
2019년에 처음 소개된 NVIDIA Megatron-LM은 AI 커뮤니티에 혁신의 물결을 일으켰으며, 연구원과 개발자는 이 오픈 소스 라이브러리를 토대로 거대 언어 모델(LLM)을 더욱 발전시켰습니다. 오늘날 가장 인기 있는 LLM 개발자 프레임워크 대부분은 Megatron-LM 라이브러리에 기반하며 Megatron-LM 라이브러리를 사용해 구축되었고, 파운데이션 모델과 AI 스타트업은 이러한 프레임워크를 활용해 성장하고 있습니다. Megatron-LM을 기반으로 구축된 주요 LLM 프레임워크로는 Colossal-AI, Hugging Face Accelerate, NVIDIA NeMo 등이 있습니다.
마이그레이션을 간편하게 수행하고 연구원과 모델 개발자가 최신 분산 훈련 연구에 액세스할 수 있도록 하기 위해 NVIDIA는 최근 Megatron-LM을 개선했습니다. 이러한 노력을 거쳐 탄생한 NVIDIA Megatron-Core는 GPU 최적화 기술, 시스템 수준의 최첨단 혁신, 대규모 모델 훈련을 위한 모듈형 API를 갖춘 PyTorch 기반 오픈 소스 라이브러리입니다.
Megatron-Core는 지금도 대규모 분산 훈련을 발전시키는 원동력이 되고 있습니다. 이 게시물에서는 멀티모달 훈련을 위한 새로운 LLaVA(Large Language and Vision Assistant) 파이프라인을 포함해 최근 성과를 몇 가지 소개합니다.
NVIDIA Megatron-Core
Megatron-Core에는 시스템 수준의 최첨단 혁신이 반영된 GPU 최적화 기술이 집약되어 있습니다. Megatron-Core는 이러한 기술을 구성 가능한 모듈형 API로 추상화하여 프레임워크 개발자와 연구원이 NVIDIA 가속 컴퓨팅 인프라에서 규모별로 맞춤형 트랜스포머를 훈련할 수 있는 완전한 유연성을 제공합니다.
Megatron-Core 라이브러리는 어텐션 메커니즘, 트랜스포머 블록 및 레이어, 정규화 레이어, 임베딩 기술과 같은 트랜스포머 모델의 핵심 구성 요소를 제공합니다. 활성화 재연산 및 분산 체크포인팅을 포함한 추가 기능도 이 라이브러리에 기본적으로 내장되어 있습니다.
Megatron-Core를 사용하면 대규모 컴퓨팅 규모의 GPT, Bert, T5, RETRO 등 인기 있는 LLM 아키텍처를 효율적으로 구축할 수 있습니다. 또한 Megatron-Core는 모든 NVIDIA Tensor 코어 GPU와 호환되며 NVIDIA Hopper 아키텍처가 지원하는 FP8 데이터 형식을 활용하여 컴퓨팅 처리량을 향상하고 메모리 설치 공간을 절약할 수 있습니다. Megatron-Core 덕분에 Reka AI 및 Codeium과 같은 고객들은 모델을 대규모로 트레이닝할 수 있게 되었습니다.
Reka AI의 기술 직원인 Deyu Fu는 “Megatron-Core의 구성 가능한 모듈형 디자인은 당사의 멀티모달 LLM 아키텍처에 원활하게 통합됩니다. 최적화된 GPU 커널과 병렬 처리 기술을 통해 대규모 모델과 광범위한 컨텍스트를 쉽게 처리하는 한편 고밀도 훈련 및 희소 훈련이 클러스터 수준에서 효율적으로 확장되도록 지원합니다.”고 소개했습니다.
Codeium의 머신 러닝 엔지니어 Devin Chotzen-Hartzell는 “Megatron-Core를 활용하면 라이브러리에서 플래그를 지정하는 것만으로 LLM 훈련 기술 분야에서 우위를 차지할 수 있습니다. 덕분에 데이터 및 정렬 부문의 차별화 요소에 집중할 수 있게 되었습니다.”고 말했습니다.
Megatron-Core, 멀티모달 훈련 지원
시각적 명령 조정이 도입되면서 대규모 멀티모달 모델에 연구원과 업계 모두의 관심이 집중되었습니다. 이러한 모델들은 여러 센서 입력을 사용하여 환경을 이해하고 상호작용하며, 다양한 유형의 데이터를 활용하여 포괄적이고 컨텍스트에 맞는 응답을 생성합니다. 이러한 발전으로 생성형 AI 모델이 세상을 이해하는 방식이 사람과 더욱 유사해졌습니다.
이제 Megatron-Core v0.7에서는 멀티모달을 지원합니다. LLaVA를 활용하는 완전한 멀티모달 레퍼런스 파이프라인은 GitHub의 NVIDIA/Megatron-LM을 참조하세요. 모델 개발자는 Megatron에서 오픈 소스 멀티모달 데이터 로더를 사용하여 멀티모달 데이터세트를 결정성 및 재현성과 쉽게 혼합할 수 있습니다. 이는 체크포인트 저장 및 로드에서도 작동합니다.
LLaVA 파이프라인 예시는 다음을 수행하는 방법을 확인하실 수 있습니다.
- Megatron 웹 데이터세트 기반 형식을 위한 사전 훈련 및 지도 파인 튜닝(SFT) 데이터세트 준비
- Megatron Core 병렬 처리 및 메모리 절약 기술을 활용해 Misral 및 CLIP에서 초기화된 LLaVA 아키텍처 모델 훈련
- COCO 자막 및 VQAv2와 같은 다양한 작업으로 평가 수행
Megatron-Core v0.7 릴리스는 LLaVA 파이프라인의 기능적 측면에 중점을 두고 있으며, 대규모 다분야 멀티모달 이해(MMMU) 점수는 38점으로, 이는 7B 매개 변수 LLM 기반 LLaVA 아키텍처의 예상 범위에 속합니다.
또한 Megatron-Core(Mcore) 사양 시스템을 통해 연구원들은 PyTorch 모델 정의에서 하위 모듈을 쉽게 맞춤화할 수 있습니다. 향후 Megatron-Core 릴리스에서는 다양한 모델에 대해 이종 병렬 처리 전략을 지원할 예정입니다. 이 접근 방식은 더 작은 비전 모델에 특히 유용한데, 일반적으로 멀티모달 훈련의 거대 언어 모델에 비해 덜 복잡한 샤딩 기술을 요구하기 때문입니다.
멀티모달 데이터 로더를 포함한 모든 Megatron-Core 멀티모달 훈련 기능은 곧 NVIDIA NeMo에 통합되어 NeVa와 같은 모델을 위해 NeMo의 기존 멀티모달 기능을 향상할 예정입니다.
전문가 혼합 모델(MoE)을 위한 훈련 처리량 최적화
빠르게 진화하는 생성형 AI 환경에서 전문가 혼합(MoE) 모델은 부동 소수점 연산의 수를 늘리지 않고도 높은 정확도를 달성하도록 사전 훈련할 수 있어 선호되고 있습니다. MoE에서 고밀도 FFN 계층은 각 토큰이 라우터가 선택한 몇 명의 전문가에게 라우팅되는 MoE 계층으로 대체됩니다.
Megatron-Core v0.7은 MoE 기능을 확장하고 다양한 훈련 속도 및 메모리 최적화를 추가하여 대규모 MoE 훈련을 위한 가장 포괄적인 솔루션이 되었습니다. 무엇보다 Megatron-Core는 이제 GShard에서 사용되는 토큰 드롭을 통한 MoE 훈련을 지원하며, 멀티 CUDA 스트림 연산 및 그래디언트 누적 융합을 통해 향상된 GroupedGEMM과 같은 훈련 속도 최적화를 제공합니다.
표 1에는 Megatron-Core가 올-투-올 디스패처 및 4096의 시퀀스 길이와 BF16 정밀도로 훈련 시 GPU당 400TFLOP/s 이상의 처리량을 달성한 결과가 정리되어 있습니다. 각 토큰은 두 명의 전문가(–moe-router-topk)에게 라우팅됩니다. NVIDIA는 MoE용 FP8 레시피를 지속적으로 최적화하고 있으며 향후 Megatron-Core 릴리스에서 사용할 수 있도록 추가할 예정입니다.
또한 Megatron-Core는 MoE에 대한 전문가 병렬 처리를 지원하며 Megatron-Core에서 현재 지원하는 Tensor, 데이터, 시퀀스 및 파이프라인 병렬 처리와 같은 다른 병렬 처리 기술과 결합할 수 있습니다. 자세한 내용은 사용 설명서를 참조하세요.
| 모델 | 정밀도 | GPU 수 | MBS | GBS | TP | EP | PP | 그래디언트 누적 | GPU당 처리량(TFLOP/s/GPU) |
| Mistral 7B(고밀도 모델 기준) | BF16 | 128 | 4 | 256 | 2 | 해당 없음 | 1 | 1 | 492 |
| Mixtral 8x7B | BF16 | 128 | 1 | 256 | 1 | 8 | 4 | 8 | 402 |
훈련 복원력 향상을 위한 빠른 분산 체크포인팅
분산 체크포인팅은 대규모 훈련에서 복원력을 유지하는 데 매우 중요합니다. PyTorch 네이티브 솔루션인 torch.save는 효율성과 확장성이 부족한 경우가 잦아 더 효율적인 솔루션을 개발하는 계기가 되었습니다. 예를 들어 Azure Nebula 및 AWS Gemini는 비동기 체크포인팅을 지원하고 PyTorch 분산 체크포인트(DCP)는 스레드를 사용하여 차수당 체크포인트를 저장합니다. 이러한 방식은 병렬 처리와 비동기성을 활용하므로 기본 `torch.save`보다는 빠르지만 효율적인 비동기 체크포인팅을 달성하는 데는 여전히 한계가 있습니다.
특히 이러한 솔루션은 멀티 GPU 서버 내에서 병렬 처리 없이 또는 Python 스레드(Python Global Interpreter Lock으로 인해 효율성이 낮을 수 있음)를 사용하여 비동기 체크포인팅을 수행하므로 체크포인팅 시간을 늘리고 훈련 속도를 늦춥니다. 또한 이러한 솔루션은 사용자가 체크포인트를 저장하는 데 사용되는 것과 동일한 병렬 구성(예: PP 및 TP 크기)으로 체크포인트를 로드하도록 하여 긴 훈련을 실행하는 중에 동적 병렬 구성이 쉽게 재구성되는 것을 방지합니다.
Megatron-Core v0.7에서는 완전한 병렬 및 비동기 저장 기능을 도입하여 이러한 문제를 해결했습니다. 완전 병렬 저장(FPS)을 통해 데이터 병렬 복제본이 병렬 쓰기를 수행하여 사용 가능한 파일 시스템 대역폭을 더욱 효율적으로 활용할 수 있습니다. 비동기 병렬 저장은 주 훈련 프로세스에 대한 중단을 최소화하면서 체크포인트를 백그라운드의 안정적인 스토리지에 유지하기 전에 먼저 모델 매개 변수를 CPU(또는 향후 로컬 스토리지)에 복사하여 분산 체크포인팅 속도를 더욱 높입니다.
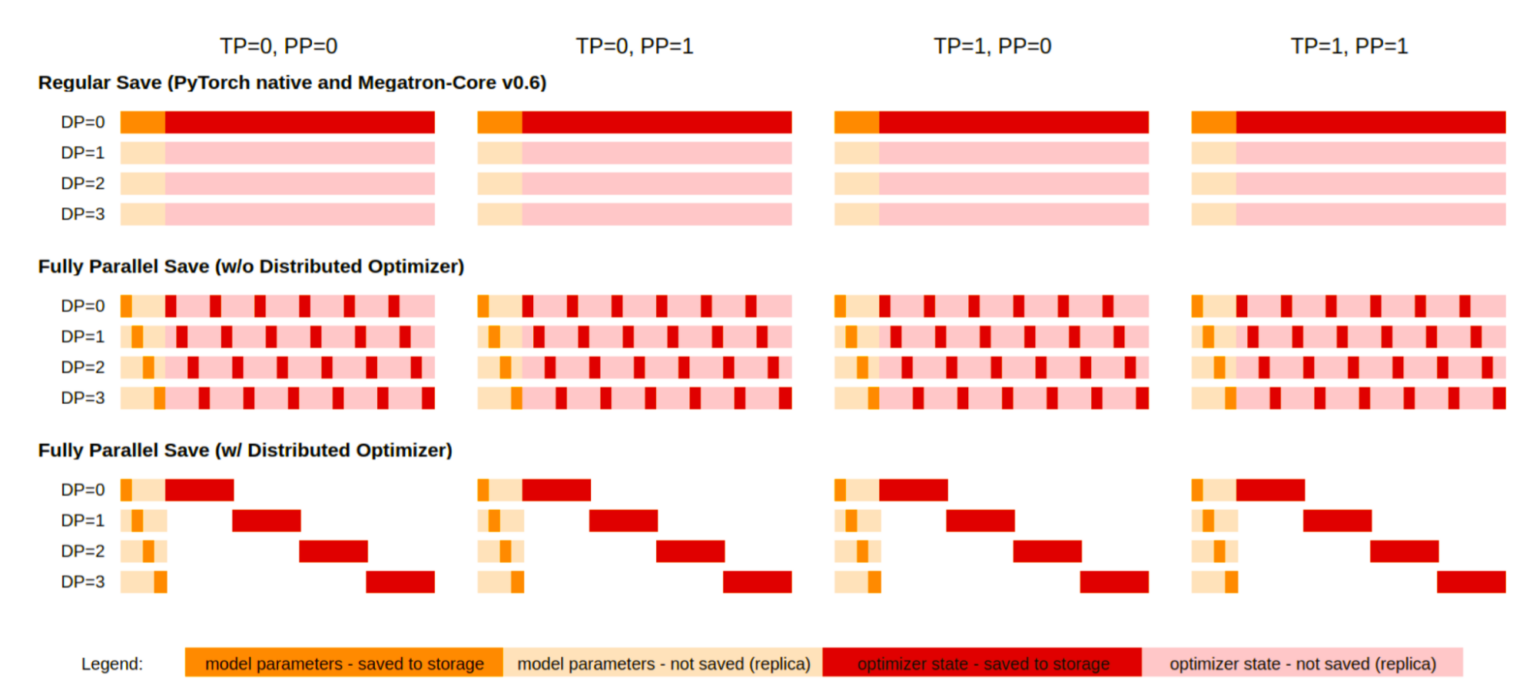
중요한 점은 Megatron-Core를 통해 사용자가 다양한 Tensor 및 파이프라인 병렬 처리도로 저장된 체크포인트에서 훈련을 다시 시작할 수 있으므로 훈련 중에 필요에 따라 유연하게 훈련 구성을 변경할 수 있다는 것입니다.
Megatron-Core의 저장 및 로드 API는 PyTorch 네이티브 API와 매우 유사하게 설계되어 Megatron-Core 분산 체크포인팅을 쉽게 도입할 수 있습니다. 이러한 개선 사항 덕분에 분산형 옵티마이저를 사용하지 않을 때 기본 PyTorch 솔루션에 비해 체크포인팅 오버헤드를 26배(Nemotron-4 340B의 경우) 또는 50배(Nemotron-4 15B의 경우) 줄일 수 있습니다. 분산형 옵티마이저를 사용하면 Nemotron-4 340B의 체크포인트 오버헤드를 42배 줄일 수 있습니다(그림 2).

향상된 확장성
Megatron-Core는 v0.5 릴리스부터 후방 전달을 통한 데이터 병렬 처리 그래디언트 all-reduce의 세분화된 중첩을 지원합니다. 매개 변수를 버킷으로 그룹화하고 버킷의 매개 변수에 대한 모든 그래디언트가 준비되면 버킷에 대한 비동기 통신 집합을 시작합니다. 이러한 기능은 노출된 데이터 병렬 통신의 양을 줄여 Megatron-Core 처리량을 개선하며, GPU당 배치 크기가 작고 그래디언트 누적이 적은 구성을 실행할 때 특히 유용합니다.
그림 3은 데이터 병렬 크기가 증가함에 따라 배치 크기도 증가하는 약한 스케일링 실험(글로벌 배치 크기는 3*data_parallel_size), 텐서 병렬 크기는 8인 Nemotron-4 15B 모델의 GPU당 처리량을 보여줍니다. 이러한 최적화 결과 데이터 병렬 크기가 32이고 배치 크기가 96일 때 처리량이 34% 개선되는 것을 확인할 수 있었습니다. --overlap-grad-reduce 플래그로 데이터 병렬 처리를 사용할 때 이 중첩 기술을 활성화할 수 있습니다. 자세한 내용은 Megatron-Core 문서를 참조하세요.

그림 3. NVIDIA H100 GPU 및 BF16 정밀도를 사용하는 Nemotron-4 15B에 대한 --overlap-grad-reduce 최적화의 효과
Megatron-Core v0.6 릴리스에서는 옵티마이저 상태가 여러 데이터 병렬 복제본에 분할되어 최대 메모리 설치 공간을 줄이는 분산형 옵티마이저 지원을 도입했습니다. 또한 분산형 옵티마이저는 이전에 필요했던 그래디언트 all-reduce를 그래디언트 RS(reduce-scatter) 및 매개 변수 AG(all-gather)로 분해합니다. Megatron-Core는 후방 전달 연산과 reduce-scatter를 중첩하고 전방 전달 연산과 all-gather를 중첩합니다. 이러한 최적화를 통해 선형에 가깝게 Nemotron-4 15B를 확장할 수 있습니다. 그림 4는 그림 3과 유사한 실험 설정에서 이러한 최적화를 활성화한 15B 모델의 GPU당 처리량을 보여줍니다.

또한 v0.7 릴리스는 버킷 크기 조정 방법에 대해 더 나은 내장 휴리스틱을 제공하여 대규모 데이터 병렬 크기에서 Megatron-Core의 속도를 더욱 개선합니다. 이를 통해 300(GPU 수 3,000 초과)을 초과하는 DP 크기에서도 지연 시간이 아닌 대역폭에 귀속적인 통신을 유지할 수 있습니다. 그림 5는 동일한 약한 확장 실험 설정과 모든 최적화가 활성화된 상태(reduce-scatter 및 all-gather 중첩을 모두 포함하는 분산형 옵티마이저)에서 데이터 병렬 크기가 최대 384일 때 15B 모델의 GPU당 처리량을 나타낸 것입니다.
그림 5. 최대 데이터 병렬 크기가 384인 NVIDIA H100 GPU를 사용하는 Nemotron-4 15B에서 Megatron-Core 0.6 및 0.7 릴리스 비교
Megatron-Core 최적화는 파이프라인 병렬 처리를 포함하여 다른 병렬 처리 차원이 필요한 더 큰 모델의 경우에도 바로 수행할 수 있습니다. Nemotron-4 340B 모델은 Megatron-Core에서 이러한 최적화를 사용하여 BF16을 사용하는 대규모 GPU에서 높은 훈련 처리량을 달성합니다. 표 2는 Nemotron-4 340B 기본 모델에서 다양한 배치 크기를 사용한 Megatron-Core의 GPU당 처리량을 보여줍니다. 이때 TP 크기는 8, PP 크기는 12, 가상 파이프라인 단계 수는 8, 시퀀스 길이는 4096입니다. 자세한 내용은 Nemotron-4 340B 기술 보고서를 참조하세요. 다른 병렬 처리 구성의 경우 처리량이 약간 더 높을 수 있습니다.
| 정밀도 | GPU 수(H100) | 데이터 병렬 크기 | 배치 크기 | GPU당 처리량(TFLOP/s/GPU) |
| BF16 | 1536 | 16 | 768 | 419.3 |
| BF16 | 3072 | 32 | 1536 | 418.3 |
| BF16 | 6144 | 64 | 2304 | 405.0 |
시작하기
Megatron-Core는 GitHub의 NVIDIA/Megatron-LM 리포지토리에서 오픈 소스로 사용할 수 있으며 Megatron-LM 또는 NVIDIA NeMo와 함께 사용할 수 있습니다. 경량 훈련 프레임워크인 Megatron-LM은 맞춤형 기본 PyTorch 훈련 루프를 제공하므로 더 적은 수의 추상화 계층을 선호하는 사용자에게 적합합니다. Megatron-LM은 Megatron-Core를 탐색하기 위한 시작점입니다. 자세한 내용은 Megatron-Core 문서를 참조하세요.
Megatron-Core는 보안, 안정성, 관리 기능 및 지원을 제공하는 엔터프라이즈급 AI 소프트웨어 플랫폼인 NVIDIA NeMo에 밀접하게 통합되어 있으며 LLM용 Megatron-Core 기능을 통합하고 멀티모달 및 음성 AI를 위한 더욱 광범위한 도구 세트를 제공합니다. 자세한 내용은 NVIDIA NeMo 프레임워크 문서를 참조하세요.
관련 리소스
- GTC 세션: Pai-Megatron-Patch
- SDK: NGC 모델
- SDK: NeMo LLM 서비스
- SDK: NeMo Megatron
- 웨비나: NVIDIA를 통한 생성형 AI 가속화
- 웨비나: 더 빠른 추론을 위해 AI 모델을 최적화하는 방법