
Meta의 Llama 거대 언어 모델 컬렉션은 오늘날 오픈 소스 커뮤니티에서 가장 인기 있는 파운데이션 모델로, 다양한 사용 사례를 지원합니다. 전 세계 수백만 명의 개발자가 파생 모델을 구축하고 이를 애플리케이션에 통합하고 있습니다.
Meta는 Llama 3.1을 통해 거대 언어 모델(LLM) 제품군과 안정적인 LLM 응답을 보장하기 위한 보안과 신뢰도 높은 모델 제품군을 출시합니다.
Meta 엔지니어들은 NVIDIA H100 텐서 코어 GPU에서 Llama 3를 훈련했습니다. 전체 트레이닝 스택을 크게 최적화하고 16K 이상의 H100 GPU로 모델 트레이닝을 추진하여 405B를 이 규모로 트레이닝된 최초의 Llama 모델을 구축하게 되었습니다.
데이터센터부터 엣지, PC에 이르기까지 모든 NVIDIA 플랫폼에 걸쳐 전 세계 1억 개 이상의 GPU에 최적화된 Llama 3.1 컬렉션을 발표하였습니다.
NVIDIA 가속 컴퓨팅 플랫폼에서 가속화되는 Llama 3.1
TensorRT-LLM을 실행하는 최신 NVIDIA H200 텐서 코어 GPU는 Llama 3.1-405B에서 뛰어난 추론 성능을 제공합니다. H200 GPU의 대용량 HBM3e 메모리 용량을 갖춘 이 모델은 H200 GPU 8개가 장착된 단일 HGX H200에 편안하게 장착할 수 있습니다. 4세대 NVLink와 3세대 NVSwitch는 서버의 모든 GPU 간에 PCIe Gen 5보다 7배 빠른 고대역폭 통신을 제공함으로써 Llama 3.1-405B와 같은 대형 모델을 실행할 때 추론 처리량을 가속화합니다.
표 1과 2는 8-GPU H200 시스템에서 실행되는 Llama 3.1-405B의 다양한 입력 및 출력 시퀀스 길이에 따른 최대 처리량 성능을 보여줍니다.
| 입력 | 출력 시퀀스 길이 | 2,048 | 128 | 32,768 | 2,048 | 120,000 | 2,048 |
| 출력 토큰/초 | 399.9 | 230.8 | 49.6 |
NVIDIA 내부 측정. 출력 토큰/초에는 첫 번째 토큰을 생성하는 시간이 포함되어 있습니다. tok/s = 총 생성된 토큰; / 총 지연 시간. 최대 노드 처리량을 위해 조정된 배치 크기, DGX H200, TP8, FP8, TensorRT-LLM 버전 0.12.0.dev2024072300.
최대 처리량 성능 외에도 동일한 입력 및 출력 시퀀스 길이를 사용하여 최소 지연 시간 성능도 보여드립니다:
| 입력 | 출력 시퀀스 길이 | 2,048 | 128 | 32,768 | 2,048 | 120,000 | 2,048 |
| 출력 토큰/초 | 37.4 | 33.1 | 22.8 |
NVIDIA 내부 측정. 출력 토큰/초에는 첫 번째 토큰을 생성하는 시간이 포함됩니다. tok/s = 총 생성된 토큰 수; / 총 지연 시간. DGX H200, TP8, FP8, 배치 크기 = 1, TensorRT-LLM 버전 0.12.0.dev2024072300.
이 결과에서 알 수 있듯이, H200 GPU와 TensorRT-LLM은 출시 당시 이미 지연 시간 최적화 및 처리량 최적화 시나리오 모두에서 Llama 3.1-405B에서 뛰어난 성능을 발휘하고 있습니다.
NVIDIA 소프트웨어를 사용하여 모든 단계에서 Llama 3.1로 구축하기
애플리케이션 내에서 Llama를 채택하려면 다음 기능이 필요합니다:
- 특정 도메인에 맞게 모델을 조정하는 기능
- 검색 증강형(RAG) 애플리케이션을 활성화하기 위한 모델 임베딩 지원
- 모델 정확도를 평가할 수 있는 기능
- 대화를 주제에 맞고 안전하게 유지하는 기능
- 최적화된 추론 솔루션
이번 릴리스를 통해 NVIDIA는 이러한 모든 작업을 NVIDIA 소프트웨어로 수행할 수 있도록 지원하여 도입을 더욱 용이하게 합니다.
첫째, 언어 모델을 훈련, 커스터마이징 및 평가하려면 고품질 데이터 세트가 필수적입니다. 그러나 일부 개발자는 적절한 라이선스 조건으로 고품질 데이터 세트에 액세스하는 데 어려움을 겪습니다.
NVIDIA는 맞춤형 고품질 데이터 세트를 생성하는 데 도움이 되는 Llama 3.1을 기반으로 하는 합성 데이터 생성(SDG) 파이프라인을 제공하여 이 문제를 해결하고 있습니다.
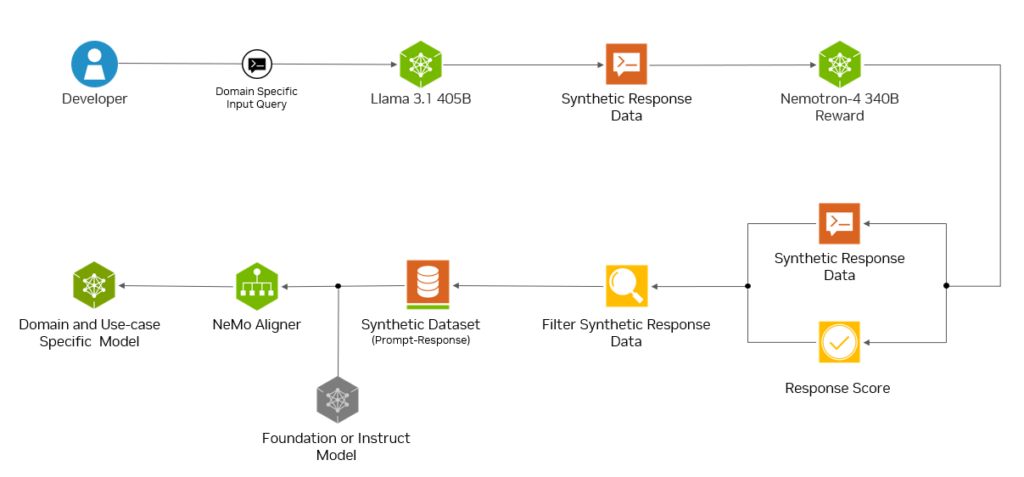
Llama 3.1-405B를 사용하면 SDG 파이프라인에서 제너레이터로 사용할 수 있는 최첨단 생성형 모델에 액세스할 수 있습니다. 데이터 생성 단계에 이어 Nemotron-4 340B 리워드 모델이 데이터의 품질을 평가하여 점수가 낮은 데이터를 걸러내고 사람의 선호도에 맞는 데이터 세트를 제공합니다. 이 리워드 모델은 전체 점수 92.0점으로 RewardBench 순위표에서 1위를 차지했습니다. 이 모델은 트릭 질문과 지침 응답의 뉘앙스를 처리하는 모델의 능력을 테스트하는 Chat-Hard 하위 집합에서 탁월한 성능을 보였습니다. 자세한 내용은 Llama 3.1 405B를 사용하여 합성 데이터 만들기를 참조하세요.
데이터 세트가 준비되면 NVIDIA NeMo 플랫폼을 사용하여 추가로 큐레이팅, 맞춤화 및 평가할 수 있습니다.
NVIDIA NeMo
Llama 3.1로 커스텀 모델과 애플리케이션을 구축하려면 NVIDIA NeMo를 사용할 수 있습니다. NeMo는 어디서나 맞춤형 생성형 AI를 개발할 수 있는 엔드투엔드 플랫폼을 제공합니다. 고급 병렬 처리 기술을 사용하여 여러 노드와 GPU에서 GPU 리소스와 메모리를 관리하여 NVIDIA GPU 성능을 극대화합니다.
이 오픈 소스 플랫폼을 다음 작업 중 일부 또는 전체에 사용할 수 있습니다:
- NeMo 큐레이터로 데이터를 큐레이션하여 고품질 데이터를 취합하고 데이터 세트를 정리, 중복 제거, 필터링 및 분류하여 맞춤형 모델의 성능을 개선합니다.
- p-튜닝, 낮은 순위 적응(LoRA) 및 그 정량화된 버전(QLoRA)과 같은 매개변수 효율적 파인 튜닝(PEFT) 기술을 사용하여 모델을 맞춤형으로 조정합니다. 이러한 기법은 많은 컴퓨팅 성능을 필요로 하지 않으면서도 맞춤형 모델을 만드는 데 유용합니다.
- 모델 응답을 조정하고 사람의 선호도에 맞게 Llama 3.1 모델을 조정하여 모델을 고객 대면 애플리케이션에 통합할 수 있도록 준비합니다. 현재 NeMo에서 지원하는 기능은 다음과 같습니다:
- 현재 얼리 액세스 버전으로 제공되는 NeMo Evaluator 마이크로서비스로 LLM 평가를 간소화하세요. 이 마이크로서비스는 학술적 벤치마크, 사용자 지정 데이터 세트에 대해 자동으로 평가하고 LLM-as-a-judge로 평가할 수 있습니다(기준값이 정의되지 않은 시나리오에서 유용함).
- 검색 증강 생성(RAG) 기능을 마이크로서비스 모음인 NeMo Retriever와 통합하세요. 이 마이크로 서비스는 높은 정확도와 최대의 데이터 프라이버시를 보장하는 최첨단 개방형 상용 데이터 검색 기능을 제공합니다.
- LLM 기반 대화형 애플리케이션에 프로그래밍 가능한 가드레일을 추가하여 신뢰성, 안전, 보안 및 제어된 대화를 보장하는 NeMo Guardrails로 환각을 완화할 수 있습니다. Meta의 최신 Llama Guard와 같은 다른 가드레일 및 안전 모델과 함께 확장할 수 있습니다. 또한 LangChain 및 LlamaIndex와 같은 인기 프레임워크를 포함한 개발자 도구에 원활하게 통합됩니다.
이러한 도구와 더 많은 기능을 NVIDIA AI Foundry를 통해 사용하세요.
어디에서나 활용 가능한 Llama
이제 Meta-Llama 3.1-8B 모델이 NVIDIA GeForce RTX PC 및 NVIDIA RTX 워크스테이션에서 추론에 최적화되었습니다.
Windows용 TensorRT Model Optimizer를 통해 Llama 3.1-8B 모델은 AWQ 훈련 후 양자화(PTQ) 방식으로 INT4로 정량화됩니다. 이 낮은 정밀도 덕분에 NVIDIA RTX GPU에서 사용 가능한 GPU 메모리에 맞출 수 있을 뿐만 아니라 메모리 대역폭 병목 현상을 줄여 성능을 개선할 수 있습니다. 이 모델들은 LLM 추론 성능을 가속화하는 오픈 소스 소프트웨어인 NVIDIA TensorRT-LLM에서 기본적으로 지원됩니다.
또한, Llama 3.1-8B 모델은 로봇 공학 및 엣지 컴퓨팅 디바이스를 위해 NVIDIA Jetson Orin에 최적화되어 있습니다.
Llama 3.1을 통한 성능 극대화
모든 Llama 3.1 모델은 128K 컨텍스트 길이를 지원하며 BF16 정밀도의 기본 및 인스트럭션 변형으로 제공됩니다.
또한 이 모델들은 이제 TensorRT-LLM으로 가속화됩니다. TensorRT-LLM은 추론 성능을 극대화하기 위해 패턴 매칭과 퓨전을 사용하여 모델 레이어에서 최적화된 CUDA 커널로 모델을 TensorRT 엔진으로 컴파일합니다. 그런 다음 이러한 엔진은 몇 가지 최적화를 포함하는 TensorRT-LLM 런타임에 의해 실행됩니다:
- 인플라이트 배칭(in-flight batching)
- KV 캐싱
- 저정밀 워크로드 지원을 위한 양자화
TensorRT-LLM은 확장된 회전 위치 임베딩(RoPE) 기법으로 128K의 긴 컨텍스트 길이를 지원하며, H100의 BF16 정밀도 수준 모델에서 멀티 GPU 및 멀티 노드 추론과 H200의 단일 노드 추론을 포함한 Llama 3.1-405B의 멀티 GPU 및 멀티 노드 추론을 지원합니다.
FP8 정밀도의 추론이 지원됩니다. NVIDIA Hopper 및 NVIDIA Ada GPU에서 훈련 후 양자화(PTQ)를 사용하면 정확도 저하 없이 더 작은 메모리 풋프린트로 더 작은 모델을 생성하여 모델 복잡성을 최적화하고 줄일 수 있습니다.
Llama 3.1-405B 모델의 경우, TensorRT-LLM은 행 단위 세분화 수준에서 FP8 양자화에 대한 지원을 추가했습니다. 여기에는 최대 정확도를 유지하기 위해 각 출력 가중치 채널에 대한 정적 스케일링 계수(실행 전)와 각 토큰에 대한 동적 스케일링 계수(실행 중)를 계산하는 것이 포함됩니다.
TensorRT 엔진 빌드 프로세스 중에 일부 복잡한 레이어 융합은 자동으로 발견할 수 없습니다. TensorRT-LLM은 컴파일 시 네트워크 그래프 정의에 명시적으로 삽입되는 플러그인을 사용해 이를 최적화하여 Llama 3.1 모델의 경우 FBGEMM의 행렬 곱셈과 같은 사용자 정의 커널을 대체합니다.
사용 및 배포의 용이성을 위해 TensorRT-Model-Optimizer 및 TensorRT-LLM 최적화는 NVIDIA NIM 추론 마이크로서비스에 함께 번들로 제공됩니다.
NVIDIA NIM
이제 프로덕션 배포를 위해 NVIDIA NIM을 통해 Llama 3.1이 지원됩니다. NIM 추론 마이크로서비스는 클라우드, 데이터센터, 워크스테이션 등 어디서나 NVIDIA 가속 인프라 전반에 걸쳐 생성형 AI 모델의 배포를 가속화합니다.
NIM은 동적 LoRA 어댑터 선택을 지원하므로 단일 파운데이션 모델로 여러 사용 사례를 제공할 수 있습니다. 이는 GPU 및 호스트 메모리 전반에서 어댑터를 관리하는 멀티티어 캐시 시스템을 통해 가능하며, 특수 GPU 커널로 여러 사용 사례를 동시에 제공하도록 가속화됩니다.
다음 단계
NVIDIA 가속 컴퓨팅 플랫폼을 사용하면 데이터센터부터 NVIDIA RTX 및 NVIDIA Jetson에 이르기까지 모든 플랫폼에서 모든 단계에서 Llama 3.1을 사용하여 모델과 애플리케이션을 구축할 수 있습니다.
NVIDIA는 오픈 소스 소프트웨어 및 모델을 발전, 최적화 및 기여하기 위해 최선을 다하고 있습니다. 생성형 AI를 위한 NVIDIA AI 플랫폼에 대해 자세히 알아보세요.
관련 리소스
- NGC 컨테이너: Llama-3.1-8b-base
- NGC 컨테이너: Llama-3.1-8b-instruct
- NGC 컨테이너: Llama-3.1-70b-instruct
- SDK: Llama3 8B Instruct NIM
- SDK: Streamline
- SDK: Llama3 70B Instruct NIM