最新版本的 CUDA 工具包,即 版本 12.4,继续利用最新的 NVIDIA GPU 来推动加速计算性能。本文将介绍此版本中包含的新功能和增强功能:
- CUDA 驱动程序更新
- 适用于 NVIDIA Grace Hopper 系统的基于访问计数器的内存迁移
- 机密计算支持
- CUDA 图形条件语句
- CUB 性能提升
- 编译器更新
- 增强的监控功能
- 增强 NVIDIA Nsight Compute 和 NVIDIA Nsight Systems 开发者工具。
CUDA 和 CUDA 工具套件软件为数据科学和分析、机器学习、使用大型语言模型 (LLM) 进行深度学习的所有 NVIDIA GPU 加速计算应用程序提供基础 .CUDA 软件堆栈和生态系统提供一个平台,帮助开发者解决全球极为复杂的计算问题,尤其是在多 GPU 和多节点分布式架构中。
适用于 Linux (R550) 和 Windows (R551) 的 CUDA 驱动
每个 CUDA 工具包版本都需要最低版本的 CUDA 驱动程序。CUDA 驱动程序具有向后兼容性,这意味着使用特定版本的 CUDA 编译的应用程序将继续在后续版本的驱动程序中运行。有关兼容性的更多信息,请参阅 CUDA C++最佳实践指南。
适用于 NVIDIA Grace Hopper 显存的基于访问计数器的迁移
此版本引入了一种新的内存迁移算法,适用于 NVIDIA Grace Hopper 系统。它使用硬件访问计数器来确定内存页面的访问模式,并将内存从访问频率最高的硬件内存(CPU 或 GPU)迁移到硬件内存。这种迁移可以通过标准调用(如malloc和mmap)实现,并且可以从第三方库直接在GPU加速核函数中调用。
由于此是首次启用此功能的版本,因此开发者可能会发现,针对早期内存迁移算法进行优化的应用程序如果针对早期行为进行优化,则可能会出现性能反弹。如果出现这种情况,我们引入了一个受支持但临时的标志,以退出此行为。您可以通过卸载和重新加载 NVIDIA UVM 驱动程序来控制此功能的启用情况:
# modprobe -r nvidia_uvm
# modprobe nvidia_uvm uvm_perf_access_counter_mimc_migration_enable=0
将参数设置为 1 将启用基于访问计数器的迁移,将其设置为 0 将禁用它。
NVIDIA 机密计算
NVIDIA 机密计算适用于 NVIDIA Hopper 架构的解决方案现已推出,可供大众使用。保护您的工作负载免受未经授权的访问和物理攻击。有关更多信息,请访问 NVIDIA 可信计算解决方案.
CUDA Graphs 增强功能
CUDA Graphs API 继续是启动复杂设备功能序列重复调用的最高效方式 .CUDA 工具包 12.4 引入了许多 CUDA Graphs 增强功能,包括条件节点、设备端节点参数更新等。
图形条件节点
在许多应用程序中,对 CUDA 图形中的工作执行动态控制可显著提高图形启动的灵活性和易用性。例如,您可能有一个算法,涉及多次对一系列操作进行迭代,直到结果收敛在某个阈值以下,这在 AI 中很常见 .CUDA 工具包 12.4 改进了用于实时控制条件图节点的 API,这是 12.3 版本中引入的功能。
条件节点可以包含由图形描述的工作,这些工作可以在条件或循环中执行。此外,现在还可以在条件节点体内的内存分配节点中使用新的子图形类型,以及新的捕捉功能来捕捉这些子图形。
设备端节点参数更新,用于设备图形
借助 CUDA 工具包 12.4,现在可以通过设备端 API 动态更新内核节点参数 (网格几何图形和其他内核参数)。在创建图形时,节点可以通过一个新的内核节点属性“选择”成为可通过设备更新的节点,该属性在启用时将返回设备节点setAttribute呼叫。
设备可更新的内核节点可以从任何其他内核更新,无论是另一个图形、同一个图形,甚至是流内核启动。
一旦节点选择启用“device-updatable”(可更新设备),它便无法通过 cudaGraphnodeDestroy 从图形里去除。如果节点选择了此功能,则无法再选择退出具有设备更新功能,也无法在选择此功能后更新到另一个设备或上下文中的功能。
要启用此功能,请将属性CU_KERNEL_NODE_ATTRIBUTE_DEVICE_UPDATABLE_KERNEL_NODE创建节点后,可以使用以下 API 调用控制节点参数:
cudaGraphKernelNodeSetGridDimcudaGraphKernelNodeSetEnabledcudaGraphKernelNodeSetParam
无需重新编译即可更新可更改的图形节点优先级
在从流中录制图形节点时,通常希望在捕获时记录并尊重图形节点的流优先级,而不是使用启发式算法分配优先级 .CUDA 工具包 11.7 引入了这种功能,允许所有图形节点以这种方式工作,使用传入cuGraphInstantiate。但是,要求使用编译时标志可能会让用户无法在不进行全部重新编译的情况下在使用记录和启发式配置文件之间进行切换。
CUDA 工具包 12.4 引入了新的环境变量CUDA_GRAPHS_USE_NODE_PRIORITY以便在运行时控制图形节点优先级。环境变量按照表 1 中列出的行为运行。
CUDA_GRAPHS_USE_NODE_PRIORITY值 |
UseNodePriority在图形实例化时的行为 |
| 0 | UseNodePriority在所有图形实例化过程中 |
| 非零 | UseNodePriority在所有图形实例化中设置 |
| 未设置 | 通过图形实例化传递的旗帜 (或默认旗帜值) |
CUDA_GRAPHS_USE_NODE_PRIORITY环境变量设置CUB 性能提升
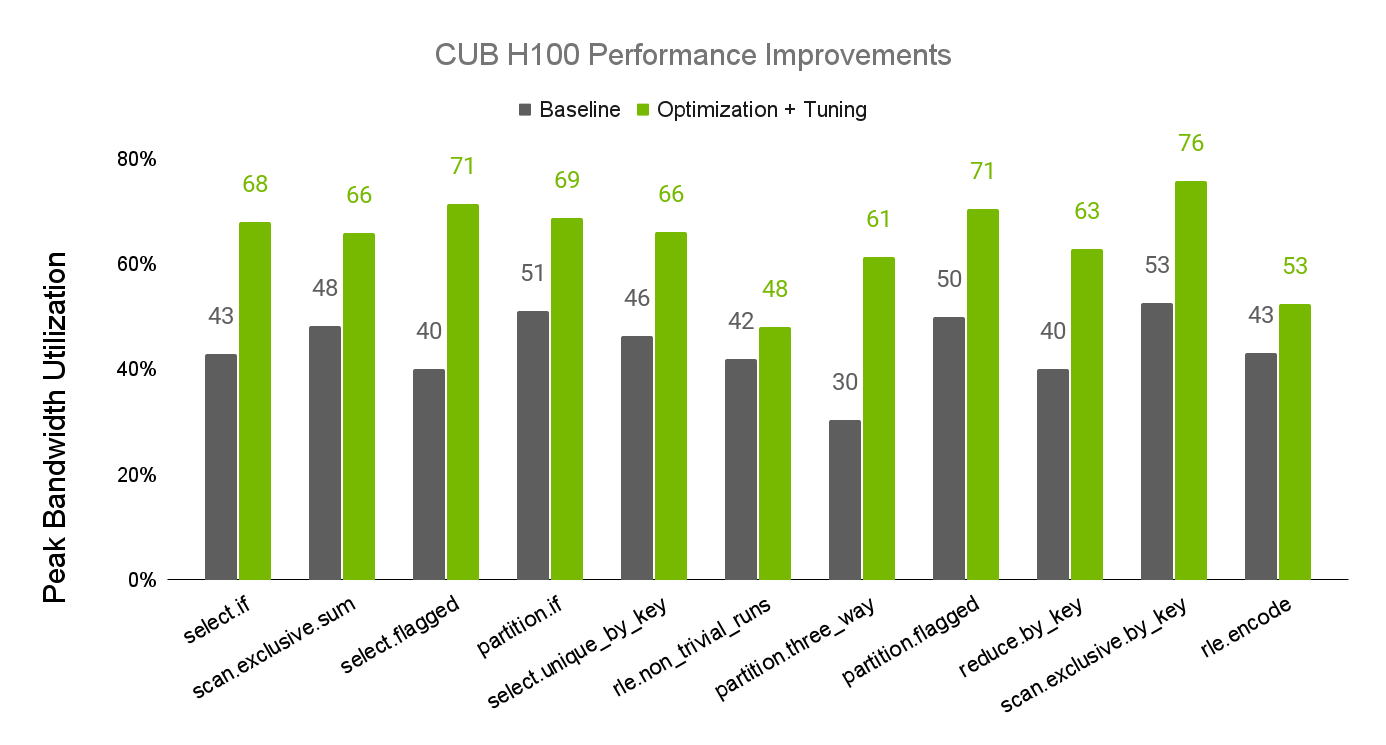
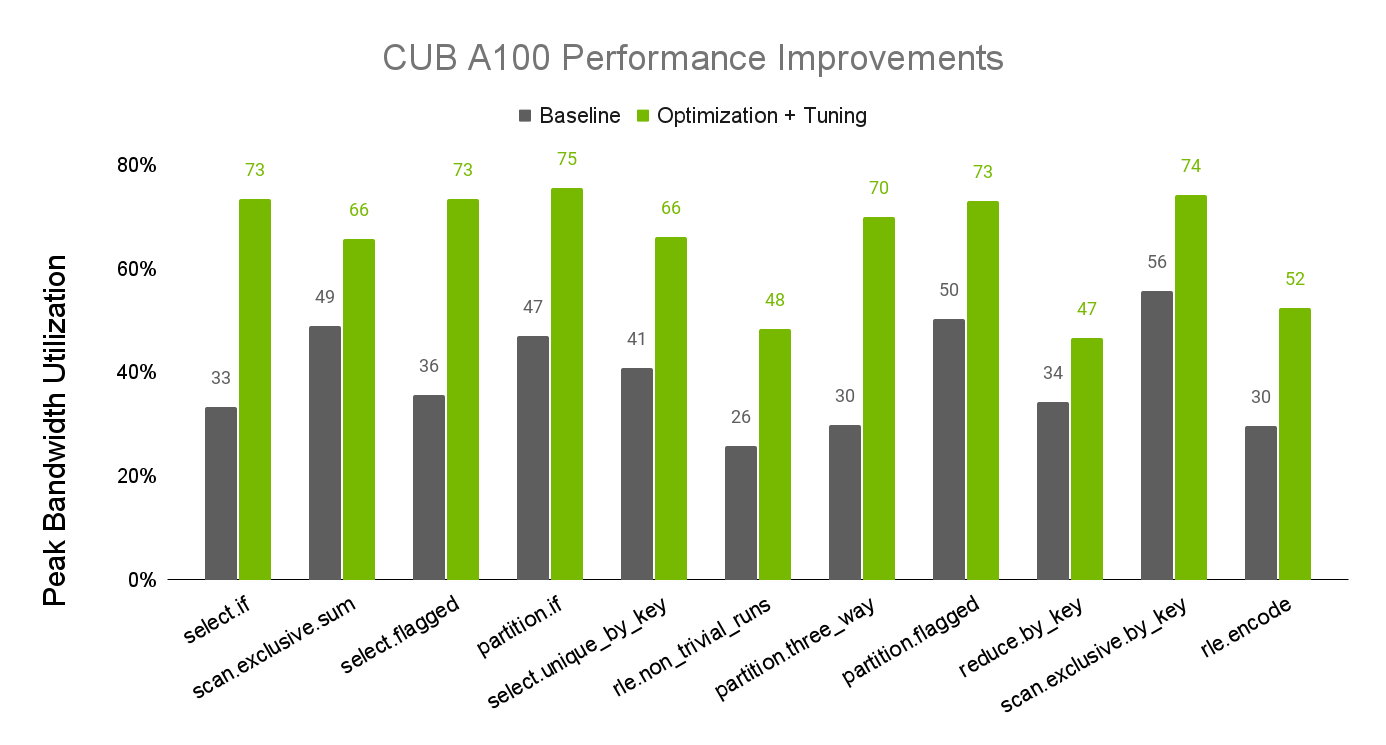
CUB 是 CUDA C++核心库的一部分,可在 CUDA 工具包和 NVIDIA/cccl的 GitHub 上找到。最近对 CUB 性能的调整更新显著提高了 CUB 算法在 NVIDIA A100 和 H100 GPU 上的性能。图 1 和图 2 显示了算法性能提升的情况,这是根据可用设备内存带宽的实现百分比测量得出的。
有关 CUB 性能调整的更多信息,请参阅 CUB 调整基础架构文档。
编译器更新
CUDA 工具包 12.4 版增加了对 GCC 13 作为主机端编译器的支持,并提高了编译时间性能。此外,还提供了一个新库,nvFatbin,以便对多 GPU 架构支持的二进制对象进行运行时操作。此库能够以编程方式创建较大的二进制文件,从而更轻松地处理运行时编译。
增强的监控功能
此版本为 NVIDIA 管理库 (NVML) 和 NVIDIA 系统管理接口 ( nvidia-smi ) 提供了许多新的指标,从而大幅提升了对整体 GPU 利用率的可见性:
- NVJPG 和 NVOFA 利用率百分比
- PCIe 类别和分类报告
dmon报告现已以 CSV 格式提供- NVML 返回更具说明性的错误代码
dmon现在报告 MIG 的 gpm 指标 (即nvidia-smi dmon --gpm-metrics在 MIG 模式下运行)- 使用旧版驱动程序运行的 NVML 将报告
FUNCTION_NOT_FOUND。某些情况下,如果 NVML 比驱动程序更新则会优雅的失效 - NVML API,用于查询适用于 Hopper 机密计算的保护内存信息
有关更多信息,请参阅 NVML 文档 和 NVIDIA 系统管理接口文档。
NVIDIA Nsight 开发者工具
最新版本的 NVIDIA Nsight 开发者工具 已包含在 CUDA 工具包 12.4 版中,可帮助您在 Grace Hopper 平台上优化和调试 CUDA 应用程序。
NVIDIA Nsight Compute
NVIDIA Nsight Compute 提供了对 CUDA 内核的详细分析和性能分析。在 2024.1 版本中,首次引入了 CUDA 工具包 12.4 的支持。此版本的 Nsight Compute 新增了 GPU 和显存工作负载分布的分析部分,帮助用户了解不同 SM 之间的任务负载平衡,以及显存系统的使用情况。内置的规则可以识别不平衡的负载分布,这可能对性能产生影响。利用这些新功能和规则来检测并优化潜在的不平衡工作负载分布,以最大程度地提高性能。
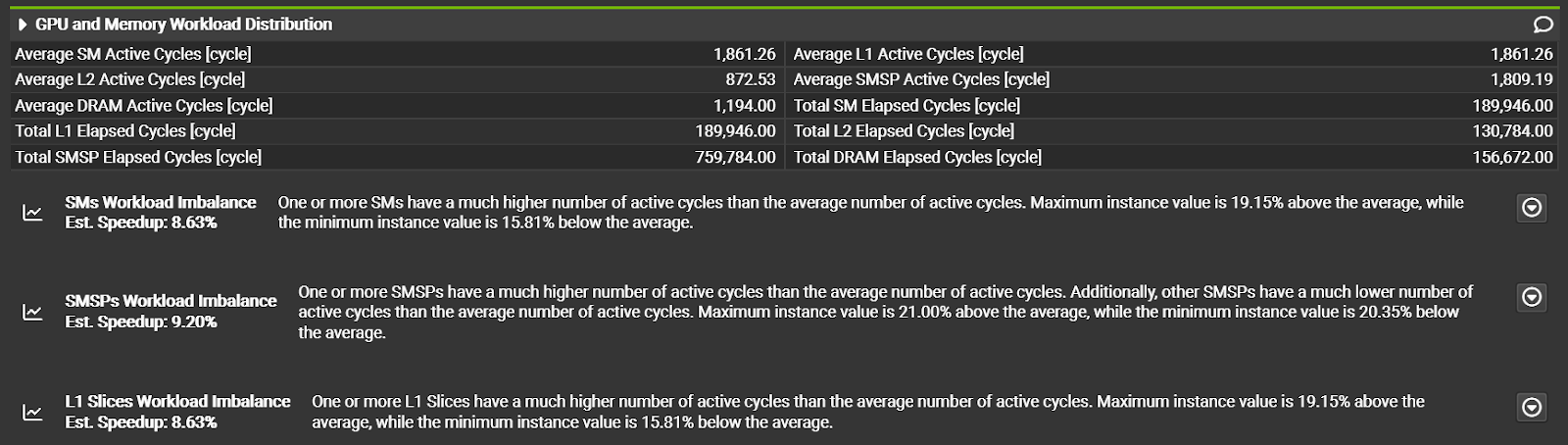
此外,新的“PM Sampling Warp State”(PM 采样扭曲状态) 部分提供更详细的时间相关性性能信息,并对最近添加的“Source Comparison”(来源比较) 页面进行了几项改进。
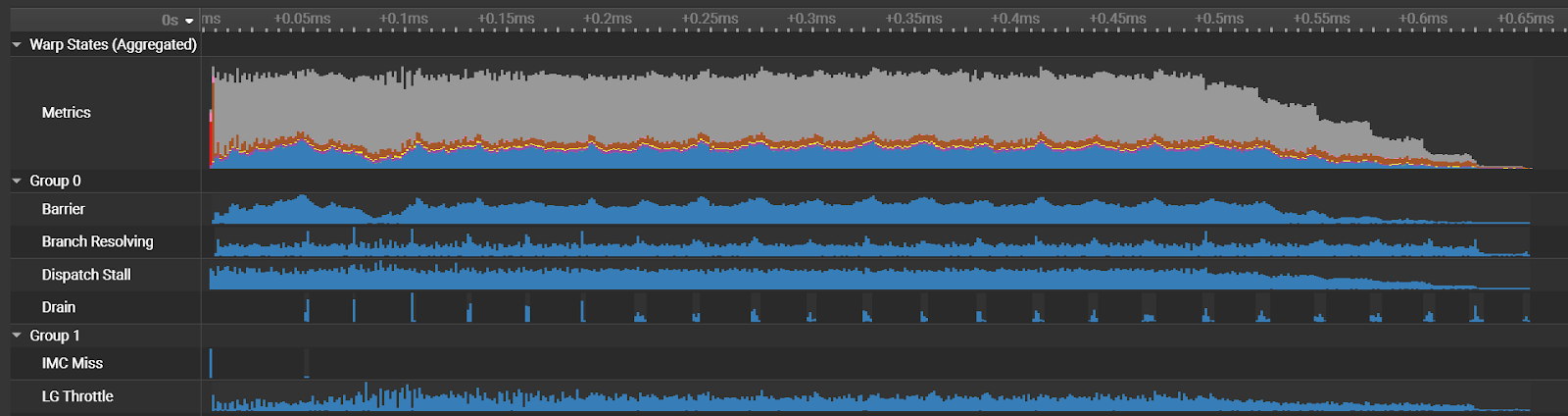
如需详细了解 Nsight Compute 2024.1 功能,请参阅 Nsight Compute 入门。
NVIDIA Nsight Systems
CUDA 工具包 12.4 还包括 NVIDIA Nsight Systems,这是一款性能调整工具,可以在统一的时间轴上分析硬件指标以及 CUDA 应用程序、API 和库。
Nsight Systems 提供了多节点分析脚本,即 recipe。这些脚本可以自动分析跨数据中心捕获的指标,帮助您诊断性能限制因素。新的 recipe 提供了关于 NVIDIA 集合通信库 (NCCL) 的执行时间信息。此外,对多节点分析的支持已扩展至 Mac、Windows x64 和 Linux Arm 服务器。
如需详细了解 Nsight Systems 中的新功能,请参阅 Nsight Systems 入门。如需深入了解 Nsight Systems 如何支持数据中心规模的开发,请参阅 借助 NVIDIA Nsight Systems 加速数据中心和 HPC 性能分析。
总结
CUDA 工具套件 12.4 版增强了基础 NVIDIA 驱动和运行时软件,为加速计算提供支持,同时继续为最新的 NVIDIA GPU、加速库、编译器和开发者工具提供增强支持。
想要了解更多信息?请查看 CUDA 文档,浏览最新的 NVIDIA 深度学习学院 产品,并访问 NGC 目录。提出问题并加入讨论,CUDA 开发者论坛。




