
今天,英伟达宣布推出 cuSPARSELt,版本 0 . 2 . 0 ,它提高了激活函数、偏差向量和批处理稀疏 GEMM 的性能。现在可以免费下载此软件。
有什么新鲜事吗?
- 支持激活函数和偏差向量:
- 所有内核的 ReLU +上限和阈值设置。
- 用于
INT8I / O 、INT32张量核心计算内核的 GeLU 。
- 支持批处理稀疏 GEMM :
- 单个稀疏矩阵/多个密集矩阵(广播)。
- 多重稀疏和稠密矩阵。
- 批处理偏置矢量。
- 兼容性说明:
- cuSPARSELt 不需要nvrtc再也没有图书馆了。
- 对 Ubuntu 16 . 04 ( gcc-5 )的支持现在已被弃用,并将在未来的版本中删除。
有关更多技术信息,请参阅 cuSPARSELt Release Notes 。
cuSPARSELt
NVIDIA CUSPASSELT 是一个高性能 CUDA 库,专用于一般矩阵运算,其中至少有一个操作数是稀疏矩阵:
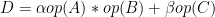
在这个等式中, 

cuSPARSELt API 在算法/操作选择、尾声和矩阵特性(包括内存布局、对齐和数据类型)方面提供了灵活性。
主要特征
- NVIDIA Sparse MMA 张量核支持
- 混合精度计算支持:
FP16I / O 、FP32张量核累加。BFLOAT16I / O ,FP32张量核累积。INT8I / O ,INT32张量核计算。FP32I / O ,TF32张量核心计算。TF32I / O ,TF32张量核心计算。
- 矩阵修剪和压缩功能。
- 自动调谐功能(请参见 cusparseLtMatmulSearch() )。
了解更多
- 有关数学库的更多信息,请参见 Recent Developments in NVIDIA Math Libraries ( GTC 2021 # S31754 )。
- 要获取 HPC 软件的最新信息,请参阅 A Deep Dive into the latest HPC software ( GTC 2021 # S31286 )。
- 赶上 Tensor Core-Accelerated Math Libraries for Dense and Sparse Linear Algebra in AI and HPC ( GTC 2021 # CWES1098 )。
- 请阅读 cuSPARSELt Product Documentation 中的技术详细信息。
最近的开发者帖子
- 有关高级矩阵乘法技术,请阅读 Accelerating Matrix Multiplication with Block Sparse Format and NVIDIA Tensor Cores.
- 要利用 NVIDIA 安培体系结构性能,请阅读 Exploiting NVIDIA Ampere Structured Sparsity with cuSPARSELt 。
- 要从 A100 加速中获益,请阅读 Getting Immediate Speedups with NVIDIA A100 TF32 。
- 要获得 AI 培训的好处,请参阅 Accelerating AI Training with NVIDIA TF32 Tensor Cores 。




