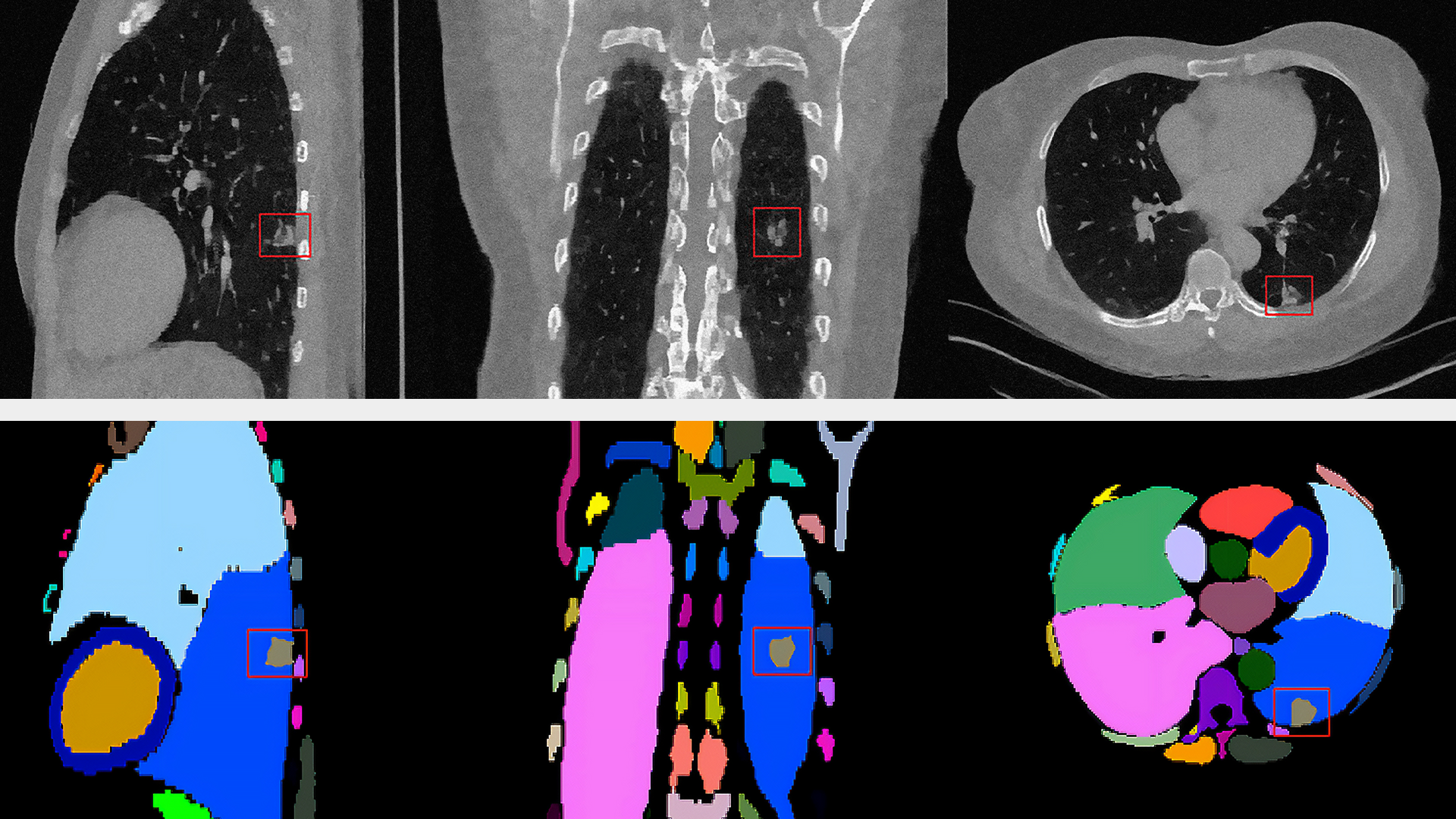
在 2023 年的人工智能领域,矢量搜索成为最热门的话题之一,因为它在大语言模型(LLM)和生成式人工智能中发挥了重要作用。语义矢量搜索实现了一系列重要任务,如检测欺诈交易、向用户推荐产品、使用上下文信息增强全文搜索以及查找潜在安全风险的参与者。
数据量持续飙升,传统的逐一比较的方法在计算上变得不可行。矢量搜索方法使用近似查找,这种查找更具可扩展性,可以更有效地处理大量数据。正如我们在这篇文章中所展示的,在 GPU 上加速矢量搜索不仅提供了更快的搜索时间,而且索引构建时间也可以更快。
此帖子提供:
- 矢量搜索简介及流行应用综述
- 在 GPU 上加速矢量搜索的 RAFT 库综述
- GPU 加速矢量搜索索引与 CPU 上最新技术的性能比较
本系列的第二篇文章深入探讨了每一个 GPU 加速指数,并简要解释了算法的工作原理以及微调其行为的重要参数摘要。想要了解更多信息,请访问 加速向量搜索:微调 GPU 索引算法。
什么是矢量搜索?

图 1 显示了矢量搜索需要创建一个矢量索引,并执行查找以在索引中找到一些最接近查询矢量的矢量。矢量可以小到激光雷达点云中的三维点,也可以是文本文档、图像或视频中的较大嵌入向量。
矢量搜索是查询数据库以查找最相似矢量的过程。这种相似性搜索是在可以表示任何类型对象的数字向量上进行的(图 2)。这些向量通常是从多媒体(如图像、视频和文本片段)或整个文档中创建的嵌入向量,这些文档经过深度学习模型将其语义特征编码为向量形式。
嵌入向量通常具有比原始文档更小的对象(维度更低)的优势,同时保持尽可能多的源信息。因此,两个相似的文档通常具有相似的嵌入向量。
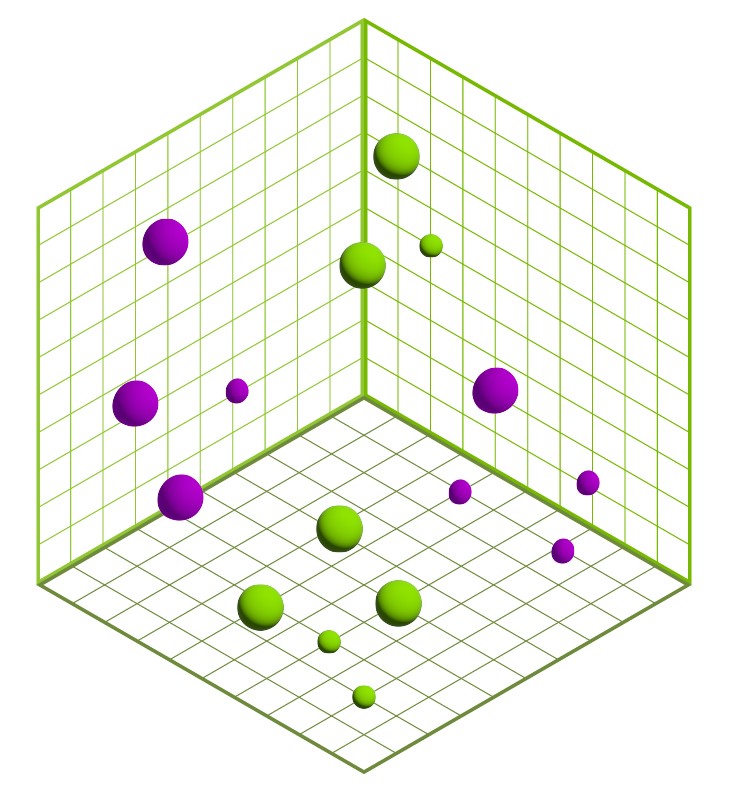
图 2 中的点是 3D 的,但它们可能是 500 维甚至更高。
这使得比较对象更容易,因为嵌入向量更小,并且保留了大部分信息。当两个文档共享相似的特征时,它们的嵌入向量通常在空间上接近或相似。
矢量搜索的近似方法
为了有效地处理较大的数据集,通常使用近似最近邻(ANN)方法进行向量搜索。神经网络方法通过逼近最接近的矢量来加快搜索速度。这避免了精确暴力方法通常需要的穷举距离计算,该方法需要将查询与数据库中的每个向量进行比较。
除了搜索计算成本外,存储许多向量还可能消耗大量内存。为了确保快速搜索和低内存使用率,必须以高效的方式对向量进行索引。正如我们稍后所概述的,这有时可以从压缩中受益。矢量索引是建立在数学模型上的一种空间有效的数据结构,用于一次有效地查询多个矢量。
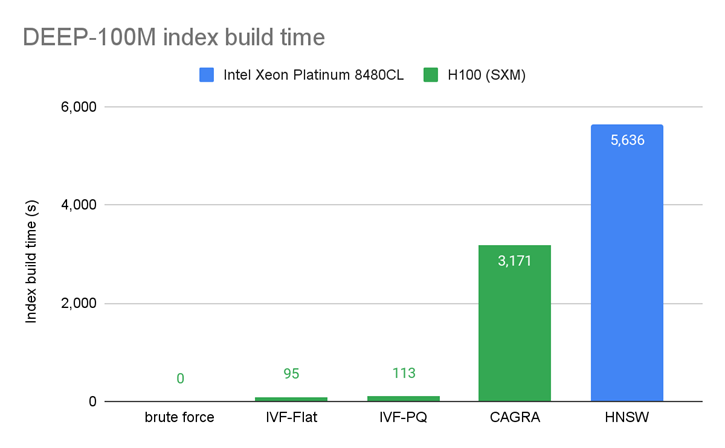
当索引需要数小时甚至数天才能建立时,更新索引(例如插入和删除向量)可能会导致问题。事实证明,这些索引通常可以在 GPU 上更快地构建。我们稍后将在帖子中展示这一表现。
LLM 中的矢量搜索
LLM 由于捕捉和保存原始文档的语义和上下文而变得流行起来。这意味着可以使用向量相似性搜索。此搜索可查找恰好包含相似单词、形状或移动对象的项目。它还发现了在上下文和语义上意味着相似事物的向量。
这种语义搜索不依赖于精确的单词匹配。例如,在图像数据库中搜索术语“我想买一辆肌肉车”应该能够将句子置于上下文中,以理解以下内容:
- 买车和租车不同,所以你希望找到更接近汽车经销商和购车者评论的载体,而不是租车公司。
- 肌肉车不同于健美运动员,所以你会期望找到道奇充电器的矢量,而不是阿诺德·施瓦辛格。
- 购买肌肉车与购买肌肉放松剂或经济型汽车不同。
最近出现了基于大型语言 transformer 的模型,如NeMo和 BERT,它们提供了重大的技术飞跃,提高了模型的上下文意识,使其更加有用,适用于更多的行业。
除了创建可以存储和稍后搜索的嵌入向量外,这些新的 LLM 模型还在管道中使用语义搜索,这些管道从通过查找类似向量收集的上下文中生成新内容。如图 3 所示,这个内容生成过程称为检索增强了生成人工智能。
在矢量数据库中使用矢量搜索
矢量数据库存储高维矢量(例如,嵌入向量),并促进基于矢量相似性的快速准确搜索和检索(例如,ANN 算法)。一些数据库是专门为矢量搜索而构建的(例如 Milvus)。其他数据库包括矢量搜索功能作为附加功能(例如 Redis)。
选择要使用的矢量数据库取决于工作流的要求。
检索增强语言模型允许通过使用已由 LLM 编码为向量并存储在向量数据库中的附加上下文来增强搜索,从而为特定产品、服务或其他领域特定用例定制预训练的模型。
更具体地说,搜索被编码为向量形式,并且在向量数据库中找到相似的向量以增强搜索。然后将向量与 LLM 一起使用,以形成适当的响应。检索增强 LLM 是生成人工智能的一种形式,它们彻底改变了聊天机器人和语义文本搜索行业。
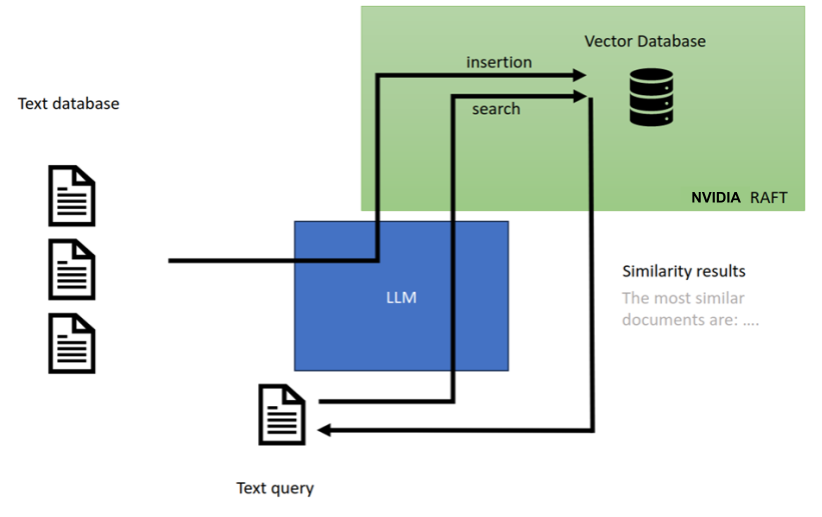
向量相似性搜索的其他应用
除了用于生成人工智能的检索增强 LLM 之外,嵌入向量已经存在了一段时间,并在现实世界中发现了许多有用的应用:
- 推荐系统:根据用户的兴趣或互动行为,提供个性化建议。
- 财务:欺诈检测模型将用户交易向量化,从而可以确定这些交易是否与典型的欺诈活动相似。
- 网络安全:使用嵌入向量对不良行为者和异常活动的行为进行建模和搜索。
- 基因组学:在基因组学分析中,我们可以发现相似的基因和细胞结构,如单细胞 RNA 分析。
- 化学:对化学结构的分子描述符或指纹进行建模,以便比较它们或在数据库中找到类似的结构。
我们总是有兴趣了解您的用例,所以如果您已经使用矢量搜索,或者想讨论它如何对您的应用程序有益,请不要犹豫,留下评论。
RAPIDS RAFT 矢量搜索库
RAFT 是一个可组合构建块库,用于加速 GPU 上的机器学习算法,例如最近邻居和向量搜索中使用的算法。ANN 算法是构成矢量搜索库的核心构建块之一。最重要的是,这些算法可以极大地受益于 GPU 加速。
有关 RAFT 的核心 API 及其包含的各种加速构建块的更多信息,请参阅RAPIDS RAFT 中的机器学习和数据分析的可复用计算模式。
用于快速搜索的人工神经网络
除了精确搜索的暴力法,RAFT 目前为 ANN 搜索提供了三种不同的算法:
- IVF-Flat
- IVF-PQ
- CAGRA
算法的选择可能取决于您的需求,因为它们各自提供不同的优势。有时,暴力甚至是更好的选择。更多内容将在即将发布的版本中添加。
由于这些算法没有进行精确的搜索,可能会遗漏一些高度相似的向量。这个 recall 度量可以用于表示结果中有多少邻居是查询的实际最近邻居。我们的大多数基准都以 85% 及更高的召回率为目标,这意味着检索到 85%(或更多)的相关向量。
要针对不同的召回级别调整结果索引,请在训练近似近邻算法时使用各种设置或超参数。降低召回率通常会提高搜索速度,而提高召回则会降低搜索速度。这就是所谓的召回-速度权衡。
想要了解更多信息,请访问 加速向量搜索:微调 GPU 索引算法。
性能比较
GPU 擅长一次处理大量数据。当一次计算数千或数万个点的最近邻居时,刚才提到的所有算法都可以优于 CPU 上的相应算法。
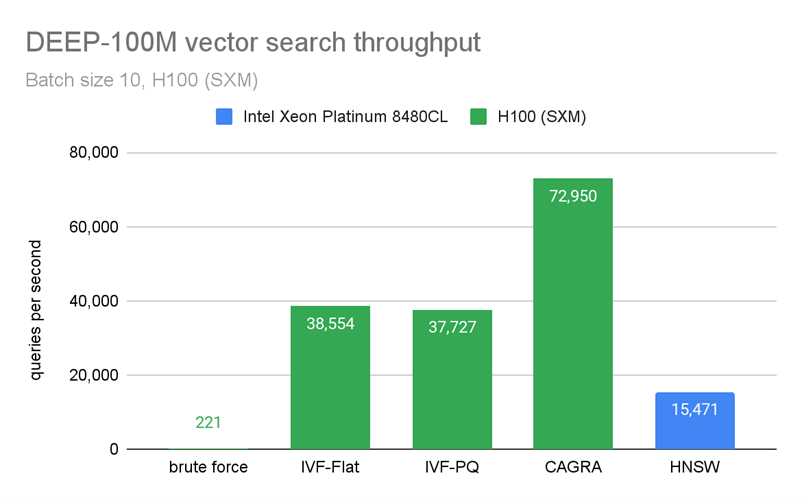
然而,CAGRA 是专门为在线搜索而设计的,这意味着即使一次只查询几个数据点的最近邻居,它的性能也优于 CPU 。
图 4 和图 5 显示了我们通过在 100M 向量上构建索引并一次只查询 10 个向量来执行的基准测试。在图 4 中,CAGRA 在原始搜索性能方面优于 HNSW,HNSW 是 CPU 上最受欢迎的矢量搜索索引之一,即使是 10 个矢量的极小批量。然而,这种速度是以内存为代价的。在图 5 中,您可以看到 CAGRA 的内存占用比其他近邻方法略高。
在图 5 中,IVF-PQ 的主机内存用于可选的细化步骤。
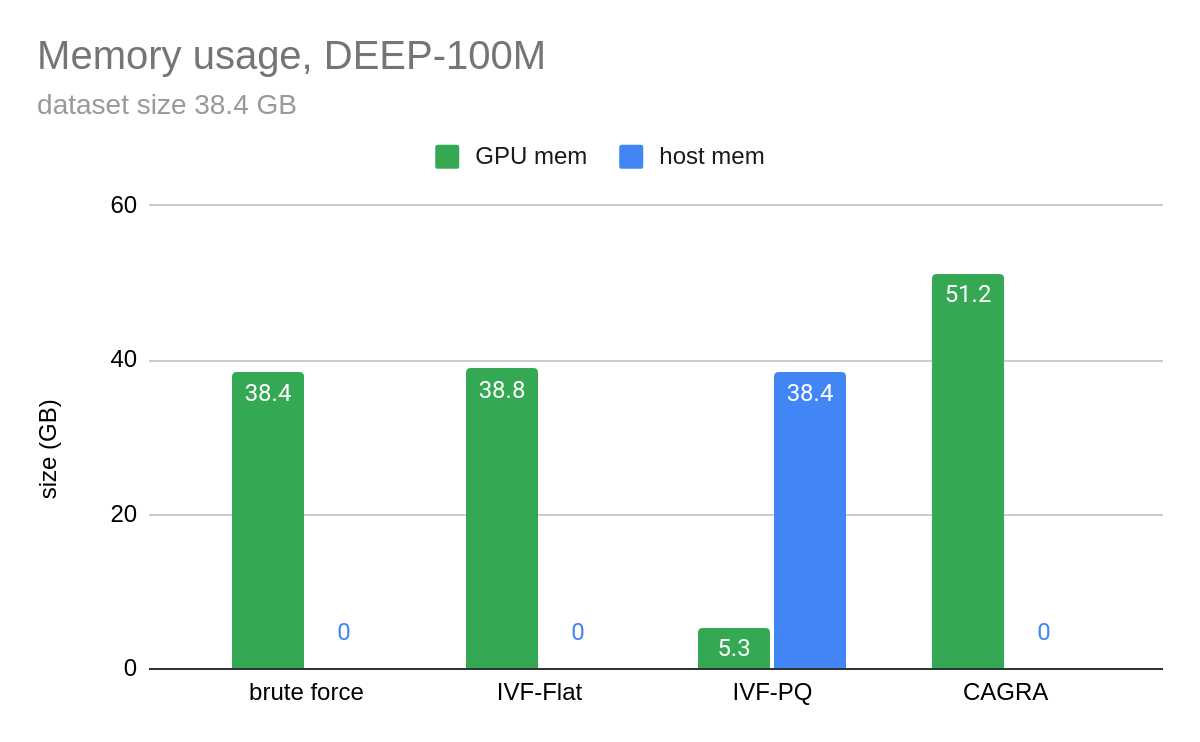
图 6 显示了索引构建时间的比较,并表明索引通常可以在 GPU 上更快地构建。
总结
从特征库到生成人工智能,向量相似性搜索可以应用于每个行业。 GPU 上的矢量搜索以较低的延迟执行,并为在线和批量处理的每一级调用实现更高的吞吐量。
RAFT 是一组可组合的构建块,可用于加速任何数据源中的矢量搜索。它为 Python 和 C++预先构建了 API。Milvus、Redis 和 FAISS 的 RAFT 集成正在进行中。我们鼓励数据库提供商尝试 RAFT,并考虑将其集成到他们的数据源中。
除了最先进的 ANN 算法,RAFT 还包含了如矩阵和向量运算、迭代求解器和聚类算法等其他 GPU 加速构建块。在本系列的第二篇文章中,我们深入探讨了每种 GPU 加速索引方法,并简要解释了算法的工作原理,以及总结重要的微调参数。有关详细信息,请参阅 加速向量搜索:微调 GPU 索引算法。
RAPIDS RAFT 是完全开源的,您可以在 /rapidsai/raft GitHub 上查看。您也可以在 Twitter 上关注我们 @rapidsai。