
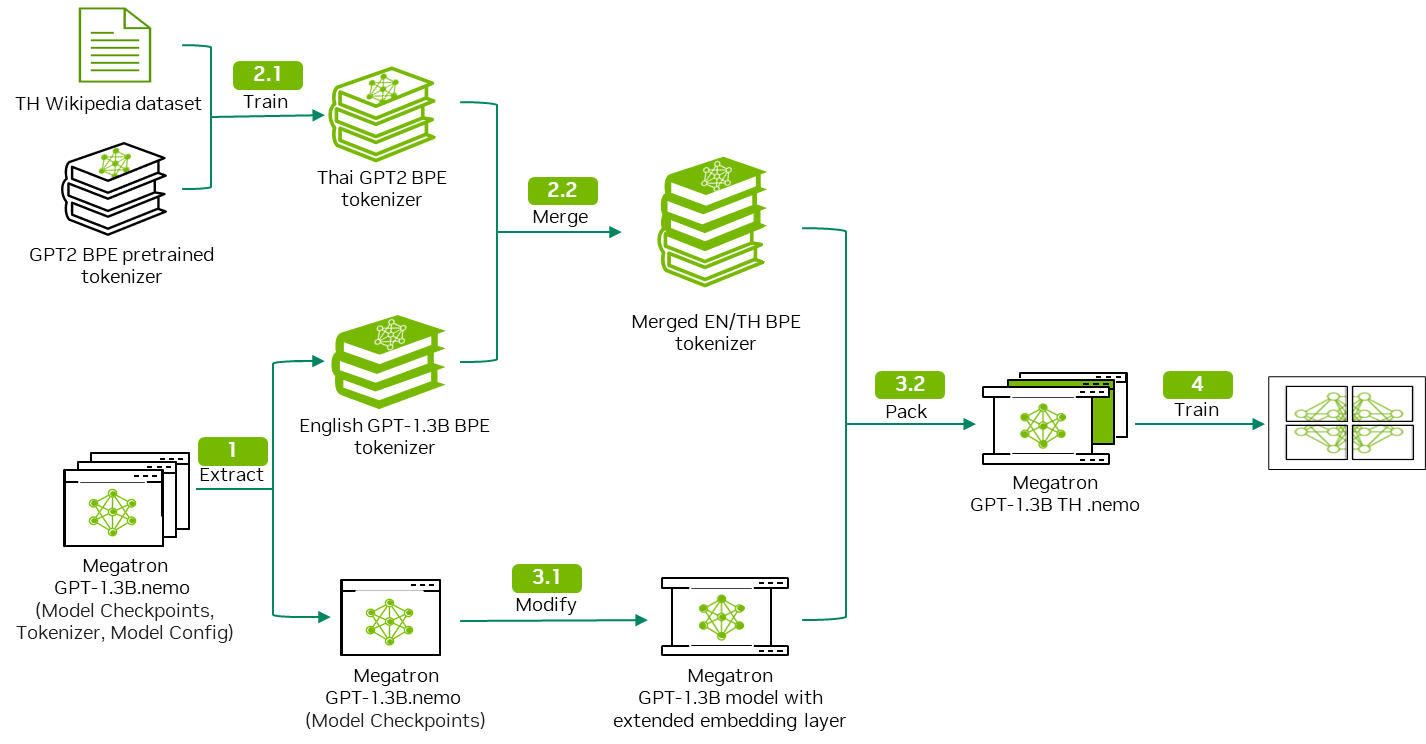
1부에서는 단일 언어 토크나이저를 트레이닝하고 이를 사전 트레이닝된 LLM의 토크나이저와 병합하여 다국어 토크나이저를 형성하는 방법을 논의했습니다. 이 게시물에서는 맞춤형 토크나이저를 사전 트레이닝된 LLM에 통합하는 방법과 NVIDIA NeMo에서 연속 사전 트레이닝 작업을 시작하는 방법을 보여 줍니다.
준비
시작하기 전에 다음 라이브러리를 가져오세요.
import torch
from nemo.collections.nlp.models.language_modeling.megatron_gpt_model import MegatronGPTModel
from nemo.collections.nlp.parts.megatron_trainer_builder import MegatronTrainerBuilder
from omegaconf import OmegaConf모델 수정
병합 후 결합된 토크나이저의 어휘 크기는 GPT-megatron-1.3B 모델 사전 트레이닝된 토크나이저의 어휘 크기보다 큽니다. 즉, 결합된 토크나이저를 수용하려면 GPT-megatron-1.3B 모델의 임베딩 레이어를 확장해야 합니다(그림 2).

주요 단계에는 다음이 포함됩니다.
- 원하는 어휘 크기로 늘린 새 임베딩 레이어를 만듭니다.
- 기존 임베딩 레이어에서 가중치를 복사하여 이를 초기화합니다.
- 새로운 어휘 항목의 가중치를 0으로 설정합니다.
그러면 이 확장된 임베딩 레이어는 사전 트레이닝된 모델의 기존 레이어를 대체하여 초기 사전 트레이닝 프로세스 중에 트레이닝한 지식을 유지하면서 새로운 언어의 추가 토큰을 처리할 수 있습니다.
임베딩 레이어 로드 및 추출
다음 코드를 실행하여 GPT-megatron-1.3B.nemo 모델을 로드합니다.
#Initialization
trainer_config = OmegaConf.load('/opt/NeMo/examples/nlp/language_modeling/conf/megatron_gpt_config.yaml')
trainer_config.trainer.accelerator='gpu' if torch.cuda.is_available() else 'cpu'
trainer = MegatronTrainerBuilder(trainer_config).create_trainer()
#load gpt-megatron-1.3b.nemo and its config
nemo_model = MegatronGPTModel.restore_from('./path_to_1.3B_nemo_model',trainer=trainer)
nemo_config = OmegaConf.load('./path_to_1.3B_nemo_model_config.yaml')모델을 로드한 후 모델 state_dict 매개 변수에서 임베딩 레이어의 가중치를 추출할 수 있습니다. 임베딩 레이어는 새 임베딩 레이어를 생성하는 데 사용됩니다.
#Extract original embedding layer
embed_weight = nemo_model.state_dict()[f'model.language_model.embedding.word_embeddings.weight']
print(f"Shape of original embedding layer: {embed_weight.shape}")새 임베딩 레이어 생성
이제 새 임베딩 레이어와 기존 임베딩 레이어 간의 차원 차이를 계산해야 합니다. 이 차이를 기반으로 텐서를 생성하고 이를 기존 임베딩 레이어에 연결하여 새 임베딩 레이어를 형성합니다.
차이는 다음을 기준으로 계산됩니다.
- 결합된 토크나이저 어휘 크기
- 기존 임베딩 레이어 길이
model_config.yaml의 매개 변수,model.make_vocab_size_divisible_by
차이에 대한 방정식은 다음과 같습니다.

- 결합된 토크나이저 어휘 크기 =

- 기존 NeMo 임베딩 레이어 길이 =

- model.make_vocab_size_divisible_by =

메커니즘은 연산 효율성을 극대화하기 위해 임베딩 레이어를 8의 배수로 나눌 수 있는 숫자로 채우는 것입니다. 토크나이저 어휘 크기를 감안할 때 모델에는 패딩된 임베딩 레이어가 있어야 합니다.
처음부터 트레이닝하는 경우 이 프로세스는 자동이어야 하지만 이 경우에는 새 임베딩 레이어를 수동으로 채워야 합니다.
tokenizer = AutoTokenizer.from_pretrained('./path_to_new_merged_tokenizer')
if len(tokenizer)% nemo_config.make_vocab_size_divisible_by != 0:
tokenizer_diff = (int(len(tokenizer)/nemo_config.make_vocab_size_divisible_by)+1) * nemo_config.make_vocab_size_divisible_by - embed_weight.shape[0]
else:
tokenizer_diff = tokenizer.vocab_size - embed_weight.shape[0]이제 새 토큰의 초기 가중치로 추가 텐서를 생성할 수 있습니다. 그런 다음, 이 텐서는 이전에 추출된 기존 임베딩 레이어에 연결되어 새 임베딩 레이어를 형성합니다.
hidden_size = embed_weight.shape[1]
random_embed = torch.zeros((tokenizer_diff, hidden_size)).to('cuda')
new_embed_weight = torch.cat((embed_weight, random_embed), dim=0)새 모델 수정 및 출력
이 단계에서는 모델 구성의 토크나이저 관련 설정을 수정하여 새 어휘에 맞춥니다. 새 임베딩의 모양이 기존 임베딩 레이어와 다르다는 점을 기억하세요. 기존 모델에서 임베딩 레이어를 직접 교체하는 경우 레이어 크기 불일치 오류가 발생합니다.
업데이트된 토크나이저 구성으로 빈 모델 인스턴스를 로드하고 새 임베딩 레이어와 함께 사전 트레이닝된 모델의 state_dict 값을 할당합니다.
마지막으로, 이 수정된 모델을 .nemo 형식으로 저장하여 확장된 어휘에 대한 지속적인 사전 트레이닝을 준비합니다.
state_dict = nemo_model.state_dict()
state_dict[f'model.language_model.embedding.word_embeddings.weight'] = new_embed_weight
NEW_TOKENIZER_PATH = './path_to_new_merged_tokenizer'
nemo_config['tokenizer']['vocab_file'] = f"{NEW_TOKENIZER_PATH}/vocab.json"
nemo_config['tokenizer']['merge_file'] = f"{NEW_TOKENIZER_PATH}/merges.txt"
nemo_config['vocab_file'] = f"{NEW_TOKENIZER_PATH}/vocab.json"
nemo_config['merges_file'] = f"{NEW_TOKENIZER_PATH}/merges.txt"
new_nemo_model = MegatronGPTModel(nemo_config,trainer)
new_nemo_model.load_state_dict(state_dict)
new_nemo_model.save_to('./path_to_modified_nemo_model')다음 코드를 실행하여 새 모델이 영어 프롬프트에서 잘 수행되는지 검사합니다.
python /opt/NeMo/examples/nlp/language_modeling/megatron_gpt_eval.py \ gpt_model_file='./path_to_modified_nemo_model' \
prompts='ENTER YOUR PROMPT' \
inference.greedy=True \
inference.add_BOS=True \
trainer.devices=1 \
trainer.num_nodes=1 \
tensor_model_parallel_size=-1 \
pipeline_model_parallel_size=-1데이터 전처리
데이터 세트 트레이닝, 검증, 테스트에 대해 데이터 사전 처리 스크립트를 반복적으로 실행합니다. 자세한 내용은 3단계: 데이터를 트레이닝, 검증, 테스트로 분할을 참조하세요.
--json_key 값을 데이터 세트의 문서 텍스트가 포함된 키로 교체합니다.
python /opt/NeMo/scripts/nlp_language_modeling/preprocess_data_for_megatron.py \ --input='./path_to_train/val/test_dataset' \
--json-keys=text \
--tokenizer-library=megatron \
--vocab './path_to_merged_tokenizer_vocab_file'\
--dataset-impl mmap \
--tokenizer-type GPT2BPETokenizer \
--merge-file './path_to_merged_tokenizer_merge_file' \
--append-eod \
--output-prefix='./path_to_output_preprocessed_dataset'연속 사전 트레이닝
연속 사전 트레이닝을 위한 기본 구성 파일은 모델과 다른 모델 구성을 가질 수 있습니다. 다음 코드를 실행하여 이러한 구성을 덮어씁니다. 그에 따라 토크나이저 및 데이터 접두사 매개 변수도 업데이트합니다.
ori_conf = OmegaConf.load('./path_to_original_GPT-1.3B_model/model_config.yaml')
conf = OmegaConf.load('/opt/NeMo/examples/nlp/language_modeling/conf/megatron_gpt_config.yaml')
for key in ori_conf.keys():
conf['model'][key] = ori_conf[key]
# Set global_batch_size based on micro_batch_size
conf['model']["global_batch_size"] = conf['model']["micro_batch_size"] * conf.get('data_model_parallel_size',1) * conf.get('gradient_accumulation_steps',1)
# Reset data_prefix (dataset path)
conf['model']['data']['data_prefix'] = '???'
# Reset tokenizer config
NEW_TOKENIZER_PATH = "./path_to_new_merged_tokenizer"
conf['model']['tokenizer']['vocab_file'] = f"{NEW_TOKENIZER_PATH}/vocab.json"
conf['model']['tokenizer']['merge_file'] = f"{NEW_TOKENIZER_PATH}/merges.txt"
conf['model']['vocab_file'] = f"{NEW_TOKENIZER_PATH}/vocab.json"
conf['model']['merges_file'] = f"{NEW_TOKENIZER_PATH}/merges.txt"
OmegaConf.save(config=conf,f='/opt/NeMo/examples/nlp/language_modeling/conf/megatron_gpt_config.yaml')다음 코드를 실행하여 연속 사전 트레이닝을 시작합니다. 특정 하드웨어 및 설정에 따라 다음 매개 변수를 수정해야 합니다.
nproc_per_node: 노드당 GPU 수량.model.data.data_prefix:데이터 세트 트레이닝, 검증, 테스트의 경로. 형식은 코드 예시를 참조하세요.exp_manager.name: 출력 폴더 이름. 중간 체크포인트는./nemo_experiments/<exp_manager.name>폴더에 저장됩니다.trainer.devices: 노드당 GPU 수량.trainer.num_nodes: 노드 수.trainer.val_check_interval: 트레이닝 중 검증 검사를 수행하기 위한 빈도(단계별).trainer.max_steps: 트레이닝 단계의 최대 단계.model.tensor_model_parallel_size: 1.3B 모델의 경우 1로 유지합니다. 더 큰 모델에는 더 큰 크기를 사용하세요.model.pipeline_model_parallel_size: 1.3B 모델의 경우 1로 유지합니다. 더 큰 모델에는 더 큰 크기를 사용하세요.model.micro_batch_size: 그래픽 카드 vRAM에 따라 변경됩니다.model.global_batch_size:micro_batch_size값에 따라 다릅니다. 자세한 내용은 배치를 참조하세요.
DATA = '{train:[1.0,training_data_indexed/train_text_document], validation:[training_data_indexed/val_text_document], test:[training_data_indexed/test_text_document]}'
!torchrun --nproc_per_node=1 \ /opt/NeMo/examples/nlp/language_modeling/megatron_gpt_continue_training.py \
"model.data.data_prefix={DATA}"\
name=megatron_gpt_ \
exp_manager.name=megatron_gpt_1 \
restore_from_path='./path_to_modified_nemo_model' \
trainer.devices=1 \
trainer.num_nodes=1 \
trainer.precision=16 \
trainer.val_check_interval=300 \
trainer.max_steps=1200 \
model.megatron_amp_O2=False \
model.tensor_model_parallel_size=1 \
model.pipeline_model_parallel_size=1 \
model.micro_batch_size=1 \
model.global_batch_size=1 \
++model.use_flash_attention=False \
++model.seq_len_interpolation_factor=null모델 추론
트레이닝 중에는 중간 파일이 ./nemo_experiments 폴더에 생성, 저장됩니다. 이 폴더에서 원하는 모델 체크포인트 파일과 hparams.yaml을 찾아야 합니다
다음 코드를 사용하여 체크포인트 파일을 사용하여 추론합니다.
python /opt/NeMo/examples/nlp/language_modeling/megatron_gpt_eval.py \
'checkpoint_dir="./path_to_checkpoint_folder"' \
'checkpoint_name="name of checkpoint file in .ckpt format"' \
'hparams_file="./path_to_hparams_file"' \
prompts='ENTER YOUR PROMPT' \
inference.greedy=True \
inference.add_BOS=True \
trainer.devices=1 \
trainer.num_nodes=1 \
tensor_model_parallel_size=-1 \
pipeline_model_parallel_size=-1표 1은 기존 GPT-megatron-1.3B 모델과 태국어 위키백과 데이터를 사용하여 트레이닝된 GPT-megatron-1.3B 모델에서 생성된 문장 출력을 비교한 것입니다. 이 게시물에서는 일부 반복 출력 토큰이 잘립니다.
| Prompt | Output of GPT-megatron-1.3B.nemo | Output of Trained GPT-megatron-1.3B-TH.nemo |
| The capital city of Thailand is | The capital city of Thailand is from the capital city of Bangkok. The capital city of Thailand is from the capital city of Bangkok.\n\nHistory\n\nThe capital city of Thailand was originally called Chiang Mai, which means “city of the sun”. The capital city of Thailand was originally called Chiang Mai, which means “city of the sun”. | The capital city of Thailand is by the Thai Government of Thailand\n\nแหล่งข้อมูลอื่น \n\nเมืองในจังหวัดเชียงราย\nเมืองโบราณในประเทศไทย\n(The Capital city of Thailand is by the Thai Government of Thailand\n\nOther sources \n\nCities in Chiang Rai Province\nAncient cities in Thailand\n) |
| กรุงเทพมหานครเป็นสถานที่ท่องเที่ยวยอดนิยม สถานที่ท่องเที่ยวที่มีชื่อเสียงที่สุดคือ (Bangkok is a popular tourist destination. The most famous tourist attractions are ) | กรุงเทพมหานครเป็นสถานที่ท่องเที่ยวยอดนิยม สถานที่ท่องเที่ยวที่มีชื่อเสียงที่สุดคือการทำงานที่สุดท (Bangkok is a popular tourist destination. The most famous tourist attraction is the most famous working place.) | กรุงเทพมหานครเป็นสถานที่ท่องเที่ยวยอดนิยม สถานที่ท่องเที่ยวที่มีชื่อเสียงที่สุดคือ “วัดธรรมาธิปไตย” ซึ่งเป็นวัดที่พระบาทสมเด็จพระจุลจอมเกล้าเจ้าอยู่หัว (Bangkok is a popular tourist destination. The most famous tourist attractions are: “Wat Thammathipatai” which is the temple that King Chulalongkorn built.) |
트레이닝 후 모델은 태국어에 대한 이해도를 개선했지만 영어에 대한 성능은 저하되었습니다. 이는 단일 언어 데이터 세트를 사용한 연속 사전 트레이닝으로 인한 모델 망각 때문입니다. 이를 방지하려면 영어와 대상 언어를 모두 포함하는 말뭉치로 트레이닝하는 것이 좋습니다.
결론
이 워크플로우를 따르면 파운데이션 LLM의 언어 지원을 효과적으로 확장하여 LLM이 여러 언어로 된 콘텐츠를 이해하고 생성하도록 할 수 있습니다. 이 접근 방식은 초기 사전 트레이닝 중에 트레이닝된 기존 지식과 표현을 사용하는 동시에 모델이 연속 트레이닝을 통해 새로운 언어 기술에 적응하고 이를 습득하도록 지원합니다.
이 프로세스의 성공 여부는 토크나이저 트레이닝 및 연속 사전 트레이닝에 사용되는 대상 언어 데이터의 질과 양에 달려 있습니다. 최적의 성과를 보장하고 특히 치명적인 망각을 완화하기 위해서는 신중한 트레이닝 커리큘럼과 트레이닝 전략도 필요합니다.
시작하려면 NeMo 프레임워크 컨테이너를 다운로드하거나 GitHub에서 /NVIDIA/NeMo 오픈 소스 라이브러리를 다운로드 및 설정하세요. 리소스가 적은 언어에서 자체적으로 큐레이팅한 데이터 세트를 사용하고 이 게시물의 단계에 따라 파운데이션 LLM에 원하는 새 언어 지원을 추가할 수 있습니다.
NeMo 마이크로 서비스 얼리 액세스 프로그램의 일환으로 NVIDIA NeMo 큐레이터 및 NVIDIA NeMo 커스터마이저 마이크로 서비스에 대한 액세스를 요청할 수도 있습니다. 이러한 마이크로 서비스는 LLM의 데이터 큐레이션 및 맞춤화를 간소화하고 솔루션을 더 빠르게 출시할 수 있도록 지원합니다.
관련 리소스
- GTC 세션: NVIDIA NeMo 및 AWS를 통한 LLM 트레이닝 최적화
- GTC 세션: NVIDIA NeMo를 통해 다양한 언어로 파운데이션 거대 언어 모델 맞춤화
- GTC 세션: NeMo, TensorRT-LLM, Triton 추론 서버의 가속화된 LLM 모델 정렬 및 배포
- SDK: NeMo 추론 마이크로 서비스
- SDK: NeMo LLM 서비스
- 웨비나: 양적 재무를 위한 생성형 AI