
멀티 카메라 입력 및 심층 합성곱 백본망(deep convolutional backbone network)의 채택으로 인해 자율주행 인식 모델을 트레이닝하기 위한 GPU 메모리 설치 공간이 커졌습니다. 메모리 사용량을 줄이기 위한 기존 방법은 추가 연산 오버헤드 또는 불균형한 워크로드를 초래하는 경우가 많습니다.
이 게시물에서는 NVIDIA와 스마트 전기 자동차 개발사인 NIO 간의 공동 연구에 대해 설명합니다. 특히 Tensor 병렬 합성곱 신경망(CNN) 트레이닝이 GPU 메모리 설치 공간을 줄이는 데 어떻게 도움이 될 수 있는지 살펴봅니다. 또한 NIO가 자율주행 자동차를 위한 인식 모델의 트레이닝 효율성과 GPU 활용도를 개선한 방법에 대해 시연합니다.
자율주행 자동차에 대한 인식 모델 훈련
자율주행 인식 작업은 멀티 카메라 데이터를 입력으로, CNN을 백본으로 사용하여 특성을 추출합니다. CNN의 순방향 활성화는 (N, C, H, W) 모양의 특성 맵이며, 여기서 N, C, H, W는 각각 이미지 수, 채널 수, 높이, 너비에 해당합니다. 역전파를 위해 활성화 상태를 저장해야 하므로 백본 트레이닝에는 일반적으로 상당한 메모리가 소모됩니다.
예를 들어 720픽셀 해상도의 6개 카메라 RGB 입력이 있고 배치 크기가 1로 설정된 경우 백본망의 입력 모양은 (6, 3, 720, 1280)입니다. RegNet 또는 ConvNeXt와 같은 백본망의 경우 활성화의 메모리 설치 공간이 모델 가중치 및 최적화 상태의 메모리 사용량보다 훨씬 크며 GPU 메모리 크기의 한도를 초과할 수 있습니다.
NIO 자율주행 팀의 연구에 따르면 더 심층적인 모델과 더 높은 이미지 해상도를 채택했을 때 인식 정확도가 크게 향상될 수 있으며, 특히 작고 멀리 있는 표적을 인식할 때 더욱 그렇습니다. 11개의 8메가픽셀 HD 카메라로 구동되는 NIO Aquila Super Sense 시스템은 초당 8GB의 이미지 데이터를 생성합니다.
GPU 메모리 최적화에 대한 요구
심층 모델과 고해상도 입력으로 인해 GPU 메모리 최적화에 대한 요구가 높아졌습니다. 활성화의 과도한 GPU 메모리 공간을 해결하기 위한 현재 기술에는 순방향 전파 중에 레이어 일부의 활성화만 유지하는 그래디언트 체크포인트(gradient checkpointing)가 포함됩니다. 다른 계층의 경우 역전파 중에 활성화가 다시 계산됩니다.
GPU 메모리를 절약함에도 불구하고 컴퓨팅 오버헤드가 증가하고 모델 트레이닝 속도가 느려집니다. 또한 그래디언트 체크포인트를 설정하려면 일반적으로 개발자가 모델 구조에 따라 선택하고 디버깅해야 하므로 모델 트레이닝에 추가 비용이 듭니다.
NIO는 또한 GPU 메모리 오버헤드를 기반으로 신경망을 균등하게 분할하고 트레이닝을 위해 여러 GPU에 배포하는 파이프라인 병렬 처리를 사용했습니다. 이 접근 방식은 스토리지 요구 사항을 여러 GPU에 균등하게 분산시킵니다. 하지만 GPU 간에 심각한 로드 불균형이 발생하고 일부 GPU의 활용률이 충분하지 않은 상황에 처합니다.
PyTorch DTensor 기반 Tensor 병렬 CNN 트레이닝
이러한 요인을 고려하여 NVIDIA와 NIO는 여러 GPU에서 입력과 중간 활성화를 슬라이스하는 Tensor 병렬 CNN 트레이닝을 공동으로 설계하고 구현했습니다. 모델 가중치와 최적화 상태는 데이터 병렬 트레이닝과 마찬가지로 각 GPU에 복제됩니다. 이 접근 방식으로 개별 GPU의 GPU 메모리 설치 공간이 줄어들고 대역폭 압박이 감소합니다.
PyTorch 2.0에 도입된 DTensor는 샤딩 및 복제와 같은 Tensor 분포를 표현하기 위한 기본 요소를 제공합니다. DTensor의 기본 구현은 이미 NCCL(NVIDIA Collective Communications Library)과 같은 통신 라이브러리를 캡슐화했기 때문에 이를 통해 사용자는 명시적으로 통신 연산자를 호출하지 않고도 분산 컴퓨팅을 쉽게 수행할 수 있습니다.
DTensor의 추상화를 통해 사용자는 Tensor 병렬, 분산 데이터 병렬 및 완전히 샤딩된 데이터 병렬을 포함한 다양한 병렬 트레이닝 전략을 쉽게 구축할 수 있습니다.
구현
비전 작업을 위한 CNN 모델인 ConvNeXt-XL을 예로 들어 Tensor 병렬 CNN 트레이닝을 시연해 보겠습니다. DTensor를 다음과 같이 배치합니다.
- 모델 매개변수:
Replicate- 각 GPU에 반복적으로 배치합니다. 해당 모델은 3억 5,000만 개의 매개변수를 포함하며 FP32에 저장될 때 1.4GB의 GPU 메모리를 사용합니다.
- 모델 입력:
Shard(3)- (N, C, H, W)의 W 차원을 슬라이싱합니다. 입력 슬라이스를 각 GPU에 배치합니다. 예를 들어, 4개의 GPU에서 모양(7, 3, 512, 2048)을 입력하기 위한
Shard(3)는 4개의 모양 슬라이스(7, 3, 512, 512)를 생성합니다.
- (N, C, H, W)의 W 차원을 슬라이싱합니다. 입력 슬라이스를 각 GPU에 배치합니다. 예를 들어, 4개의 GPU에서 모양(7, 3, 512, 2048)을 입력하기 위한
- 활성화:
Shard(3)- (N, C, H, W)의 W 차원을 슬라이싱합니다. 각 GPU에 활성화 슬라이스를 배치합니다.
- 모델 매개변수의 그래디언트:
Replicate- 각 GPU에 반복적으로 배치합니다.
- 최적화 상태:
Replicate- 각 GPU에 반복적으로 배치합니다.
위 구성은 DTensor에서 제공하는 API를 통해 수행할 수 있습니다. 사용자는 모델 매개변수 및 모델 입력의 배치를 지정하기만 하면 다른 Tensor의 배치가 자동으로 생성됩니다.
Tensor 병렬 트레이닝을 활성화하려면 합성곱 연산자 aten.convolution 및 aten.convolution_backward에 대한 전파 규칙을 등록해야 합니다. 그러면 입력 DTensor의 배치에 따라 출력 DTensor의 배치가 결정됩니다.
aten.convolution- 입력 배치는
Shard(3), 가중치 및 편향 배치는Replicate, 출력 배치는Shard(3)
- 입력 배치는
aten.convolution_backwardgrad_output배치는Shard(3), 가중치 및 편향 배치는Replicate,grad_input배치는Shard(3),grad_weight및grad_bias배치는_Partial
_Partial 배치가 있는 DTensor는 해당 값이 사용되고 기본 축소 연산자가 합계인 경우 자동으로 축소 연산을 수행합니다.
다음은 Tensor 병렬 합성곱 연산자의 순방향 및 역방향 구현입니다. 활성화가 여러 GPU에 걸쳐 슬라이스되기 때문에 하나의 GPU의 로컬 합성곱은 GPU 간 통신이 필요한 인접 GPU의 활성화의 엣지 데이터가 필요할 수 있습니다. ConvNeXt-XL 모델에서는 이 문제가 다운샘플링 레이어의 합성곱에서 보이지 않지만 Block의 깊이별 합성곱에서 처리해야 합니다.
데이터 교환이 필요하지 않은 경우 사용자는 합성곱의 순방향 및 역방향 연산자를 직접 호출하고 로컬 Tensor를 전달할 수 있습니다. 로컬 활성화의 Tensor 엣지 데이터를 교환해야 하는 경우 그림 1과 2에 표시된 합성곱 순방향 및 역방향 알고리즘을 사용합니다. 그림에서 N 및 C 차원을 생략하고 합성곱 커널 크기가 5×5, 패딩이 2, 스트라이드가 1이라고 가정합니다.
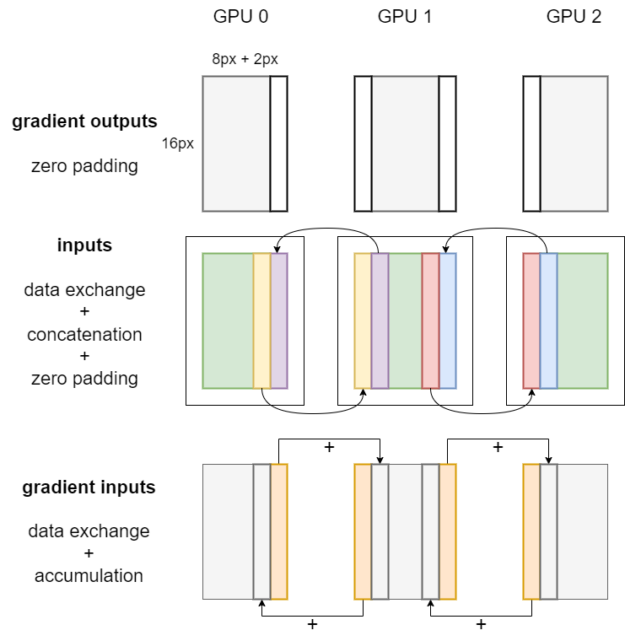
그림 1에서 볼 수 있듯이 합성곱 커널 크기가 5×5, 패딩이 2, 스트라이드가 1일 때 각 GPU의 로컬 입력은 인접한 GPU에서 너비 2의 입력 엣지를 가져와서 수신된 엣지 데이터를 연결해야 합니다. 즉, Tensor 병렬 합성곱의 정확성을 보장하기 위해서는 GPU 간 데이터 교환이 필요합니다. 이 데이터 교환은 PyTorch에 캡슐화된 NCCL 송수신 통신 연산자를 호출하여 활성화할 수 있습니다.
활성화가 여러 GPU에서 슬라이스되는 경우 합성곱 연산자의 일부 패딩이 필요하지 않다는 점은 언급할 가치가 있습니다. 그림 1의 파란색 패턴 막대에서 볼 수 있듯이 로컬 합성곱 순방향 전파가 완료된 후 출력에서 원치 않는 패딩으로 인해 발생한 유효하지 않은 픽셀을 잘라야 합니다.
그림 2는 Tensor 병렬 합성곱에 대한 역전파의 워크플로우를 보여줍니다. 먼저 제로 패딩이 그래디언트 출력에 적용되며, 이는 순방향 전파 중 출력에 대한 자르기 작업에 해당합니다. 로컬 입력의 경우 데이터 교환, 연결 및 패딩과 동일한 절차가 수행됩니다.
이후 각 GPU에서 합성곱 역방향 연산자를 호출하여 가중치 그래디언트, 편향 그래디언트 및 그래디언트 입력을 얻을 수 있습니다.
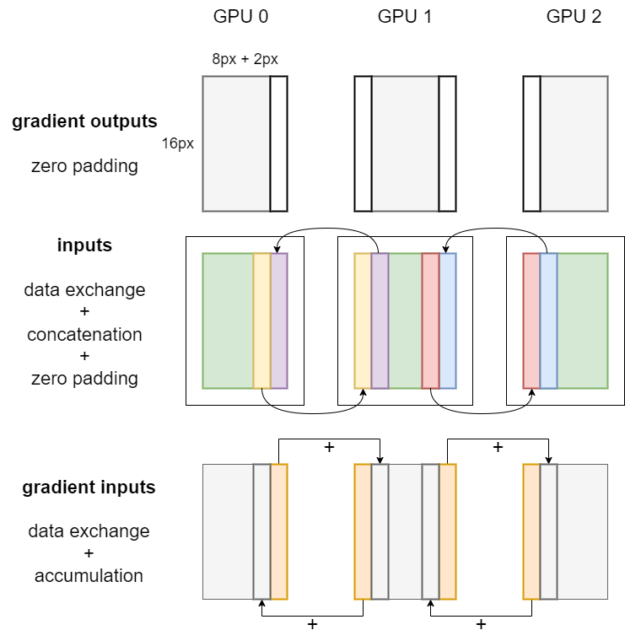
가중치 그래디언트 및 편향 그래디언트의 배치는 _Partial이므로 사용 시 여러 GPU에서 해당 값이 자동으로 감소합니다. 그래디언트 입력의 배치는 Shard(3)입니다.
마지막으로 그림 2의 주황색 막대로 표시된 것처럼 로컬 그래디언트 입력의 엣지 픽셀은 인접한 GPU로 전송되어 해당 위치에 누적됩니다.
합성곱 레이어 외에도 ConvNeXt-XL에는 Tensor 병렬 트레이닝을 지원하기 위해 처리해야 하는 여러 레이어가 있습니다. 예를 들어 전파 규칙은 DropPath 레이어에서 사용되는 aten.bernoulli 연산자에 대해 등록되어야 합니다. 이 연산자는 GPU 전반에서 일관성을 보장하기 위해 난수 생성 추적기의 분산 영역에 배치되어야 합니다.
모든 코드가 PyTorch GitHub 리포지토리의 메인 브랜치에 병합되었으므로 사용자는 DTensor의 상위 수준 API를 직접 호출하여 Tensor 병렬 CNN 트레이닝을 구현할 수 있습니다.
Tensor 병렬 처리를 사용한 ConvNeXt 트레이닝의 벤치마크 결과
저희는 ConvNeXt-XL 트레이닝의 속도와 GPU 메모리 설치 공간을 살펴보기 위해 NVIDIA DGX AI 플랫폼에 대한 벤치마크를 수행했습니다. 그래디언트 체크포인트와 DTensor 기술은 서로 호환되며 두 기술을 결합하여 GPU 메모리 사용량을 더 크게 줄일 수 있습니다.
이 벤치마크의 기준은 입력 크기(7, 3, 512, 1024)가 있는 하나의 NVIDIA GPU에서 PyTorch 기본 Tensor를 사용하는 것입니다. 그래디언트 체크포인트가 없을 경우 GPU 메모리 설치 공간은 43.28GiB이며 단일 트레이닝 반복에는 723ms가 소요됩니다. 그래디언트 체크포인트를 사용하면 각각 11.89GiB와 934ms입니다.
전체 결과는 그림 3과 4에 나와 있습니다. 전역 입력 모양은 (7, 3, 512, W)이며, 여기서 W는 1024에서 8192까지 다양합니다. 실선은 그래디언트 체크포인트가 적용되지 않은 결과이고 점선은 그래디언트 체크포인트가 적용된 결과입니다.
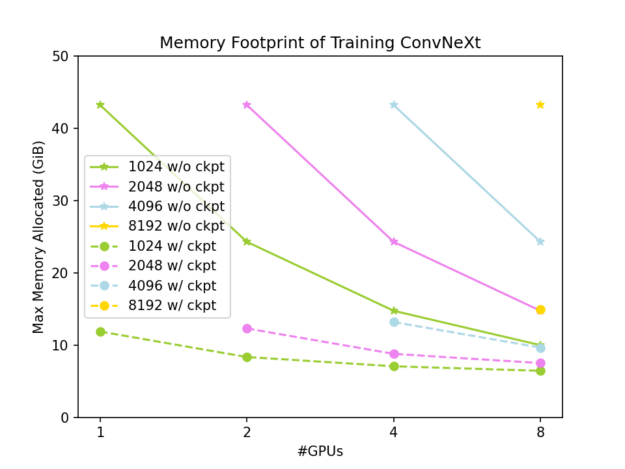
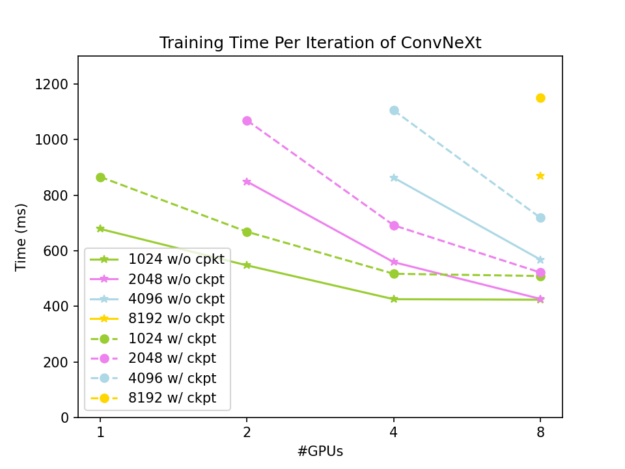
그림 3에서 볼 수 있듯이 DTensor를 사용하여 활성화를 슬라이싱하면 ConvNeXt-XL 트레이닝의 GPU 메모리 설치 공간을 효과적으로 줄일 수 있으며 DTensor와 그래디언트 체크포인트를 모두 적용하면 매우 낮은 수준으로 줄일 수 있습니다. 그림 4에서 볼 수 있듯이 Tensor 병렬 접근 방식은 약한 확장성이 우수하며 문제 크기가 충분히 클 경우 우수한 확장성을 제공합니다. 다음은 그래디언트 체크포인트가 사용되지 않는 경우를 살펴봅니다.
- 2개의 GPU에서 모양(7, 3, 512, 2048)의 전역 입력의 경우 단일 반복에는 937ms가 소요됩니다.
- 4개의 GPU에서 모양(7, 3, 512, 4096)의 전역 입력의 경우 단일 반복에는 952ms가 소요됩니다.
- 8개의 GPU에서 모양(7, 3, 512, 4096)의 전역 입력의 경우 단일 반복에는 647ms가 소요됩니다.
결론
DTensor를 사용하여 Tensor 병렬 CNN 트레이닝을 구현하면 NIO의 핵심 자율주행 서비스 전용 R&D 플랫폼인 NADP(NIO Autonomous Driving Development Platform)에서 트레이닝 효율성을 효과적으로 개선하는 솔루션을 제공합니다. NADP는 매일 수십만 개의 추론 및 트레이닝 작업을 처리할 수 있는 고성능 컴퓨팅 및 풀체인 도구를 제공하여 액티브 세이프티 및 운전자 보조 기능의 지속적인 발전을 보장합니다.
이 핵심 접근 방식을 통해 NADP는 10,000-GPU 규모에서 병렬 컴퓨팅을 수행할 수 있습니다. 이를 통해 GPU 활용도를 개선하고 모델 트레이닝 비용을 절감하며 보다 유연한 모델 구조가 가능합니다. 벤치마크에 따르면 이 접근 방식은 NIO의 자율주행 시나리오에서 우수한 성능을 발휘하며 대형 비전 모델을 트레이닝하는 문제를 효과적으로 해결합니다.
PyTorch DTensor 기반의 CNN에 대한 Tensor 병렬 처리 트레이닝은 메모리 설치 공간을 크게 줄이고 우수한 확장성을 유지할 수 있습니다. 이 접근 방식으로 컴퓨팅 성능과 여러 GPU의 상호 연결을 완전히 활용하여 인식 모델 트레이닝에 보다 폭넓게 액세스할 수 있을 것으로 기대합니다.
자세한 내용은 PyTorch GitHub 리포지토리를 참조하세요.