
云计算的出现使我们的数据存储和利用实践发生了范式转变。企业可以通过利用云服务提供商巧妙管理的远程按需资源,绕过管理自己的计算基础设施的复杂性。然而,人们对与云共享敏感信息有着明显的担忧。
虽然 AES 等传统加密方法有助于保护数据隐私,但它们扼杀了云对数据进行有意义操作的能力。在加密系统中,一种消息,也称为明文,使用密钥转换为被称为密文的加扰版本。现有的加密方法可以确保恶意实体在没有正确密钥的情况下无法解密消息,也无法访问其内容。如果没有解密,密文本质上是荒谬的。
幸运的是,有一个解决方案:全同态加密(FHE),一种复杂而有效的加密技术。无论是在传输中、静止中还是在使用中,它都是数据的全面屏蔽。同态加密是一种独特的设计,它能够在保持密文安全的同时对密文执行操作。这种类型的操作修改密文的方式是,解密后,结果与对明文本身执行的操作相同。
FHE 通常被称为密码学的最终目标,它可以对密文执行任何计算功能。这项卓越的技术能够直接在加密数据上运行数千种算法,而不会损害底层明文。它直面与云计算相关的关键隐私问题,同时实现复杂的外包计算。
然而,使用 FHE 加密执行的操作往往比使用标准未加密数据执行的操作慢。此外,对于非专业人员来说,这项技术的当前应用可能对有效设置和管理具有一定的挑战性。
ArctyrEX:加速加密执行
NVIDIA Research 的最近一项努力旨在解决与加密计算相关的效率问题。他们提出的解决方案,ArctyrEX,是一个端到端的框架,使您能够在 C++ 中使用标准数据类型来指定算法,并自动将此算法转换为 FHE 表示,该表示可以在任意数量的 GPU 上启动,以进行有效评估。
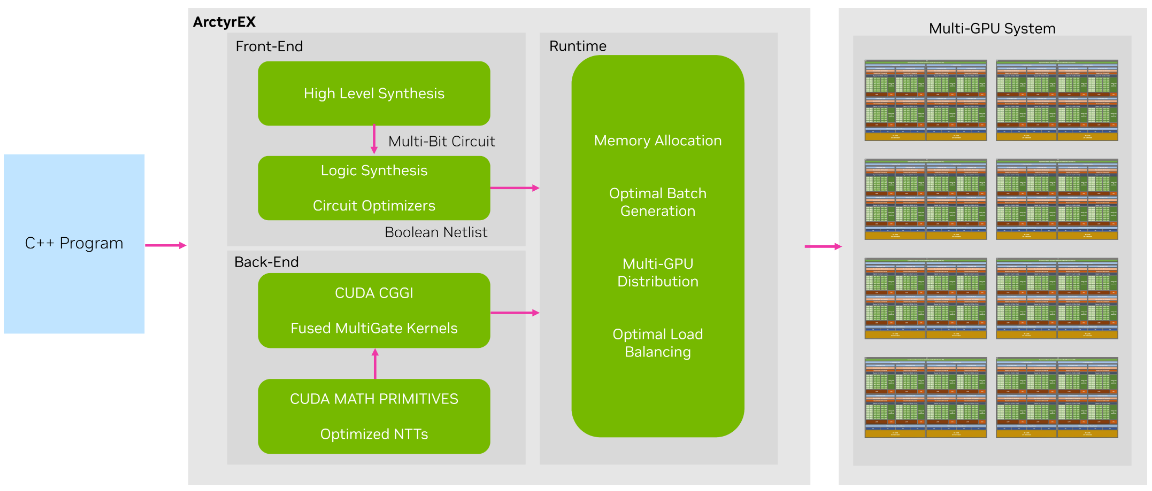
ArctyrEX 由三部分组成:
- 负责将输入程序转换到加密域的前端
- 一个运行库,用于向 GPU 工作者发送加密的工作负载
- 由最先进的 CGGI 密码系统的实现组成的后端。
CGGI 密码系统可以对明文的单个比特进行加密,并实现密文之间的加密布尔运算。因此,CGGI 的编程模型类似于构造由逻辑门组成的布尔电路。想要了解更多详细信息,请参阅 TFHE: Fast Fully Homomorphic Encryption over the Torus 和 TFHE。
前端利用数十年的硬件开发研究,将 C++程序转换为等效的 Verilog 文件,这些文件提供了高抽象级别的电路描述。然后它将文件转换为最佳布尔回路。该过程使用高级合成(HLS)和寄存器传输级(RTL)或逻辑合成形式的成熟技术。
ArctyrEX 运行库采用生成的布尔电路,将其划分为不同的级别,并创建大小大致相同的批以分发给 GPU 工作者。在某些情况下,与中间级别的门的输出线相对应的密文可能必须在下一级别期间用作分配给不同 GPU 的工作负载的输入。ArctyrEX 能够无缝高效地协调这些传输。
最后,ArctyrEX 后端由一个优化的 CUDA 内核组成,该内核能够同时执行多批门,同时最大限度地减少 CPU – GPU 同步。输出由一组密文组成,这些密文表示指定批次中的门的输出线。
使用 ArctyrEX 运行程序的速度高达 40 倍
ArctyrEX 通过使用更多 GPU 显示出强大的可扩展性,主要有两个原因:
- 大量的基元级并行这是大多数 FHE 操作的自然特征。
- 电路级并行性,这是布尔电路中通常显示的特性。
为了用布尔 FHE 实现快速评估,电路必须具有宽的电平,这意味着应该有许多门可以同时操作,并且它应该具有最小的临界路径。为了说明这一点,将两个矢量之间的加密点积运算与加密矢量相加运算进行比较。
要在 ArctyrEX 中实现这些程序,您可以以直观的方式编写高级 C++ 代码。在这里,pragma 是在 HLS 传递之前展开循环所必需的 XLS,其目标是使数字设计更易于接近和高效。XLS 提供了一种在比传统硬件描述语言(如 Verilog 或 VHDL)更高级别(如 C++)指定数字逻辑的方法,使整个过程更简单、更高效。
例如,观察两个矢量之间的加密点积和加密矢量相加之间的差异。要在 ArctyrEX 中实现这些程序,您可以通过以下方式直观地编写高级 C++代码,其中需要 pragma 在 Google XLS 处理的 HLS 传递之前展开循环:
void vector_addition(int x[500], int y[500], int z[500]) {
#pragma hls_unroll yes
for (int i =0; i < 500; i++)
z[i] = x[i] + y[i];
}
short dot_product(short x[500], short y[500]) {
short product = 0;
#pragma hls_unroll yes
for (int i = 0; i < 500; i++)
Product = product + x[i] * y[i];
return product;
}
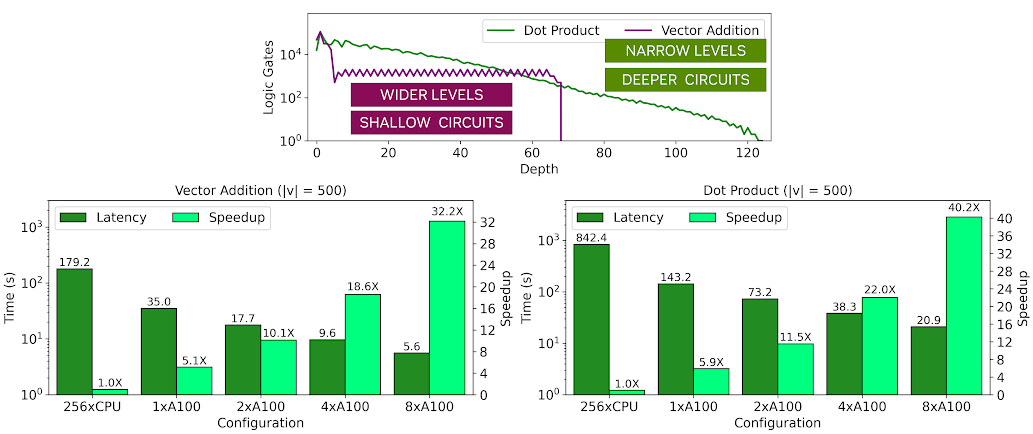
图 3 显示了两个电路的特性,特别是电路每一级的逻辑门数量。在图表中,|v|表示向量长度,M 表示矩阵的维数。你可以看到,两个矢量的点积具有更高的临界路径,深度约为 120 个电平,随后电平的宽度逐渐减小,限制了电路后期可能利用的并行性。
另一方面,矢量加法的临界路径比点积短大约 2 倍,并且每个级别的宽度保持相对恒定。因此,矢量相加的速度比点积快约 4 倍,尽管两者在具有多个 GPU 的平行 CPU 基线上都表现出高加速。这些有趣的性能趋势显示在前面的拓扑图中。浅绿色条显示相对于 256 线程 CPU 基线的加速,而深绿色条显示同态应用程序的执行时间。
总结
总之,ArctyrEX 代表了一个跨各种应用程序的加密计算的综合解决方案,利用 GPU 加速的力量,并实现了高效 FHE 算法执行的创新技术。神经网络推理等任务随着 GPU 的增加而表现出线性加速,这归因于固有的电路级并行性、新引入的调度范式以及 CUDA 加速的 CGGI 后端所利用的广泛的原始级并行性。
想要获取详细信息,请参阅 “Accelerated Encrypted Execution of General-Purpose Applications” 论文,以及 NVIDIA GTC 2023 的现场演示 “ArctyrEX: Accelerated Encrypted Execution of General-Purpose Applications on GPUs”。
鸣谢
我们感谢 ArctyrEX 的所有作者的贡献,特别是 Charles Gouert(博士候选人)和特拉华大学的 Nektarios Georgios Tsoutsos 教授。我们还要感谢 Zama、CryptoLab、谷歌和 Duality Tech 的成员进行的富有洞察力的讨论,特别是 Ilaria Chillotti、Jung Hee Cheon、Ahmad Al Badawi、Yuri Polyakov、David Cousins、Shruti Gorantala 和 Eric Astor。



