在 3GPP 第五代 (5G) 蜂窝标准中,第 1 层 (L1) 或物理层 (PHY) 是无线接入网 (RAN) 工作负载中计算密集程度最高的部分。它涉及一些非常复杂的数学运算,其中包含复杂的算法,例如信道估计和均衡、调制/解调和前向纠错 (FEC).这些功能需要高计算密度,才能在不同的无线电条件下保持 5G 的低延迟要求和信号完整性。
传统上,此层是使用专用硬件实现的,例如带有数字信号处理 (DSP) 核心的专用集成电路 (ASIC).但是,这种方法有一些缺点,即无法扩展性能、硬件和软件紧密合以及封闭的单一供应商解决方案。所有这些都导致部署和运行 RAN 的成本高昂。
为应对这些挑战,该行业一直在向虚拟化 RAN (vRAN) 和开放 RAN (O-RAN) 架构转变,使用基于 x86 CPU 的商用现成 (COTS) 服务器。人们期望这将降低成本,而由此产生的硬件和软件分解将加快创新周期,引领云原生架构之路。
然而,由于 L1 的信号处理需求十分复杂,因此难以在基于 x86 CPU 的 COTS 服务器上实现理想的 vRAN 性能。为了解决这一 L1 性能差距,一些行业参与者正在构建固定功能加速器。示例包括独立 ASIC、现场可编程门阵列 (FPGA) 或集成系统级芯片 (SoC).
固定功能加速器补充了 CPU 性能,并加速了从 vRAN L1 管道卸载的一组选定功能的处理,同时保留了 CPU 内的大部分 L1 处理。这是一种加速方法,在业内被称为后备加速。
在许多方面,基于加速器的固定功能后备 vRAN 平台与设备类的宏基站架构模型类似,后者缺乏可扩展性和敏捷性。我们的行业需要一个完全软件定义的 vRAN,它可以提供可编程性、性能和软件可扩展性,同时支持互操作性和多供应商解决方案(O-RAN 的关键原则)。
随着人工智能和机器学习 (AI/ML) 成为塑造 5G 以外格局的关键驱动力之一,业界采用面向未来的 vRAN 平台同样重要。该平台应准备好在现有 RAN 基础设施上启用 AI/ML 等新功能作为增强功能。
NVIDIA Aerial 平台
NVIDIA Aerial 平台将适用于 5G 的 NVIDIA Aerial vRAN 堆栈、AI 框架和加速计算基础设施相结合。它通过使用 GPU 的高度可编程性和并行处理能力来实现主要优点。该平台与传统的固定功能后备加速方法的区别有两个方面:
- 它不使用任何固定功能加速器
- NVIDIA Aerial 不是选择性地将 L1 函数子集卸载到加速器,而是在 GPU 中实现整个 L1 处理管线,这种方法称为在线加速。
NVIDIA Aerial vRAN 堆栈是完全可编程、软件定义、支持 AI 的云原生 5G vRAN。有关 NVIDIA Aerial 入门指南的更多信息,请参阅 NVIDIA cuBB GPU Accelerated 5G vRAN,这是 2019 年世界移动通信大会的主题演讲。
本文的目标是展示基于 GPU 的内联架构 NVIDIA Aerial 的优点。我们解释为什么可编程的内联加速是提供高性能、高能效、可扩展的云原生 vRAN 的关键基础。
了解后备和内联加速模型
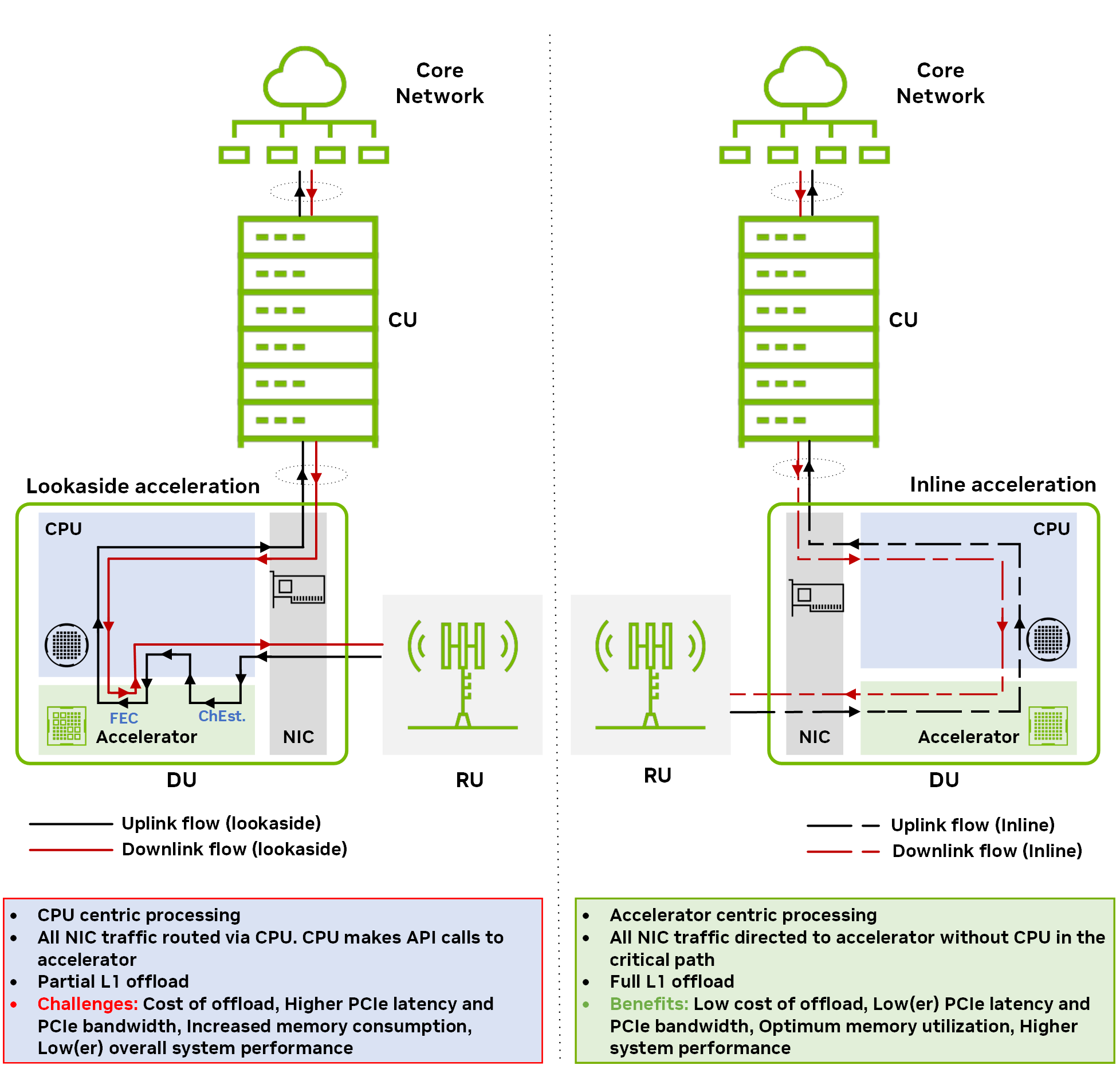
首先,研究 lookaside 和 Inline 加速模型的通用工作原理。
图 1 展示了两种不同加速模型的下行链路和上行链路方向的数据流:后备 和 内联。想了解更多相关信息,请参阅 Hardware Acceleration for Open Radio Access Networks: A Contemporary Overview。
在后备加速模型中,主机 CPU 向加速器调用数据处理卸载,并在处理完成后接收返回的结果。后备方法需要在 CPU 和加速器之间来回传输数据。如果有多个非连续的功能块卸载(例如 FEC 解码和通道估计),则主机到设备数据传输的开销和由此产生的内存带宽消耗会大幅增加。
在内联加速模型中,加速器直接与网络接口卡 (NIC) 交换数据,而无需在关键路径中涉及 CPU.对于内联模型中的完整 L1 加速,整个 L1 处理将卸载到加速器中。
与后备加速不同,内联加速不需要在主机和设备之间来回传输冗余数据。其最终效果是更高效地使用内存和 PCIe 带宽。
可编程的内联加速更适合 vRAN
详细了解基于两种加速方法的 vRAN 解决方案:
- 固定功能加速器
- 使用可编程加速器内联
在本节中,我们重点介绍每种加速器的优点和局限性,并解释为什么与固定功能加速器相比,可编程加速器的内联方法更适合 vRAN.
- 卸载成本会影响延迟和性能
- 服务质量保证会增加复杂性
- 后备加速器集成为 PCIe 设备,不等同于内联加速器
- 固定功能加速本质上不是云原生的
- 固定功能加速器缺乏可扩展性
- 固定功能加速器不灵活
卸载成本会影响延迟和性能
由于 CPU 和加速器之间 PCIe 接口中的请求/响应事务,后备加速会导致卸载成本。在多次来回事务(由于卸载一组非连续函数)的情况下,后备加速会增加 CPU 周期消耗和延迟,从而影响 perf/Watt 和 perf/$$.
为降低卸载成本,加速器驱动可能会将多个请求合并或批处理在一起。但是,这会导致不必要的缓冲和排队,从而显著提高各种用户数据流的延迟。
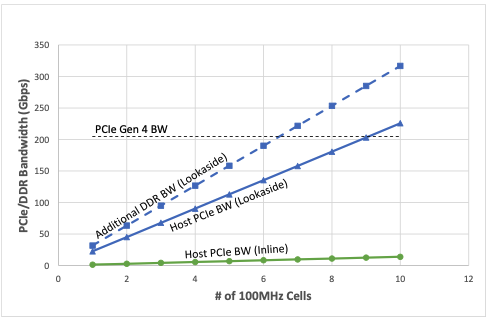
图 2 显示了随着受支持的 4-transmit-4 -receive (4T4R) 100MHz 单元数量的增加,预期的主机 PCIe 和双数据速率带宽 (DDR BW) 消耗 (Gbps).该图显示,使用后备加速器部署时,支持四个下行链路 (DL) 层和两个上行链路 (UL) 层(每个 100MHz 单元)所需的聚合事务带宽要糟糕得多。与内联加速器相比,所消耗的带宽大约增加了 40 倍。
还值得一提的是,随着单元数量的增加,PCIe 4.0 技术无法维持所需的带宽,需要 PCIe 5.0 技术来支持后备加速器。
服务质量保证会增加复杂性
细粒度 QoS 支持各种用户数据流是后备加速器面临的另一个挑战。PCIe 接口为满足 QoS 需求所需的复杂队列架构可能会导致性能下降,并影响加速器收到的排队请求的尾部延迟。
以 DU 系统为例,该系统支持互联网协议语音 (VoIP)、物联网 (IoT)、增强型移动宽带 (eMBB) 和超可靠的低延迟通信 (URLLC) 应用的混合用户数据流。在后备模型中,如果 VoIP 或 URLLC 数据包被卡在加速器排队的大量 eMBB 数据块后面,就会产生显著的延迟和抖动,并降低 QoS.随着每次交易都需要通过后备加速器,这可能会随着时间的推移而累积,从而导致严重的性能下降。
有一些方法可以通过 QoS 保证和跨 PCIe 界面的分层调度来解决这些问题。但是,这增加了硬件和软件的复杂性,导致成本和能耗增加,以及基站容量降低。
为了进一步证明部署内联加速器相比于观察加速器在容量和能效方面的优势,我们针对以下系统配置的两个指标评估了两种加速模式的性能:100 MHz、4T4R、4 个 DL/2 UL 层:
- 支持的 100MHz 单元数量
- MHz=每瓦层数
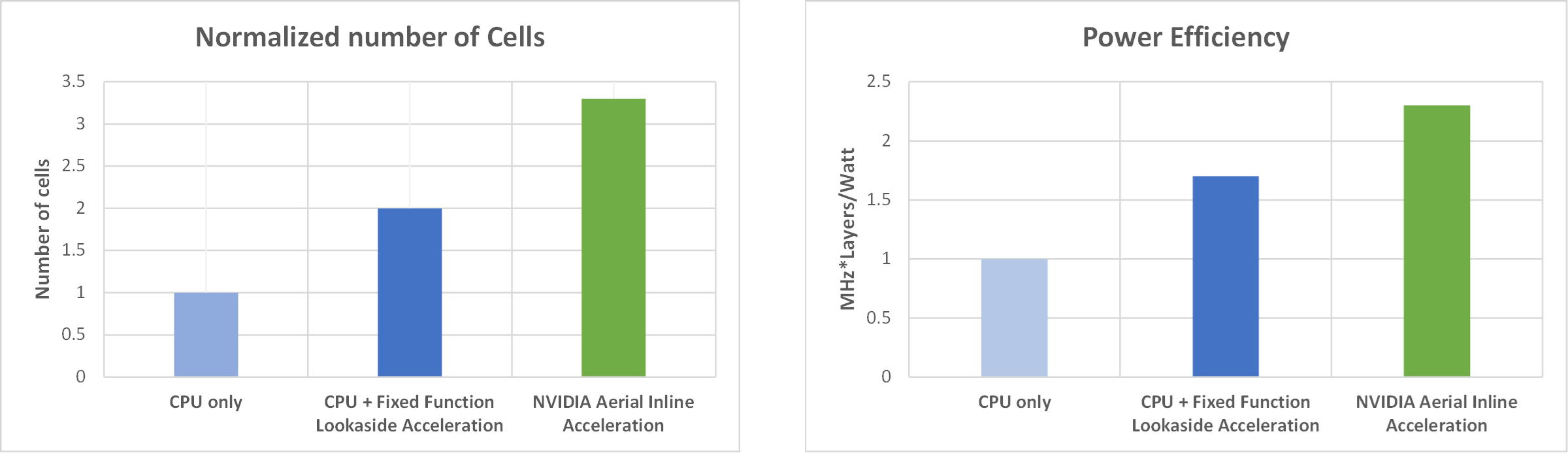
图 3 显示了性能比较,左侧显示支持的单元数量指标(标准化),右侧显示 MHz*层/瓦指标。对于每个指标,与固定功能后备加速器或无加速器(即仅使用 CPU)相比,在部署内联加速器时,单元容量和能效优势都很明显。
后备加速器集成为 PCIe 设备,不等同于内联加速器
有人认为,在 CPU 中集成后备加速器使其成为一种内联架构。没有什么能与事实相距甚远。
虽然集成可能会限制功率优化并降低组件价格,但 CPU 中集成的任何固定功能后备加速器(例如 FEC)仍然显示为 PCIe 设备,并通过 DPDK BBDEV 进行访问。最终结果是,固定功能后备加速器(无论它们是独立组件还是集成在 CPU 中)的效率都相同。
事实上,集成后备加速器会带来一系列新问题:管理特定的 CPU 库存单元 (SKU)、处理功能优先级、增加 CPU 成本等。
固定功能加速本质上不是云原生的
云计算的关键原则是,基础设施资源可以跨应用共享,从而提高利用率,并提供更好的规模经济效益。
固定功能加速器(例如基于 FPGA 的低密度奇偶校验 (LDPC)、基于 SoC 的 L1 high-PHY 等)是单用途加速器。如果 5G vRAN 未使用固定功能加速器,则会浪费资源,不会被任何其他应用程序使用。
典型的 5G 网络平均利用率低于 50%.这意味着固定功能的后备加速器只能位于云端,使用时间不会超过 50%.另一方面,GPU 等通用型可编程加速器可重复用于其他应用,例如大型语言模型 (LLM) 训练和推理、计算机视觉和分析。
数据平面开发套件基带设备 (DPDK BBDEV) 是一个常用于后备加速的应用程序编程接口 (API),但它不适合云原生部署。DPDK 包含许多专为高性能网络设备设计的结构,包括:
- 大型分页表
- 预分配缓冲区
- 固定显存
- 单根输入/输出虚拟化 (SR-IOV)
- 以队列为中心的 enqueue-dequeue 运算
但是,这些功能对底层硬件产生了强烈的亲和力,无法以真正的云原生方式实现无缝的可移植性和工作负载移动。
固定功能加速器缺乏可扩展性
固定功能加速器(如 FEC LDPC、离散里叶变换 (DFT)、逆 DFT (iDFT) 和其他选定的基带第 1 层函数)的一个主要缺点是,虽然它的大小可能适合一种配置或用例,但对于另一种配置来说则次优。
以 FEC LDPC 为例。在具有 4T4R 天线和 DDDSUUDDD 信道配置(D:下行链路、U:上行链路、S:特殊)和 4 个 DL/2 UL 层的典型 5G 频率范围 1 (FR1) sub-6 GHz 系统中,LDPC 解码器可能占 UL 插槽中物理上行链路共享信道 (PUSCH) 工作负载的 25%左右。
在保持其他配置不变的情况下,如果系统维度从 4T4R 扩展到 64T64R 天线配置(大规模 MIMO),LDPC 解码器在 PUSCH 管道上的计算负载不会相应增加。事实上,在这个更高维度的系统中,LDPC 约占总上行链路工作负载的 10%.
为什么会出现这种情况?这是因为 LDPC 解码器的复杂性仅随着层数呈线性扩展,而其他算法(例如信道估计或检测)则以超线性方式扩展。如果在固定函数加速逻辑中实现这些函数,这很容易从资源利用率和功耗的角度导致次优设计。
固定功能加速器不灵活
固定功能加速器很难随着 3GPP 版本(例如,具有新功能)的发展而发展,因为它们专为特定版本的规范而设计。在固定功能加速器上运行的这些复杂算法的升级很困难(尤其是在硬件中实施时),因此随着时间的推移会限制改进。此外,硬件问题修复存在问题,通常会导致昂贵的替换,因为这是唯一可行的解决方案。
总结一下,固定功能后备加速有几个缺点:影响性能和延迟、降低能效以及缺乏可编程性和可扩展性。这些问题直接导致电信运营商的资本支出 (CapEx) 和运营支出 (OpEx) 增加。
接下来,我们将讨论 NVIDIA 采用的替代方法,该方法通过利用可编程性和内联加速原则来解决之前强调的许多问题。该解决方案为行业领先的 vRAN 铺平道路。
NVIDIA Aerial:适用于 vRAN 的基于 GPU 的可编程内联加速
NVIDIA 采用了周全的架构方法,使用内联架构将 L1 级负载全部卸载到可编程 GPU。该架构使用 Bluefield DPUs 将所有前传增强型通用公共无线电接口 (eCPRI) 数据流量引入 GPU,而数据路径中无需使用 CPU。
自然要问的一个问题是,为什么要使用 GPU?5G PHY 的信号处理要求在计算方面具有挑战性,并因密集的矩阵运算而变得更加复杂。GPU 架构的大规模并行性为支持此类工作负载提供了合适的硬件资源。
从开发者的角度来看,GPU 的编程使用 CUDA 和 NVIDIA DLSS,这是一款在商业上非常成功的并行编程框架。这让您的工作变得更加简单,因为您可以使用成熟的工具和扩展库进行软件生命周期管理,包括规划、设计、开发、优化、测试和维护。GPU 在计算复杂的 AI 和机器学习领域的广泛应用证明了这一点。
第二个问题是,为什么选择内联架构?内联架构将 vRAN L1 的全部处理负载转移到 GPU,无需进行任何 CPU 交互。卸载的接口是功能应用程序平台接口 (FAPI),这是在 Small Cell Forum (小基站论坛) 中制定的行业标准 SCF。完全卸载避免了 CPU 和加速器之间在主机 PCIe 接口上产生的复杂且低效的乒乓球效应,从而提高了性能并降低了之前介绍的延迟。
NVIDIA Aerial 实现完全可编程、云原生、支持 AI 的高性能端到端 L1 高 PHY (7.2 倍拆分) 内联加速基于两个基本原则:
- 加速计算
- 快速 I/O
通过组件 CUDA baseband (cuBB),加速计算提供了 GPU 加速的 5G L1 信号处理管线的软件堆栈。cuBB 将所有 PHY 层处理保留在高性能 GPU 显存内,从而提供前所未有的吞吐量和效率。cuBB 包含了针对 NVIDIA GPU 高度优化的 5G L1 高 PHY 加速库 cuPHY,该库通过使用 GPU 的强大计算能力和高度并行性,提供了无与伦比的可扩展性。
通过 NVIDIA DOCA,快速 I/O 实现了 GPUNetIO 模组。该模组通过在 GPU 显存和内存之间直接交换数据包,提供了优化的 I/O 和数据包处理。 GPUDirect 支持 NVIDIA 的 ConnectX 智能网卡。实现快速 I/O 处理和直接内存访问 (DMA) 技术对于充分发挥在线加速的潜力至关重要。
为实现这一目标,NVIDIA Aerial 平台采用了以 GPU 为中心的方法,并使用 NVIDIA DOCA GPUetIO 库实施。在这种方法中,NVIDIA GPU 使用 GPUDirect Async Kernel-initiated Network (GDAKIN) 通信,用于配置和更新网卡寄存器,以编排网络收发操作,而无需 CPU 干预。有关更多信息,请参阅 Inline GPU Packet Processing with NVIDIA DOCA GPUNetIO。
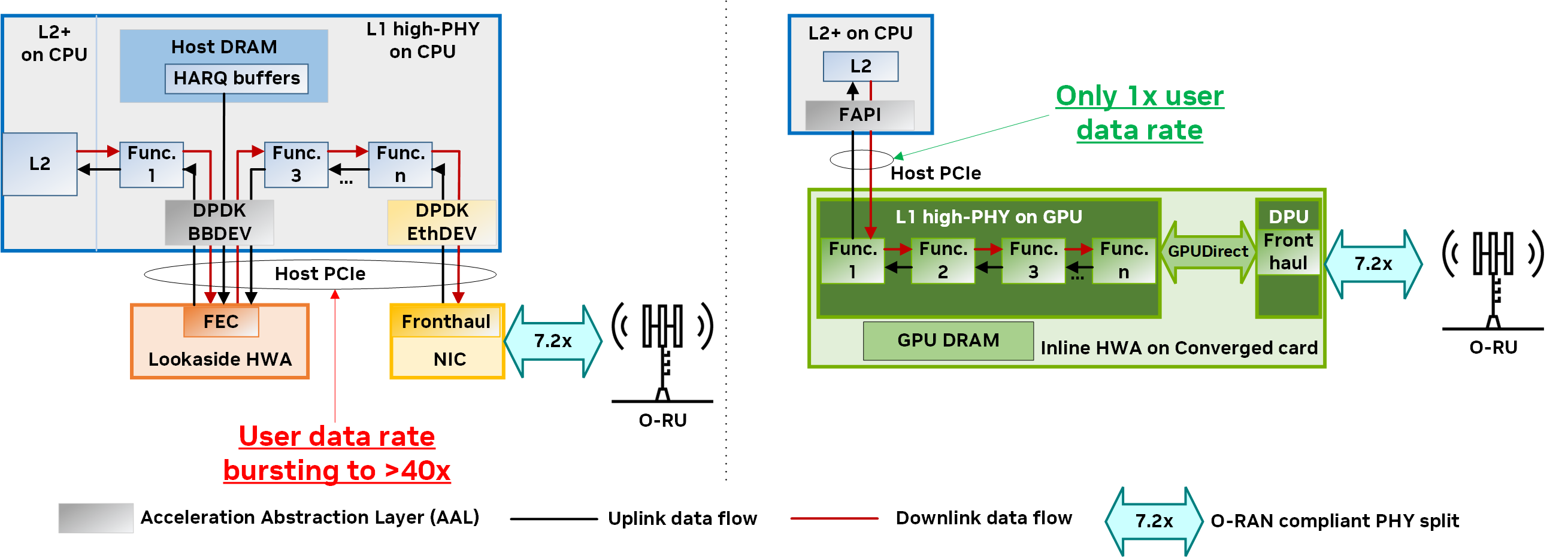
图 4 显示了使用 NVIDIA Aerial 的基于 GPU 的内联加速实现与基于固定功能硬件加速器 (HWA) 的典型后备加速之间 PHY 层的架构比较。在右侧, NVIDIA Aerial 平台提供快速、高效和精简的数据流,从 L2 到 L1 再到前回传,无需 CPU 暂存副本或限制主机 PCIe 带宽。
- L2 和 L1 (即 FAPI)之间的更高级别的加速抽象层 (AAL)
- 采用 GPU 和 DPU 的融合架构
- 由 NVIDIA DOCA GPUNetIO 和 GPUDirect 技术提供支持的互连技术
由于整个 L1 处理流程和相应的数据都包含在同一融合卡上的 GPU 内核和动态随机存取内存 (DRAM) 中,因此 NVIDIA Aerial 不会使用 L2+ 级的关键共享资源(例如,主机 DRAM 或主机 PCIe),这与传统的后备架构(左)有所不同。
在处理整个 L1 工作负载时, NVIDIA Aerial 平台的 CPU 核心消耗更少,且具有高度的 GPU 并行性,可提供更低的资本性支出和运营性支出解决方案,并具有出色的性能、可扩展性、敏捷性、可编程性和能效。
NVIDIA Aerial 满足了关键要求
表 1 简要介绍了 5G vRAN 的关键要求、固定功能加速器的后备架构在满足这些要求方面的局限性,以及 GPU 可编程加速器的内联架构在解决这些缺点方面的优势。
| 要求 | 固定功能后备架构 | GPU 可编程内联架构 |
| 高性能和低延迟 | 跨 PCIe 的多个请求和响应会导致 CPU 消耗增加,并导致 perf/Watt 和 perf/$$更加糟糕。由于后备请求的批处理和排队,L1 处理延迟更高。 | L2+L1+FH 简化处理流程,不会通过 PCIe 进行来回交易,从而实现更好的 perf/Watt 和 perf/$$.L1 运行时期间无缓冲/排队,从而优化 L1 处理延迟。 |
| 云经济 | 不得重复使用:仅具有“固定”功能,且不可与云基础设施中的其他应用共享。 | 完全可编程且通用,从而提高资源利用率。 |
| 应用程序可移植性 | DPDK BBDEV:由于与硬件的亲和力强,因此不容易移植。 | FAPI:在 L2 和 L1 之间使用更高级别的抽象实现更好的可移植性。 |
| 可扩展性 | 针对特定系统配置进行设计和优化。 | 完全可编程和可扩展,适用于各种系统配置。 |
| 敏捷性 | 无法编程,设计周期长,并且难以根据不断发展的标准和算法进行更新。 | 完全可编程和软件定义,易于更新,以适应不断发展的标准和新算法。 |
结束语
在本文中,我们重点介绍了固定功能加速器和后备处理模型的低效性。我们向您展示了后备模型如何影响性能和能效,以及许多可扩展性挑战。
具有可编程加速器的内联处理模型解决了固定功能后备加速模型的技术瓶颈,并在各种 RAN 配置中提供高性能、高能效和可扩展性。
NVIDIA Aerial 是唯一能够实现新兴 vRAN 关键原则的商用平台:高性能、软件定义、基于 COTS、云原生和 AI 就绪。它实现 GPU 可编程的内联处理模型和完整的 L1 卸载,通过完全符合 O-RAN 标准的软件架构为各种 RAN 配置和用例提供高效性能。
我们邀请您与我们合作,实现 RAN 基础设施的现代化,并实现高效、高性能、可扩展、敏捷、云原生、完全软件定义和 AI 就绪的 vRAN.