在 2021 年,超过 4000 万人的健康数据被泄露,而且这个趋势并不乐观。
联邦学习和分析的主要目标是在不访问远程站点原始数据的情况下执行数据分析和机器学习。这就是您不拥有且不应该直接访问的数据。但是,如何更自信地实现这一点?
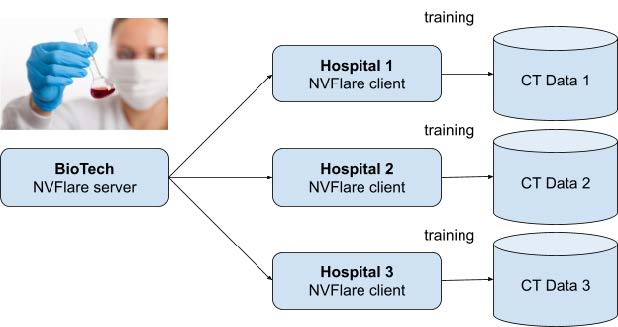
想象一个孤立的联邦学习场景,一家生物技术公司与医院网络合作。他们正在根据本地基础设施中存储的图像的 CT 扫描结果,合作开发改进的肺癌检测模型。
聚合器和生物技术数据科学家均不得直接访问图像或下载图像。他们只能对远程模型进行联合学习、训练和验证,并构建更好的聚合模型,然后与所有医院共享这些模型,以提高通用性和检测准确性。
数据保护的目标一开始似乎显而易见。这是一个权限、角色的问题,可能还有一些加密问题。遗憾的是,这并不像看上去那么简单。
联合隐私默认设置
联合学习解决方案往往侧重于以下方面:
- 传输信道安全
- 点对点信任(使用证书)
- 工作流程的效率
- 支持许多现有算法
所有这些都降低了从模型本身推理原始数据的风险。
然而,大多数产品和出版物都忽略了过于好奇的数据科学家的重要威胁。许多产品,无论是设计还是默认,都优先考虑近乎绝对的数据处理自由,让外部数据科学家能够针对远程数据发送任何查询或操作。
对于参与者之间几乎无限信任的网络,或者在不使用敏感数据的情况下,这是完全可以接受的设置。例如,网络可能用于演示目的,或者一切都可能发生在数据所有者组织的边界内。
当您想使用自定义训练和验证代码时,默认情况下 NVIDIA FLARE 就是这样工作的。
无论您使用何种加密方式、传输通道安全保证的强大程度,或者所有系统在组件漏洞上的更新程度如何,当您允许数据科学家针对远程数据发送任何查询或代码时,您都无法保证提供数据泄露保护。
相反,您完全依赖于个人或合同的信任级别。或者,您可能会在稍后通过分析针对联邦网络中不拥有的数据执行的操作和查询的日志来担心。
有一天,一位或多位数据科学家可能会放弃诚实。或者,损害可能是意外的,而不是恶意的。市场数据表明数据攻击来自内部。遗憾的是,内部威胁也在增加。
适当的员工教育、合同条款、信任、隐私意识和职业道德都很重要,但您应该使用技术措施提供更有力的保证。
应该怎么做
数据所有者应完全掌控:谁在何时对哪些数据执行什么操作。
记录所有与数据相关的操作通常是多个产品供应商承诺的解决方案。在数据泄漏的潜在损坏完成后,为时已晚。您必须在设计阶段主动预防此类情况。
现有权限系统怎么样?在 NVIDIA FLARE 的情况下,它可以开启或关闭,使远程数据科学家能够在远程站点上执行任何作业(本地策略)。此外,生物技术管理部门无法集中管理这些权限,因为他们能够远程覆盖本地策略。
其他解决方案基于可以信任任何内容的信任,选择将二进制 Docker 镜像从中央存储库推送到远程站点(医院)。这实际上消除了数据所有者的接受过程,因为他们只能信任图像的封闭框。从技术上讲,他们可以下载图像、加载图像并查看文件,但这在规模上是不切实际的。
有一种更实用的方法可用。
使用 NVIDIA FLARE 2.3.2 提升数据保护水平
以下介绍了如何显著降低数据泄露的风险及其在财务和声誉方面的所有后果。您可以兑现数据保护的承诺,这是我们卓有成效的合作成果,使用 NVIDIA FLARE 2.3.2 中引入的最新功能,这是联邦学习和分析的关键要素。
作业接受和拒绝要求
您需要一个解决方案,使数据所有者能够在发生之前审查要根据其数据执行的代码。实际上,在 NVIDIA FLARE 中,这意味着实现训练器、验证和联合统计数据以及配置设置的 Python 代码。
数据所有者应能够自行审查、接受或拒绝代码,或使用值得信赖的第三方审查者。如果没有数据所有者的明确接受,任何违反数据的行为都不应发生。
不得在一夜之间将作业代码从先前接受的代码更改为恶意代码。由于内容已发生变化,因此应拒绝作业代码,并且必须重新审查和重新接受。
解决方案
NVIDIA FLARE 2.3.2 支持自定义事件处理程序,这些处理程序可执行操作,以便在站点创建组件并由站点控制。
但为什么要创建对象?您不能只专注于执行吗?
由于过于好奇的数据科学家可以轻松地将代码注入对象初始化(构造函数),因此对象创建至关重要。尽早采取行动,防止数据所有者不想针对其数据运行的代码。
以下简化流程为默认值:
- 由外部数据科学家控制的中央服务器将作业提交给客户端。
- 客户端调度并执行这些作业。
- 如果代码包含向云上传数据,则实际上会执行 Python 允许的任何内容。
- 更糟糕的是,代码可能会随着每次作业提交而更改,并且不会被检测到或阻止执行。
作业从编排节点发送到本地节点以执行,其中包含代码和配置。
使用默认的 NVIDIA FLARE 配置构建联邦网络后,数据所有者会对外部数据科学家产生无条件的信任。然后,他们可以提交具有本地策略的作业。
更改后,使用自定义实现:
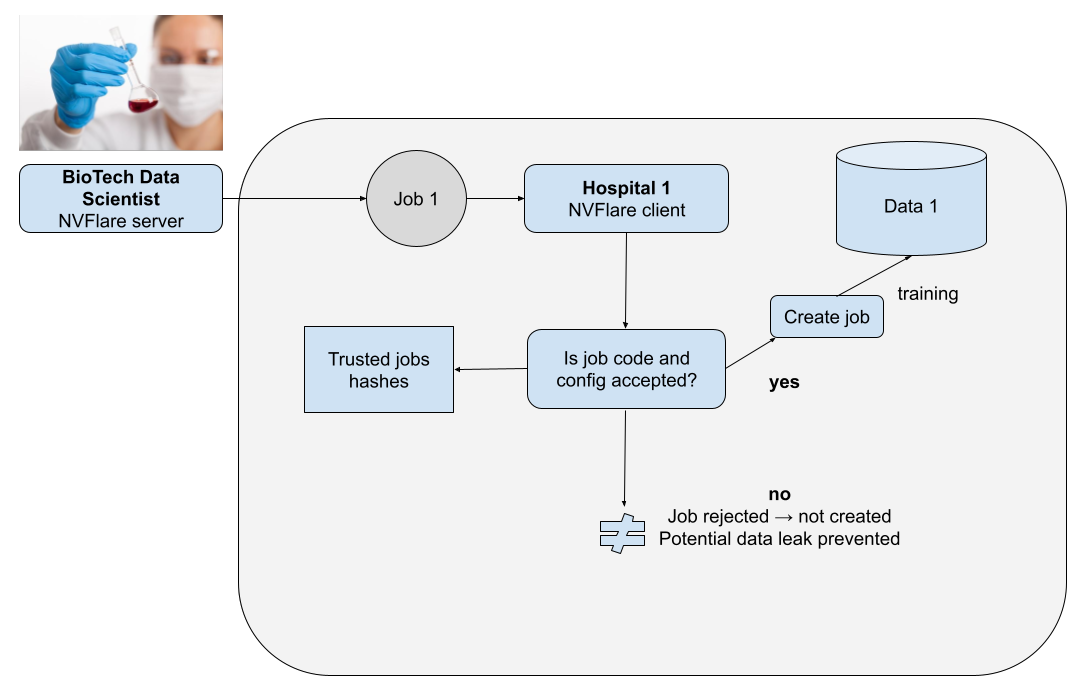
- 由外部数据科学家控制的中央服务器将作业提交给客户端。
- 数据所有者会审查作业代码,并从数据泄露风险的角度确定其是否可接受。
- 如果代码获得批准,则将哈希值添加到可接受的哈希值列表中。
- 作业代码(hash、签名)在站点本地与可接受的作业哈希列表进行检查。
- 作业在客户端上执行,结果返回至服务器。
以下是有关作业工作流程变化的更多详细信息。
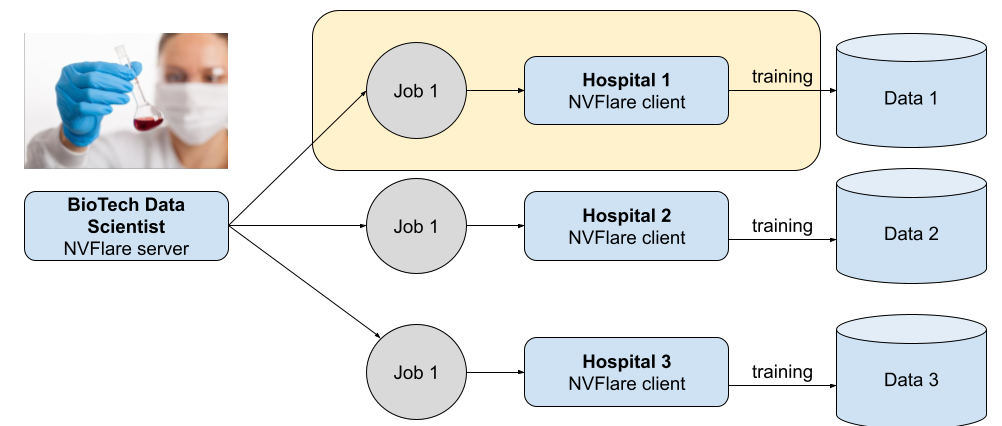
图 2 展示了由一个 BioTech 编排节点和三个医院节点组成的联合学习网络。同一联合训练作业从本地节点的编排节点发送。创建该作业甚至不会防止任何恶意代码作为作业对象初始化或构造函数的一部分。
图 3 展示了使用新型事件和事件处理程序接受和执行作业的流程。
作业代码接受策略
得益于 NVIDIA FLARE 2.3.2 中提供的基于事件的开放模型,我们可以实施任何合适的代码验证策略。此类策略必须始终在联合网络中设计、定义和商定,然后部署在每个节点(客户端,如医院)上。
出于演示目的,您可以将代码内容哈希与存储在其他目录中的可接受代码进行比较。
对于更真实的企业级场景,您还可以根据代码的数字签名,甚至由数据所有者信任的第三方提供的联合签名来提供实施。这与执行联合训练的生物技术无关。
代码示例
在实例化新组件(即作业)之前, NVIDIA FLARE 会引发 BEFORE_BUILD_COMPONENT 事件。您只需编写事件处理程序来分析代码并确定它是否被接受。对此没有一站式解决方案,因为不同的联合网络可能需要不同的策略。以下代码示例演示了此类处理程序。出于演示目的,此示例仅关注作业的子集。
focuses on a subset of jobs.
def handle_event(self, event_type: str, fl_ctx: FLContext):
if event_type == EventType.BEFORE_BUILD_COMPONENT:
# scanning only too curious data scientist jobs
if self.playground_mode:
meta = fl_ctx.get_prop(FLContextKey.JOB_META)
log.info(f"meta: {meta}")
if not "too-curious-data-scientist" in meta["name"]:
return
workspace: Workspace = fl_ctx.get_prop(key=ReservedKey.WORKSPACE_OBJECT)
job_id = fl_ctx.get_job_id()
log.debug(fl_ctx.get_prop(FLContextKey.COMPONENT_CONFIG))
log.debug(f"Run id in filter: " + job_id)
log.debug(f"rootdir: {workspace.get_root_dir()}, app_config_dir: {workspace.get_app_config_dir(job_id)}, app_custom_dir: {workspace.get_app_custom_dir(job_id)}" )
#making sure that approved_configs hash set is up to date (it's possible to update )
self.populate_approved_hash_set(os.path.join(workspace.get_root_dir(), self.approved_config_directory_name))
log.debug(f"Approved hash list contains: {len(self.approved_hash_set)} items")
# check if client configuration json is approved (job configuration)
current_hash = self.hash_file(os.path.join(workspace.get_app_config_dir(job_id), JobConstants.CLIENT_JOB_CONFIG))
if current_hash in self.approved_hash_set:
log.info(f"Client job configuration in approved list! with hash {current_hash}")
else:
log.error(f"Client job configuration not in approved list! with hash {current_hash}")
log.error("Not approved job configuration! Throwing UnsafeComponentError!")
raise UnsafeComponentError("Not approved job configuration! Killing workflow")
# check if all classes added to custom directory are approved
job_custom_classes = list(Path(os.path.join(workspace.get_app_custom_dir(job_id))).rglob("*.py"))
for current_class_file in job_custom_classes:
current_class_file_hash = self.hash_file(current_class_file)
if current_class_file_hash in self.approved_hash_set:
log.info(f"Custom class {current_class_file} in approved list!")
else:
log.error(f"Class {current_class_file} not in approved list!")
log.error("Not approved job! Throwing UnsafeComponentError!")
raise UnsafeComponentError(f"Class {current_class_file} not in approved list! with hash {current_class_file_hash}. Not approved job! Killing workflow")
如前所述,所有必需的上下文数据均由 NVIDIA FLARE 提供,以便能够执行必要的操作,例如查找自定义代码文件、计算其哈希值等。
还有更多
这并不能解决与数据保护相关的所有问题。但是,在所有情况下,数据所有者对远程数据科学家在没有看到数据的情况下基于数据训练模型的信任程度有限,因此解决这一问题势在必行。
虽然此功能不是针对恶意用户的决定性故障安全措施,但它提供了额外的保护层。它通过分担责任为节点提供支持,并促进协作研究。
接下来,考虑关注其他重要领域,例如:
- 模型推理攻击
- 差分隐私
- 传输信道安全
- 输出滤波器
总结
在联邦学习和分析的情况下,深度防御原则使得有必要保护数据所有者免受外部数据科学家发送的恶意远程代码的攻击。在真正的联邦场景中,当数据所有者和远程科学家之间没有完全信任关系时,这不是可选的。
远程数据不可访问的承诺并不能兑现;您必须为数据所有者授权。默认情况下,这并不能保证。
在本文中,我们演示了如何使用 Omniverse NVIDIA FLARE 2.3.2 来实现更好的数据保护,并构建现在和未来更安全的联邦学习网络。