
오픈 소스 데이터 세트는 고품질 데이터에 대한 액세스를 크게 대중화하여 개발자와 연구자들이 최첨단 생성형 AI 모델을 훈련할 수 있는 진입 장벽을 낮췄습니다. 오픈소스 데이터 세트는 다양하고 고품질의 잘 선별된 데이터 세트에 대한 무료 액세스를 제공함으로써 오픈소스 커뮤니티가 최첨단에 가까운 모델을 훈련할 수 있도록 지원하여 AI의 빠른 발전을 촉진합니다.
Zyphra는 최첨단 아키텍처를 통해 성능의 한계를 탐구하고 강력한 모델에 대한 연구와 이해를 발전시키며 AI 시스템에 더 쉽게 접근할 수 있도록 합니다.
이러한 비전을 달성하기 위해 Zyphra 팀은 NVIDIA NeMo Curator 팀과 긴밀히 협력하여 Zyda-1의 5배 크기인 5T 토큰으로 구성된 개방형 고품질 사전 훈련 데이터 세트인 Zyda-2를 만들었습니다. 이 데이터 세트는 광범위한 주제와 도메인을 포괄하며 높은 수준의 다양성과 품질을 보장하며, 이는 Zamba와 같은 강력하고 경쟁력 있는 모델을 훈련하는 데 매우 중요합니다.
Zyda-2로 정확도 높은 LLM 훈련하기
Zyda-2는 추가적인 전문 데이터 세트가 필요한 코드나 수학이 아닌 언어 능력에 특히 중점을 둔 일반적인 고품질 언어 모델 사전 훈련에 이상적입니다. 이는 Zyda-2가 기존 상위 데이터 세트의 강점은 그대로 유지하면서 약점을 개선했기 때문입니다.
그림 1은 종합 평가 점수에서 Zyda-2가 기존의 최신 오픈 소스 언어 모델링 데이터 세트보다 우수한 성능을 보인다는 것을 보여줍니다. Zyphra 팀은 Zamba2-2.7B 파라미터 모델을 사용하여 이 어닐링 연구를 수행했으며, 총 점수는 MMLU, Hellaswag, Piqa, Winogrande, Arc-Easy 및 Arc-Challenge의 평균입니다.
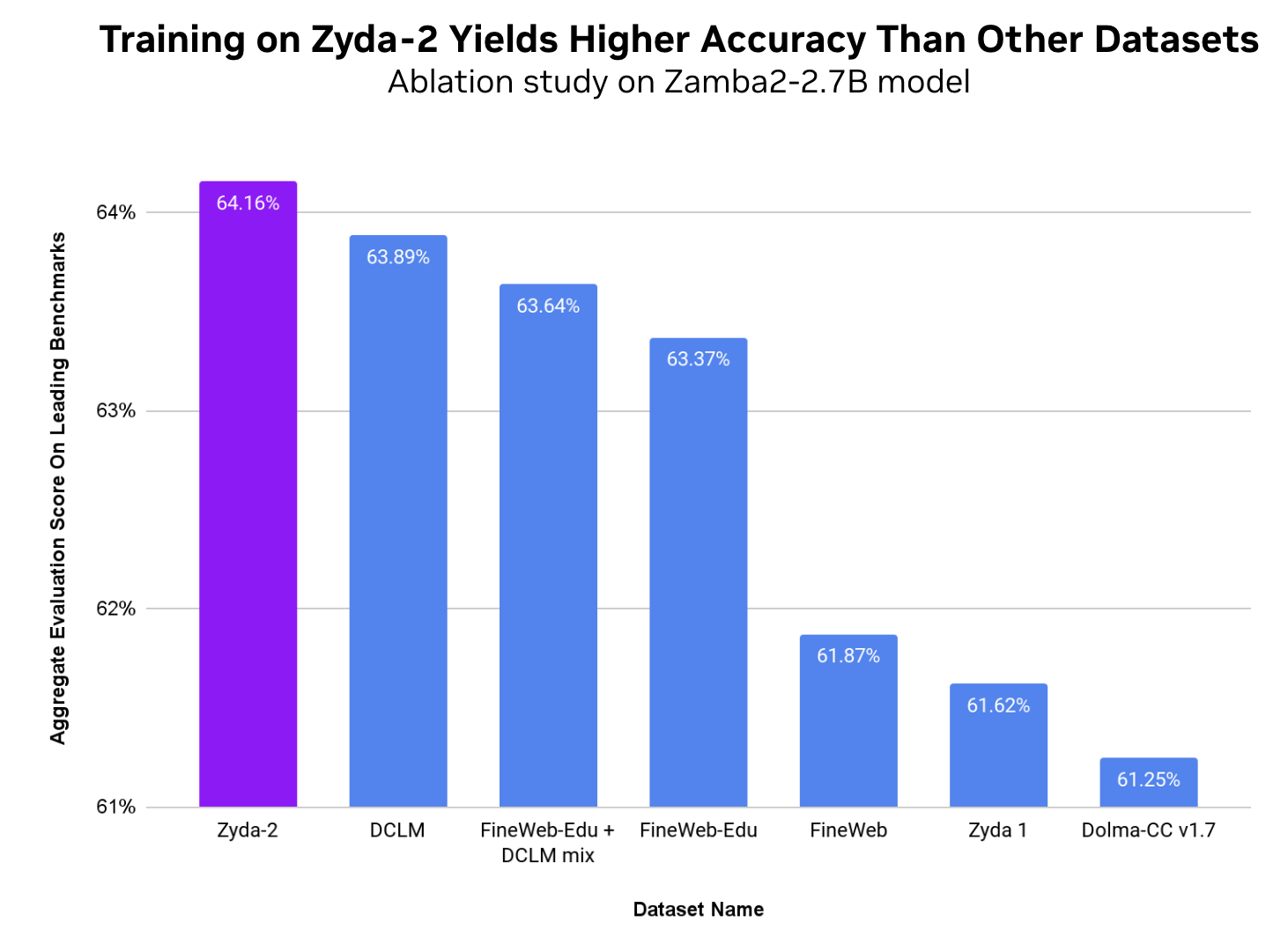
Zyphra의 학습 방법론은 온디바이스와 클라우드 배포 모두에서 주어진 메모리와 지연 시간 예산에서 모델 품질과 효율성을 극대화하는 데 초점을 맞추고 있습니다. Zyphra 팀은 또한 Zyda-2 데이터 세트의 초기 버전에서 7B 파라미터 하이브리드 모델인 Zamba2-7B를 훈련시켜 리더보드에서 다른 프론티어 모델보다 뛰어난 성능을 보이며 이 데이터 세트의 규모에 따른 강점을 입증한 바 있습니다.
모든 GPU 가속 시스템 또는 업계 표준 API를 통해 쉽게 배포할 수 있도록 NVIDIA NIM 마이크로서비스로 패키징된 Zamba2-7B에 액세스하세요.
Zyda-2의 구성 요소
Zyda-2는 DCLM, FineWeb-edu, Dolma, Zyda-1과 같은 기존의 개방형 고품질 토큰 소스를 결합합니다. 강력한 필터링과 교차 중복 제거를 수행하여 각 데이터 세트의 성능을 단독으로 향상시킵니다. Zyda-2는 이러한 데이터 세트의 가장 우수한 요소와 논리적 추론 및 사실적 지식을 위한 많은 고품질 교육 샘플을 결합한 반면, 다른 Zyda-1 구성 요소는 더 다양하고 풍부하며 언어 및 작문 작업에 더 뛰어납니다.
요컨대, 각 구성 요소 데이터 세트에는 고유한 장단점이 있지만, Zyda-2 데이터 세트를 결합하면 이러한 차이를 메울 수 있습니다. 중복 제거와 적극적인 필터링을 통해 주어진 모델 품질을 얻기 위한 총 학습 예산은 이러한 데이터 세트의 순진한 조합에 비해 줄어듭니다.
다음은 Zyphra가 데이터 처리 파이프라인을 구축하고 데이터 품질을 개선하기 위해 NVIDIA NeMo Curator를 사용한 방법입니다.
데이터 세트 생성에서 NeMo Curator의 역할
NeMo Curator는 사전 훈련 및 커스터마이징을 위해 대규모의 고품질 데이터 세트를 처리하여 생성형 AI 모델 성능을 개선하는 GPU 가속 데이터 큐레이션 라이브러리입니다.
Zyphra의 데이터 세트 책임자인 유리 토파노프(Yury Tokpanov)는 “NeMo Curator는 데이터 세트의 시장 출시 속도를 높이는 데 결정적인 역할을 했습니다. GPU를 사용하여 데이터 처리 파이프라인을 가속화함으로써 우리 팀은 총소유비용(TCO)을 2배 절감하고 데이터 처리 속도를 10배(3주에서 2일로 단축) 높일 수 있었습니다. 데이터의 품질이 향상되었기 때문에 훈련을 중단하고 NeMo Curator로 처리하고 처리된 데이터 세트에서 모델을 훈련할 수 있었기 때문에 그만한 가치가 있었습니다.”
GPU에서 워크플로우를 가속화하기 위해 NeMo Curator는 cuDF, cuML, cuGraph와 같은 RAPIDS 라이브러리를 사용하며 100TB 이상의 데이터로 확장할 수 있습니다. 고품질 데이터는 생성형 AI 모델의 정확도를 향상시키는 데 매우 중요합니다. 데이터 품질을 지속적으로 향상시키기 위해 NeMo Curator는 정확도, 퍼지, 시맨틱 중복 제거, 분류기 모델, 합성 데이터 생성 등 여러 가지 기술을 지원합니다.
Zyphra는 NeMo Curator를 통해 데이터 전처리, 정리 및 구성 프로세스를 간소화하여 궁극적으로 고급 언어 모델을 개발하는 데 적합한 데이터 세트를 확보할 수 있었습니다.
중복 제거 및 품질 분류를 비롯한 NeMo Curator의 기능은 Zyda-2의 원시 구성 요소 데이터 세트를 훈련에 사용할 수 있는 최고 품질의 하위 집합으로 추출하는 데 필수적이었습니다. NeMo Curator에 포함된 LSH 민해싱(minhashing) 기반의 퍼지 중복 제거 기술은 Zyphra의 팀이 DCLM 데이터 세트에서 다른 데이터 세트에서 중복으로 발견된 데이터의 13%를 찾아 제거하는 데 도움이 되었습니다.
품질 분류기 모델은 Dolma-CC 및 Zyda-1 구성 요소 데이터 하위 집합을 평가하는 데도 사용되어 각각 25%와 17%를 고품질로 표시했습니다. Zyda의 팀은 최종 데이터 세트에 고품질 하위 집합만 포함하면 성능이 향상된다는 사실을 발견했습니다.
그림 2는 원본 데이터 세트의 고품질 하위 집합으로 학습했을 때 정확도가 개선된 것을 보여줍니다. 이 차트는 전체 Zyda 및 Dolma 데이터 세트의 500억 개 토큰에 대한 학습과 NeMo Curator의 품질 분류기에서 ‘높음’ 등급을 받은 문서만 학습한 경우를 비교한 것입니다.
시작하기
Hugging Face에서 직접 Zyda-2 데이터 세트를 다운로드하여 더 높은 정확도의 모델을 훈련하세요. 원본 데이터 소스의 라이선스 계약 및 사용 약관에 따라 Zyda-2를 기반으로 훈련하거나 구축할 수 있는 ODC-By 라이선스가 함께 제공됩니다.
자세한 내용은 /NVIDIA/NeMo-Curator GitHub 리포지토리의 Zyda-2 튜토리얼을 참조하세요. 또한 NVIDIA API 카탈로그에서 직접 무료로 Zamba2-7B NIM 마이크로서비스를 사용해 볼 수도 있습니다.
관련 리소스
- GTC 세션: NVIDIA NeMo 및 AWS를 사용한 LLM 교육 최적화
- GTC 세션: NeMo, TensorRT-LLM 및 Triton 추론 서버에서 가속화된 LLM 모델 정렬 및 배포
- GTC 세션: 효율적인 거대 언어 모델(LLM) 사용자 정의
- SDK: NeMo 추론 마이크로서비스
- SDK: NeMo LLM 서비스
- SDK: NeMo Megatron