kubernetes
- 消息传递协议( Kafka 、 MQTT 、 BYO )
实践中的边缘基础设施
当组织希望满足其业务需求并使数据科学能够推动创新时,您的选择不应局限于您的体系结构。实施边缘体系结构可以帮助您针对新的用例和技术对平台进行未来验证。
虽然了解您的体系结构在 edge 实现的不同阶段中所处的位置很有帮助,但通常最好是查看现场演示。
有关更多信息,请查看我们的网络研讨会 数据科学家逍遥法外:实现智能边缘的经验教训 ,了解有关如何在边缘实现 Kubernetes 系统的最佳实践以及它可以为您的组织提供的功能。
了解有关 edge computing 和 data science 的更多信息。