Parabricks 4.2 版现已发布,进一步推进了其使命,即在基因组学测序分析中提供前所未有的速度、成本效益和准确性。最新版本为 Oxford Nanopore 测序提供了新的加速工作流程(在精选图像中),使 Parabricks 能够在最新的 NVIDIA GPU 上运行,并进一步推进了 Parabricks 的加速深度学习变体识别计划,以支持来自所有主要测序器类型的数据类型。
在一小时内分析长读全基因组
Parabricks v4.2 包含了升级的 WDL 和 NextFlow 工作流,这被视为部署 Parabricks 工具的最佳实践。您可以在 Parabricks 工作流程 GitHub 库中找到,包括短读和长读工作流。
最新版本的 Parabricks 提供更新的 Oxford Nanopore 种系工作流,可在 NVIDIA H100 GPU 上提供高速分析。
紧随其后的是 NVIDIA 在 2022 年发布的 超快速纳米孔分析流程 (UNAP),这个新的工作流程包括碱基识别、比对以及小型和结构化变体识别步骤。它已更新软件,从 Guppy 到多拉多,从 PEPPER-MARGIN-DeepVariant 到新集成的 DeepVariant 1.5 长读变体识别,并随 Parabricks v4.2 一起部署。
图 1 展示了 Oxford Nanopore 种系测序分析的工作流程。
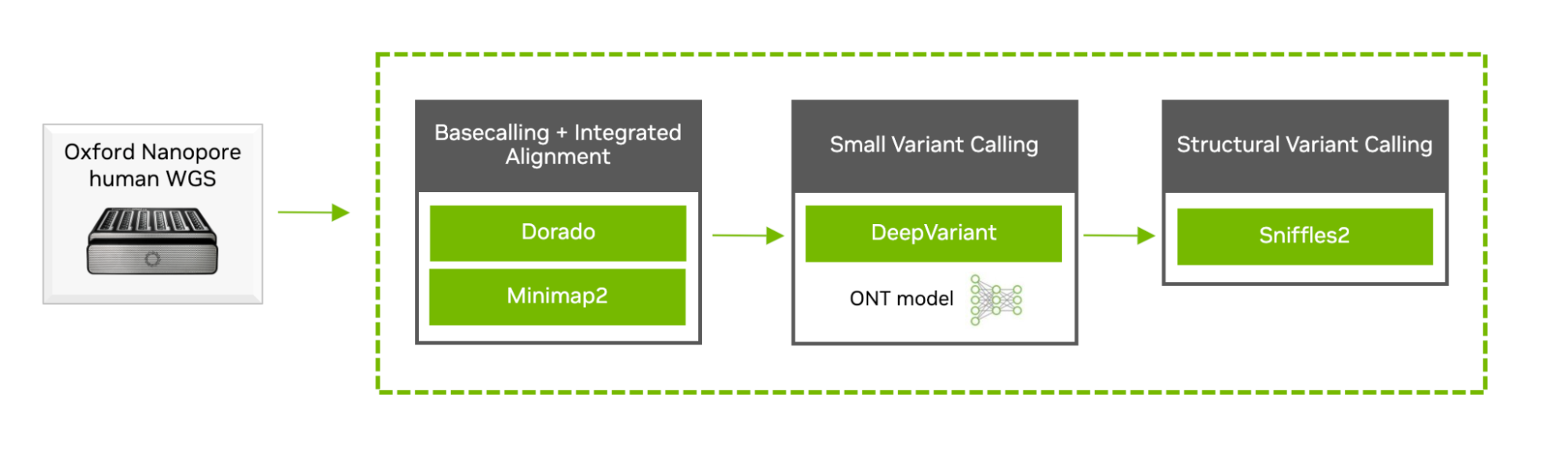
最新的 Oxford Nanopore 工作流程在 8 个 NVIDIA H100 GPU 上运行,Oracle Cloud 最近对其进行了基准测试,在单个 55 倍的全基因组覆盖度上实现了不到 1 小时的端到端运行时间。
高速 Oxford Nanopore 测序仪和 Parabricks 工作流程也有可能为临床测序提供快速周转时间。
在持续开发方面, NVIDIA 将与 Clinical Long-read Genome Initiative (lonGER) 联盟合作,对该工作流程进行进一步的基准测试和优化。该联盟由德国的四家研究所组成,旨在优化纳米孔数据的分析,包括及时得出结果和方法的临床级准确性,以确定最相关的临床基因组改变。
美国国立阿尔茨海默症及相关痴呆症健康中心 (CARD) 已经制定了一项大规模高精度全基因组测序的协议。该示例研究等展示了 Oxford Nanopore 测序和快速分析如何提供单倍型分辨率变异和甲基化的全面视图。
最近的自然方法论文中,CARD 团队介绍了如何利用 Oxford Nanopore 的 PromethION 使大规模、长时间的原生 DNA 测序项目成为可能,因为相比其他测序方法,它的成本更低,吞吐量更高。
使用经过优化的 DeepVariant 模型对所有测序仪进行高精度变异识别
DeepVariant 是基于 CNN 的高精度种系变体识别程序,作为 Parabricks 的一部分在 GPU 上进行加速。
最近,Parabricks v4.1 推出了一个加速框架,用于重新训练基础 CNN 模型,以更轻松地启用自定义模型,并为分析工作流程带来更准确的变体调用。这通过学习不同测序仪的错误配置文件或不同高吞吐量实验室中引入的独特构件来提高准确性。
Parabricks v4.2 现在随附针对各种测序仪数据类型预训练的加速模型,作为 Parabricks 中 DeepVariant 的一部分:
- Illumina
- Oxford Nanopore
- PacBio
- Ultima
- Singular
- … 以及更多
这些模型的加速系数可以达到 80 倍以上,从 CPU 实例上的几个小时到 NVIDIA GPU 上的不到 4 分钟。

在 NVIDIA GPU 上实现前所未有的速度
在高吞吐量设置中,通过 Parabricks 将基因组分析工作流转移到 GPU 可显著缩短处理时间。
例如,英国癌症研究所的 TRACERx EVO 是 TRACERx 的最新项目,这是全球最大的长期肺癌研究计划,由 Francis Crick Institute、伦敦大学学院和曼彻斯特大学的基础设施驱动。
Francis Crick Institute 的初步结果表明,使用 NVIDIA Parabricks 时,整个人类基因组的端到端分析(包括 FastQ 比对和深度变异识别)只需 2 小时多一点,而在其 NEMO CPU 集群上只需大约 13 小时。预计这一性能提升将在其最新 GPU 集群上进一步推进。
仅就 TRACERx EVO 项目而言,他们估计这将节省近 9 年的生物信息学处理时间,TRACERx EVO 首席研究员 Mark S.Hill 认为,这一改进“改变了项目分析流程的可行性”。
对于最新的 GPU 架构,最新的 NVIDIA Hopper 架构被称为全球 AI 基础架构的引擎,可为各种工作负载实现数量级的性能飞跃。
在数据中心运行的高性能计算应用程序受益于 NVIDIA Hopper 的多 GPU 可扩展性及其在 Tensor Core 技术方面的进步,这意味着 AI 推理速度比前几代产品提升了 30 倍等令人印象深刻的结果。
具体来说,对于基因组学,NVIDIA Hopper 架构包括 动态编程指令 (DPX),旨在解决复杂的递归问题。动态编程被广泛应用于多个领域,如图形分析或路线优化,包括在基因组学中使用的 Smith-Waterman 算法,这是大多数对齐器和多个变体调用器的基础。新的 DPX 指令将这些算法相比仅使用 CPU 的架构加速了 40 倍,与之前的 NVIDIA Ampere 架构相比,加速了 7 倍。
结合所有这些进步意味着,最新的 NVIDIA GPU 架构非常适合加速生物信息学工具,例如 BWA-MEM 对齐器(可在 8 个 NVIDIA H100 GPU 上运行仅需 8 分钟)或基于深度学习的 DeepVariant 变体识别器(可在 8 个 H100 GPU 上运行仅需 3 分钟)。这些运行时间意味着使用 H100 GPU 和 Parabricks 只需 14 分钟即可实现端到端种系工作流程。

NVIDIA Parabricks v4.2 现已在 NGC 上推出
Parabricks v4.2 无缝集成到基因组学工作流程中,通过 BWA-MEM 和 GATK 等工具持续支持成熟工作流程的 GPU 加速版本,并且能够快速训练自定义模型以进行 DeepVariant 变异识别。通过为新的 GPU 架构以及短读和长读测序设备提供这些功能,Parabricks 是一个真正的通用全栈加速平台,用于在 GPU 上进行黄金标准的基因组学分析。
Parabricks v4.2 容器现在可在 NGC 上的 NVIDIA Parabricks 集合 中找到。有关 WDL 和 NextFlow 参考工作流,请参阅 Parabricks 工作流程 GitHub 存储库。
想要了解更多关于 Parabricks 的信息,请访问全基因组测序分析,其中包括客户成功案例,大规模分析、测序仪和设备部署以及尖端研究。
如果您需要企业级支持,可以联系 NVIDIA 销售人员,以获得企业优势,包括与 NVIDIA 专家联系以确保大规模优化、保证关键支持响应时间以及企业培训服务。
如需详细了解面向云服务提供商的新增功能、教程和部署指南,请参阅 Parabricks 文档。
想要了解更多关于使用 Parabricks 扩展测序分析的信息,请参阅 NVIDIA DGX BasePOD 解决方案适用于基因组测序的白皮书。