
가정 및 산업 환경에서 대부분의 물체는 조립해야 하는 여러 부품으로 이루어져 있습니다. 조립은 일반적으로 인간 작업자가 하지만, 자동차와 같은 특정 산업에서는 로봇 조립이 보편화되어 있습니다.
이러한 로봇 대부분은 고도로 반복적인 작업을 수행하도록 설계되어 신중하게 엔지니어링된 설정에서 특정 부품을 처리합니다. 이 때 다품종 소량 생산 제조(즉, 다양한 제품을 소량으로 생산하는 프로세스)에서 로봇은 다양한 부품, 포즈 및 환경에 적응해야 합니다. 따아서 높은 정밀도와 정확도를 유지하면서 이러한 적응성을 달성하는 것은 로보틱스 분야에서 매우 중요합니다.
NVIDIA Isaac을 사용한 새로운 시뮬레이션 접근 방식을 통한 로봇 조립의 발전에서 자세히 설명한 것처럼 접촉이 많은 상호작용을 실시간보다 빠르게 시뮬레이션하는 NVIDIA의 최근 개발 덕분에 로봇 조립 작업(예: 삽입)의 시뮬레이션이 가능해졌습니다. 이를 통해 데이터 집약적인 학습 알고리즘을 사용하여 시뮬레이션된 로봇 에이전트를 훈련할 수 있습니다
로봇 조립을 위한 시뮬레이션에서 현실로의 전이에 대한 후속 작업에서는 강화 학습(RL)을 사용하여 시뮬레이션에서 소수의 조립 작업을 해결할 수 있는 알고리즘과 학습된 기술을 실제 세계에 성공적으로 배포하는 방법을 소개했습니다. 자세한 내용은 산업용 로봇 조립 작업을 시뮬레이션에서 현실로 이전을 참조하세요.
이 게시물에서는 로봇의 팔로 다양한 기하학적 형태의 부품을 조립하는 스페셜리스트 및 제너럴리스트 기술을 트레이닝하기 위한 새로운 프레임워크인 AutoMate를 소개합니다. 트레이닝된 기술의 제로샷 시뮬레이션에서 실제로의 전이 즉, 시뮬레이션에서 학습한 조립 기술을 추가 조정 없이 실제 설정에 직접 적용하는 사례를 공유합니다.
AutoMate란 무엇인가요?
AutoMate는 광범위한 조립에 걸쳐 스페셜리스트(부품별) 및 제너럴리스트(통합) 조립 기술을 학습하기 위한 최초의 시뮬레이션 기반 프레임워크이며, 이러한 범위에서 제로샷 시뮬레이션에서 실제로의 전이를 보여 주는 최초의 시스템입니다. 이 연구는 서던 캘리포니아 대학교와 NVIDIA 시애틀 로보틱스 연구소의 긴밀한 협업으로 이루어졌습니다.
특히 AutoMate의 주요 공헌 사항은 다음과 같습니다.
- 100개의 조립으로 구성된 데이터 세트와 즉시 사용 가능한 시뮬레이션 환경.
- 시뮬레이션된 로봇을 효과적으로 트레이닝하여 시뮬레이션에서 광범위한 조립 작업을 해결하는 새로운 알고리즘 조합.
- 여러 전문화된 조립 기술의 지식을 하나의 일반 조립 기술로 정제하고 RL을 통한 일반 조립 기술의 성능을 더욱 개선하는 학습 접근 방식의 효과적인 합성.
- 인식으로 초기화된 워크플로우에서 시뮬레이션으로 트레이닝된 조립 기술을 배포할 수 있는 실제 시스템.


데이터 세트와 시뮬레이션 환경
AutoMate는 시뮬레이션과 호환되고 실제 세계에서 3D 프린팅 가능한 100개의 조립 데이터 세트와 100개의 조립 모두에 대한 병렬화된 시뮬레이션 환경을 제공합니다. 100개의 조립은 Autodesk의 대규모 조립 데이터 세트를 기반으로 합니다. 이 작업에서 플러그라는 용어는 삽입해야 하는 부품을 나타내며(그림 3, 흰색으로 표시), 소켓은 플러그와 결합되는 부품을 나타냅니다(그림 3, 녹색으로 표시).


다양한 형태에 대한 전문가 학습
NVIDIA의 이전 작업인 IndustReal은 RL만 사용한 접근 방식이 접촉이 많은 조립 작업을 해결할 수 있음을 보여 주었지만, 이는 일부의 조립만 해결할 수 있었습니다. RL만 사용한 접근 방식은 AutoMate 데이터 세트의 100개 조립 대부분을 해결할 수 없습니다. 그러나 모방 학습을 통해 로봇은 데모를 관찰하고 모방하여 복잡한 기술을 습득할 수 있습니다. AutoMate는 RL과 모방 학습을 결합하는 세 가지 고유한 알고리즘의 새로운 조합을 도입하여 광범위한 조립에 대한 효과적인 기술 습득을 지원합니다.
모방 학습으로 RL을 강화하는 데는 세 가지 과제가를 해결해야 합니다.
- 조립 데모 생성
- 모방 학습 목표를 RL에 통합
- 학습 중에 사용할 데모 선택
다음 섹션에서는 이러한 각 과제를 해결하는 방법을 살펴봅니다.
조립 및 분해를 통한 데모 생성
조립의 기구학(Kinematics of assembly)은 로봇이 장애물과 충돌하지 않고 제한되거나 협소한 공간을 통과할 수 있도록 부품을 조작해야 하는 좁은 통로 문제(narrow-passage problem)입니다. 모션 플래너를 사용하여 조립 데모를 자동으로 수집하는 것은 매우 어렵습니다. 사람이 데모를 수집하려면 고도로 숙련된 인간 조작자와 고급 원격 작동 인터페이스가 필요하며 이는 비용이 많이 들 수 있습니다.
물체를 분해하는 방법을 먼저 이해하여 물체를 조립하는 과정인 조립별 분해 개념에서 착안된 분해 데모를 수집한 다음, 조립을 역순으로 수행합니다. 시뮬레이션에서 로봇은 소켓에서 플러그를 분해하고 각 조립에 대해 100번의 성공적인 분해 데모를 기록하라는 명령을 받습니다.

모방 목표가 있는 RL
RL에서 보상은 주어진 단계에서 얼마나 잘 수행되고 있는지를 나타내는 에이전트에게 주어지는 신호입니다. 보상은 피드백 역할을 하며, 시간이 지남에 따라 누적 보상이 극대화되도록 에이전트가 자신의 행동을 학습하고 조정하도록 안내합니다(작업 성공으로 이어짐). DeepMimic과 같은 캐릭터 애니메이션 작업에서 영감을 받은 모방 용어는 보상 함수에 통합되어 모방 목표로 RL을 강화하여 로봇이 학습 프로세스 중에 데모를 모방하도록 독려합니다. 시간 단계당 모방 보상은 주어진 조립에 대한 모든 데모에 대한 최대 보상으로 정의됩니다.
모방 용어 외에도 보상 공식에는 다음과 같은 용어도 포함됩니다.
- 골까지의 거리에 페널티 부여
- 시뮬레이션 오류에 페널티 부여
- 작업 난이도 보상
이는 이전 IndustReal 작업과 일치합니다.
동적 시간 워핑이 있는 데모 선택
모방할 데모(즉, 어떤 데모가 현재 시간 단계에서 최대 보상을 제공하는지)를 결정하기 위한 첫 번째 단계는 각 데모와 현재 로봇 엔드 이펙터 경로 사이의 거리를 계산한 다음, 최소 거리로 경로를 모방하는 것입니다. 데모 경로는 로봇 엔드 이펙터 경로에 비해 웨이포인트의 고르지 않은 분포와 다른 수의 웨이포인트를 가질 수 있으므로 데모 경로의 웨이포인트와 로봇 엔드 이펙터 경로 간의 일치성을 판단하기가 어렵습니다.
동적 시간 워핑(DTW)은 속도가 다를 수 있는 두 시간 시퀀스 간의 유사성을 측정하는 데 사용되는 알고리즘입니다. 이 작업에서 DTW는 엔드 이펙터 경로의 각 웨이포인트와 데모 경로의 일치하는 웨이포인트 간의 거리 합계를 최소화하는 로봇 엔드 이펙터 경로와 각 데모 경로 간의 매핑을 찾는 데 사용됩니다(그림 6). DTW에서 반환된 거리가 주어지면 모방 보상이 각 데모 경로에 대해 계산되고 가장 높은 모방 보상을 제공하는 데모 경로를 선택합니다.

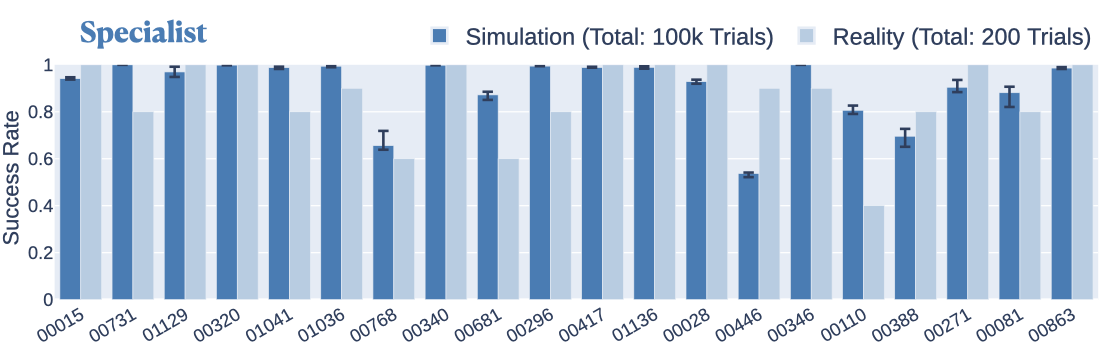
제안된 조립별 분해, 모방 목표가 있는 RL, DTW를 사용한 궤적 일치의 제안된 조합은 광범위한 조립에서 일관된 성능을 보여 줍니다. 시뮬레이션에서 전문가 정책은 80개의 개별 조립에서 ≈80%의 성공률을 달성하고 55개의 개별 조립에서 ≈90%의 성공률을 달성합니다. 실제 세계에서 전문가 정책은 20개의 조립에서 평균 86.5%의 성공률을 달성하며, 이는 시뮬레이션에서 이러한 조립에 배포한 것에 비해 단 4.2% 감소한 것입니다(그림 7).
일반 조립 기술 학습
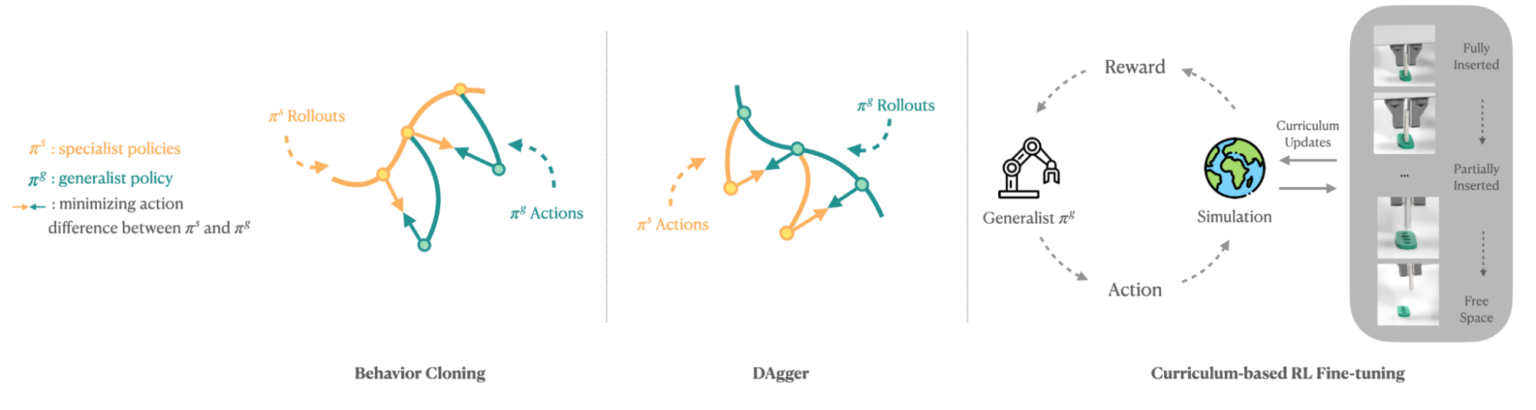
여러 조립 작업을 해결할 수 있는 제너럴리스트 기술을 훈련하는 것의 목표는 이미 트레이닝된 스페셜리스트 기술의 지식을 재사용한 다음, 커리큘럼 기반 RL을 사용하여 성능을 더욱 개선하는 것입니다. 제안된 방법에는 세 단계가 포함됩니다.
- 첫째, 표준 행동 복제(BC)가 적용되며, 여기에는 이미 트레이닝된 스페셜리스트 기술에서 데모를 수집하고 이러한 데모를 사용하여 제너럴리스트 기술의 훈련을 감독하는 작업이 포함됩니다.
- 둘째, DAgger(데이터 세트 집계)는 제너럴리스트 기술을 실행하고 제너럴리스트가 감독을 제공하기 위해 방문하는 주에서 스페셜리스트 기술을 적극적으로 쿼리(즉, 전문가가 예측한 동작을 가져옴)하여 제너럴리스트를 개선하는 데 사용됩니다.
- 마지막으로 제너럴리스트의 RL 미세 조정 단계가 실행됩니다. 미세 조정 단계에서는 IndustReal 작업의 샘플링 기반 커리큘럼이 적용되며, 여기서 제너럴리스트가 더 높은 작업 성공률에 도달함에 따라 부품의 초기 참여가 점차 줄어듭니다.
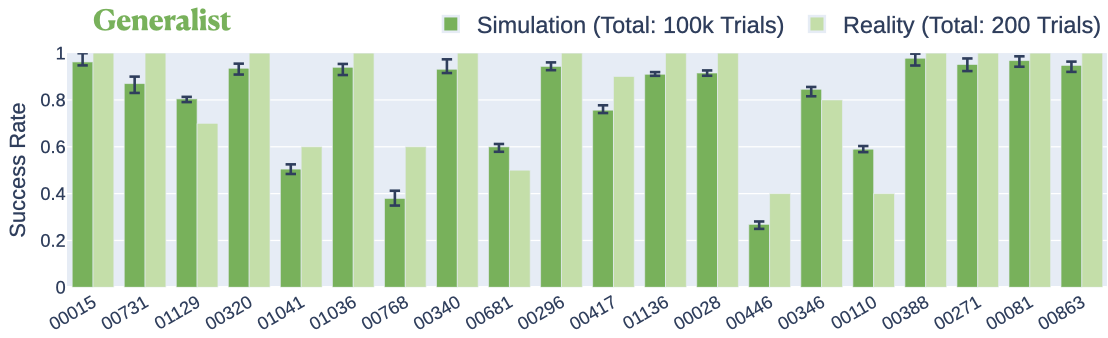
제너럴리스트는 20개의 조립에 대해 제안된 3단계 접근 방식을 사용하여 트레이닝됩니다. 시뮬레이션에서 제너럴리스트 정책은 80.4%의 성공률로 20개의 조립을 공동으로 해결할 수 있습니다. 실제 세계에서 제너럴리스트 정책은 동일한 조립 세트에서 평균 84.5%의 성공률을 달성하며, 이는 시뮬레이션 배포에 비해 4.1% 개선된 것입니다(그림 9).
실제 설정 및 인식 초기화 워크플로우
실제 설정에는 Franka Panda 로봇 팔, 손목 장착 Intel RealSense D435 카메라, 3D 프린팅된 플러그 앤 소켓, 소켓을 잡는 데 사용되는 Schunk EGK40 그리퍼가 포함됩니다. 인식 초기화 워크플로우에서 다음을 수행합니다.
- 플러그는 폼 블록에 무작위로 배치되고 소켓은 Schunk 그리퍼 내에 무작위로 배치됩니다.
- RGB-D 이미지가 손목 장착 카메라를 통해 캡처된 후 부품의 6D 포즈 추정(FoundationPose)이 수행됩니다.
- 로봇이 플러그를 잡고 소켓으로 옮기고 시뮬레이션 트레이닝된 조립 기술을 배포합니다.
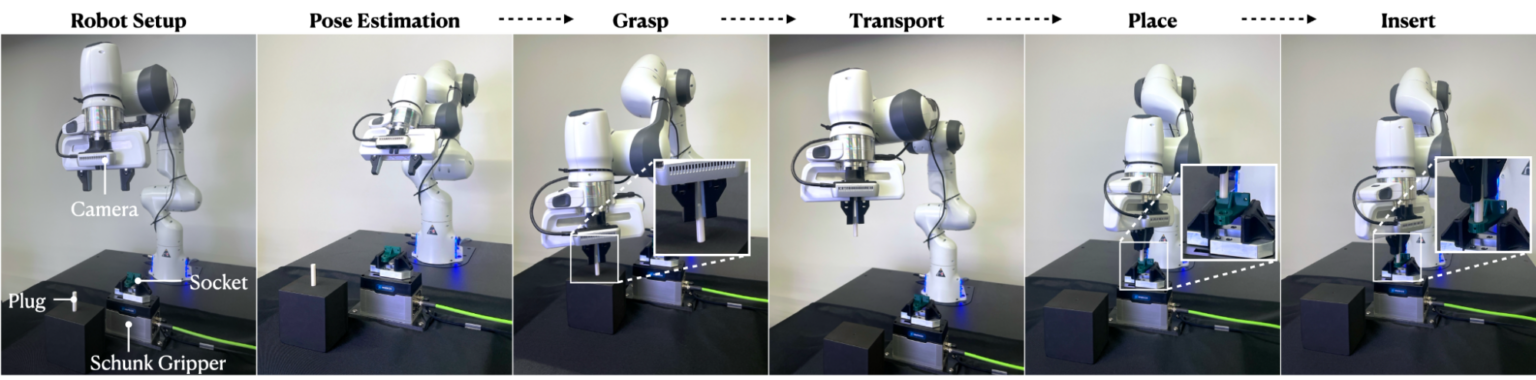
스페셜리스트와 제너럴리스트는 인식 초기화 워크플로우에서 평가됩니다. 스페셜리스트의 경우 평균 성공률은 90.0%입니다. 제너럴리스트 경우 성공률은 86.0%입니다. 이러한 결과는 6-DOF 포즈 추정, 잡기 최적화, 그리고 스페셜리스트 및 제너럴리스트 정책 학습을 위해 제안된 방법을 효과적으로 결합하여 연구 등급 하드웨어를 사용하는 현실적인 조건에서 신뢰할 수 있는 조립을 달성할 수 있음을 나타냅니다.
요약
AutoMate는 학습 방법과 시뮬레이션을 활용하여 광범위한 조립 문제를 해결하려는 첫 번째 시도입니다. 이 작업을 통해 NVIDIA의 연구원들은 실제 배포를 기반으로 산업용 로보틱스를 위한 대규모 모델 패러다임을 향해 점진적으로 구축해 왔습니다.
향후에는 효율적인 시퀀스 계획(즉, 다음에 어떤 부품을 조립할지 결정)이 필요한 멀티파트 조립을 해결하고 업계 경쟁력 있는 성능 사양을 충족하기 위해 기술을 더욱 개선할 예정입니다.
이전에 진행했던 NVIDIA 작업을 빠르게 살펴보려면 Factory 및 IndustReal에 대한 논문을 읽어보세요. AutoMate프로젝트 페이지를 방문하여 논문을 읽고 요약 영상을 시청하세요. 새로 출시된 NVIDIA Isaac Lab에 AutoMate가 곧 통합될 예정이니 계속 확인해 주세요.
2024년 7월에 열리는 로보틱스: 과학 및 시스템(RSS) 컨퍼런스에서 저자 Bingjie Tang, Iretiayo Akinola, Jie Xu, Bowen Wen, Ankur Handa, Karl Van Wyk, Dieter Fox, Gaurav S. Sukhatme, Fabio Ramos, Yashraj Narang과 함께 AutoMate: Specialist and Generalist Assembly Policies over Diverse Geometries라는 논문을 발표합니다.
관련 리소스
- DLI 과정: 산업용 검사를 위한 딥 러닝
- GTC 세션: 시뮬레이션에서 실제로, 다시 현실로 – 산업 자동화를 위한 디지털 트윈 프로그래밍
- GTC 세션: Isaac Gym을 통해 시뮬레이션에서 현실로: 로봇 손의 기초 및 실제 사례
- GTC 세션: 맞춤형 로봇 시뮬레이션: Isaac Sim과 ROS2를 사용한 핸즈온 랩
- NGC 컨테이너: MATLAB
- 웨비나: 로보틱스 인식 향상: Omniverse Replicator를 사용한 합성 데이터 생성