我们的 NVIDIA AI 红队 专注于在数据、科学和 AI 生态系统中扩展安全开发实践。我们参与 开源安全倡议,发布 工具,并出席了 行业会议,主办 教育竞赛 并提供 创新培训。
最近发布的 Meta Kaggle for Code 数据集为大规模分析机器学习 (ML) 研究和实验竞赛代码安全性提供了绝佳的机会。我们的目标是利用这些数据来解答以下问题:
- ML 研究代码的安全状况如何?
- 安全组织如何改进 ML 研究人员的安全编码实践?
我们的分析表明,尽管有关于安全风险的公开文档以及相对顺畅的高级安全工具,ML 研究人员仍继续使用不安全的编码实践。我们的理论认为,研究人员优先考虑快速实验,并且不会将自己或其项目视为目标,因为他们通常不运行生产服务。
此外,Kaggle 环境可能会因为与研究人员的“真实基础架构”隔离而导致安全漏洞更加严重。但是,研究人员必须承认自己在软件供应链中的地位,并应意识到不安全的编码操作对其研究和系统带来的风险。
虽然解释和利用对抗性示例最初在 2015 年的研究论文中提出,但我们发现在 ML 研究流程中很少有证据表明采用了对抗性训练或评估。这部分原因可能是由于 Kaggle 比赛的结构和评分指标,但这与我们的其他研究和观察结果一致。然而,随着多模态模型的最新进展和基于图像的提示注入攻击得到证实,研究人员应优先考虑在对抗性条件和干扰下测试其模型。
观察
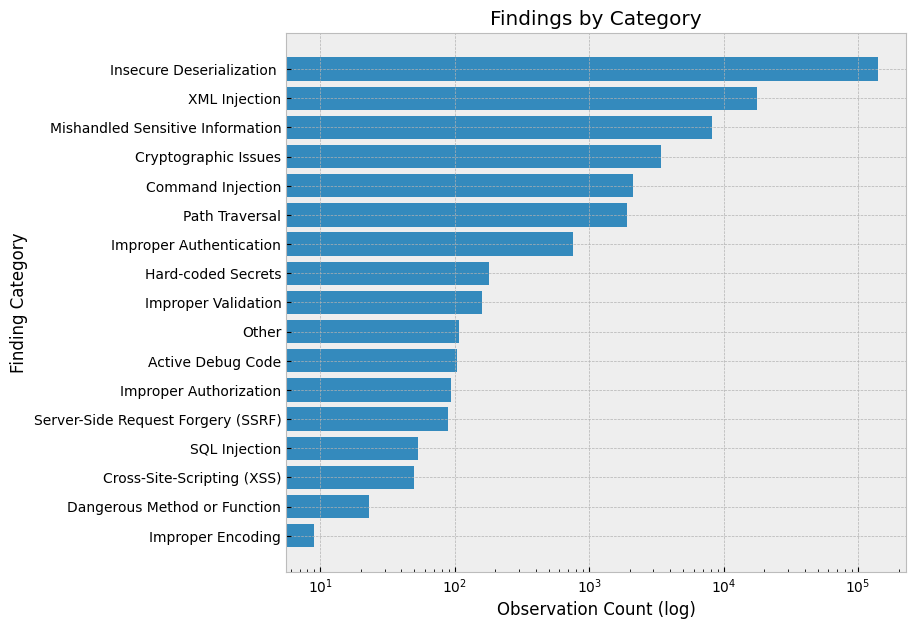
最重要的观察结果是明文凭据的使用、不安全的反序列化(主要是 pickle)、缺乏对抗性鲁棒性和评估技术以及拼写错误。重点关注这些主题的防御控制和教育。
明文凭据
研究人员仍然使用有效期较长的明文凭据,并将其提交给源控制。我们发现,第三方服务(如 OpenAI、AWS、GitHub 等)拥有 140 多个独特的活动明文凭据。对于某些凭据类型,这些凭据可能会与其他用户数据(如电子邮件)关联,从而使用户面临网络钓鱼和其他攻击。
为遵循协调漏洞披露相关的标准行业实践,我们于 2023 年 8 月 24 日向 Kaggle 报告了此凭据披露情况。他们已采取措施降低此风险。
不安全的反序列化
最常见的风险是不安全的反序列化。此外,许多 Notebook 都包含路径遍历迭代,这增加了恶意负载被执行的可能性。
例如,用户迭代特征目录和文件名重复执行以下命令:feature=np.load (feature_dir+fileName=`.npy`,allow_pickle=True)。
大多数 XML Injection 发现结果来自 pandas读取 html容易受到 XML 外部实体攻击的调用,并且大多数处理不当的敏感信息发现都与http而不是https:。
Pickle 仍然是标准
对于研究人员来说,pickle 模块实际上仍然是最常用的序列化格式。它是导入量最大的前 50 个模块之一,导入量接近 5000 个。ONNX 是一种更安全的 ML 模型序列化格式,但仅被直接导入了 9 次。pickle 模块也可能已经通过其他库中的内置序列化格式被间接使用。
例如,许多 NumPy 或 PyTorch 的序列化调用依赖于仍然基于 pickle 的内置保存方法。例如,我们确定了 45000 多个示例,其中 pickle 文件作为 pandas,joblib 和 NumPy 的反序列化。
缺乏对抗性再训练或测试
没有证据表明存在对抗性重新训练或测试。常见的对抗性重新训练和测试库,例如 Adversarial Robustness Toolbox (ART),Counterfit,TextAttack 以及 CleverHans 不会出现在任何导入中。对于常见的可解释性工具,Alibi,但是 Fairlearn 已被导入了 34 次。
其他的隐私保护训练技术,如联邦学习和差分隐私,也几乎完全不存在(除了联邦学习和差分隐私训练)。您可以尝试一次性导入 PyDP。
拼写错误
我们发现了一些拼写错误,例如 “熊猫” 和 “mathplotlib”,正确的应该是 “pandas” 和 “matplotlib” 等等。在 PyPI 上,恶意软件通过抢注拼写错误的域名进行传播,这是一种众所周知的手段。想要了解更多详情,请参阅 A PyPI Typosquatting Campaign Post-Mortem。
一些积极的方面
我们没有发现任何研究人员从易于在传输过程中被劫持或修改的来源加载序列化对象或模型的实例。此外,根据 Google 安全浏览查找 API。
推荐
尤其是在研究中,安全控制必须分层和校准,以尽可能减少对速度的影响。了解保护研究人员、研究和网络所需的控制,以及将成功的研究过渡到生产可能需要的其他控制。我们在下方列出的建议基于之前的观察结果。
开发替代方案,以取代在源代码中输入长期凭据
替代方案包括使用 secrets manager、环境变量、输入提示和提供短期令牌的凭据销售服务。多因素身份验证 (MFA) 还可减少源代码中泄露的凭据的影响。
经验反复表明,如果开发者在源代码中使用凭据,泄露的可能性会显著增加。这些数据可能会在数据集中泄露,意外提交到版本控制中,或者通过历史记录和日志记录进行披露,如我们在 2023 年 JupyterCon 的演示 中所示。
使用自动化在将错误提交到远程资源之前发现错误
版本控制系统如 GitHub 和持续部署系统如 Jenkins 通常是攻击者的“王冠”。使用 precommit hooks 运行安全自动化,并防止向这些目标广播本地错误。
制定指南、标准和工具,限制反序列化利用风险
我们的 pickle 的安全风险 文件有据可查,但仍然需要恶意攻击者拥有足够的访问权限和权限来执行攻击。我们的团队建议组织采用更可靠的序列化格式,例如 ONNX 和协议缓冲区。如果您的工具或组织必须支持 pickle,请执行可以验证的完整性验证步骤,而无需反序列化。
识别和减轻潜在的对抗性 ML 攻击
研发期间的漏洞会影响最终服务的安全性和有效性。了解针对 ML 系统的各种攻击,以构建适当的威胁模型和防御控件。如需了解详情,请参阅 NVIDIA AI 红队:简介。
例如,训练期间加入对抗性重新训练可以提高您的分类器在抵抗对抗性规避攻击方面的稳健性。在比较模型性能时,考虑将 对抗性稳健性指标 添加到您的评估框架中。如果您赞助 Kaggle 比赛,建议在评估数据集中添加对抗性示例,以奖励最可靠的解决方案。
考虑开发环境的生命周期和隔离情况
所有用户的分析代码都在 Kaggle 平台的临时环境中运行,与开发者的主机计算机隔离。然而,您的组织可能没有相同级别的租户隔离。在不不必要地阻碍研究人员的速度的同时,重要的是要考虑简单错误(例如拼写错误的导入语句)的潜在影响和爆炸半径,并努力确保域资源隔离和网络分割。
使用“allow/block lists”(允许/块列表)和内部构件存储库来存储构件,例如导入和数据集
考虑到这对研究速度的潜在影响,您可能需要考虑维护 内部仓库 的“已知良好”库和数据集,或者采用 import hooking 方案来降低恶意软件包安装和导入的风险。类似的数据集卫生状况可以提高安全性、再现性和可审计性。
方法
该数据集包含 Kaggle 上公开托管的大约 140GB 的 R、Python 和 Jupyter Notebook 源代码。Kaggle 允许用户保存版本,因此其中许多构件只是对其他文件的更新和更改。我们的分析仅限于 Python 文件和 Jupyter Notebook,2020 年 4 月至 2023 年 8 月期间,Kaggle 上执行的文件约有 350 万个。
虽然一些分析是手动进行的,但我们也严重依赖两个现有的开源安全工具,TruffleHog 用于识别凭据,而 Semgrep 用于执行静态分析。我们建议使用这些工具来复制我们的分析,并考虑将其纳入您的安全工具包。
为了识别和验证凭据,可以在 Docker 容器中针对源代码存储库或本地文件运行 TruffleHog.在此分析中,我们使用本地下载程序运行 TruffleHogdocker 运行 –rm -it -v “kaggle:/pwd” trufflesecurity/trufflehog:latest filesystem/pwd –json –only-verified > trufflehog_findings.json。
TruffleHog 还支持预提交钩子,以帮助确保凭据未提交到远程存储库和 CI/CD 集成,以持续监控泄漏。TruffleHog 能够针对 Kaggle 数据集运行,无需修改,我们根据唯一的机密值删除了重复数据。
Semgrep 是一种静态代码分析器,它使用规则来识别目标源代码中的潜在漏洞。由于 Semgrep 本身并不支持 Jupyter Notebook,因此我们使用了 nbconvert 在 Semgrep 处理之前将其转换为 Python 文件。我们使用了默认规则中的 162 条 Python rules 和 Trail of Bits 维护的规则,更专注于 ML 应用。
安装 Semgrep 后,在本地 Kaggle 下载环境中运行这两个规则集,semgrep –config=” p/trailofbits ” — config=” p/python ” –json kaggle/-o semgrep_founds.json。在分析期间,我们过滤掉了“Trail of Bits”(追踪位)的自动内存固定规则,因为我们找不到先前开发的直接路径或证据。
NVIDIA AI 红队将这些工具封装在一个名为 lintML 的项目中。要重现我们的结果,请使用 lintML – semgrep-options ” –config`p/python`- config`p/trailofbits`” <directory>。
限制
虽然我们对本次分析的数量感到自豪,但它仍然是“单一来源”,因为所有样本都是通过 Kaggle 收集的。虽然许多结果可能相同,但来自其他数据源的安全观察的基础分布可能会有所不同。
例如,对 GitHub 构件执行的类似分析可能会倾向于“更安全”,因为这些存储库更有可能包含生产代码。
此外,Kaggle 竞赛 奖励快速迭代和准确性,这可能会导致不同的库导入、技术和安全考虑因素,从而实现生产研究。例如,Kaggle 竞赛通常会提供必要的数据。在现实中,数据的来源、清理和标记通常是重要的设计决策,潜在的漏洞来源。
此分析同时受到我们使用的工具的启用和限制。如果 TruffleHog 中不存在凭据或验证器,则此处不会有相关发现。同样,Semgrep 分析受到我们选择的规则集的限制。这些发现中只有一部分可能是可利用的,但数量可能与总体项目风险相关。
此外,发现的数量分析可能会因规则的分布(更多的反序列化规则会产生更多的结果)而存在偏差。安全研究人员应继续使用现有的工具,如 TruffleHog 和 Semgrep,来进行与机器学习安全性相关的发现,正如 NVIDIA AI Red Team 所做的那样。NVIDIA AI Red Team 对于数据流和缺陷分析在机器学习应用程序中的应用特别感兴趣。
结束语
Kaggle 是一个实验、研究和竞争的场所。它奖励快速的实验迭代和性能,因此这些代码构件并不代表生产服务。
事实是如此吗?代码经常被重复使用,在研究期间会形成习惯,而默认设置是棘手的。在对 GitHub 上 300 多个排名靠前的机器学习存储库进行的类似分析中,我们仍然发现了第三方服务的硬编码凭据以及此处展示的所有结果。在研究期间提高安全意识以及信息和预防性控制有助于确保产品的安全,并提高企业的专业水平和安全状态。
安全专业人员应将此分析用作分析其组织中研发实践的基础。这些发现大多数代表基准安全控制。如果您开始在组织的研究代码中找到它们,它们就会发出与研发团队进行更彻底接触的信号。
使用类似的技术来评估机器学习开发周期中的伪影,以确保轻松的研究实践不会将风险传播到生产产品中。发现早期提供低摩擦工具的机会,而不仅仅是在生产交付流程中。利用前瞻性对抗评估和练习来增强教育、意识和合理的安全控制。
作为科学完整性的一部分,研究人员应专注于建立和维护良好的安全卫生。安全风险应被视为不需要的变量,应加以缓解,以确保实验的真实性。思考您向组织提取的数据和代码的来源。与安全团队联系,获取有关最佳实践和环境强化的指导。
正如您在严格测试假设时所做的那样,在测试您的项目时至关重要,并找出准确性可能不是您想要优化的唯一指标的机会,并考虑包括可靠性、可解释性和公平性测试。即使您不是在编写生产服务,您仍然可能会使自己、您的研究和您的组织面临潜在风险。
您可以使用我们的 安全实践笔记本 来开始分析这些数据,或者下载 Meta Kaggle Code 使用 TruffleHog 和 Semgrep 进行评估。 lintML 可以识别 ML 训练代码中的风险。
如需详细了解 ML 安全性,请查看 Black Hat Machine Learning 的 “黑帽欧洲 2023 (Black Hat Europe 2023)”。
致谢
我们要感谢 Kaggle 提供此数据集。这类数据有助于提高安全意识并为行业制定基准。NVIDIA AI Red Team 一直在努力与所在地区的 ML 从业者会面,而 Kaggle 一直是实现这一使命的出色合作伙伴和推动者。想要了解更多详情,请参阅 Improving Machine Learning Security Skills at a DEF CON Competition。我们还要感谢所有参与 Kaggle 竞赛的选手们对数据集的贡献。
此外,我们还要感谢 TruffleHog、Semgrep 和 Trail of Bits 提供的开源安全工具,这些工具为这项研究提供了支持,并感谢 Jupyter、pandas、NumPy 和 Matplotlib 提供的高质量数据分析和可视化工具。