임베딩은 딥 러닝 추천자 모델에서 중요한 역할을 합니다. 이는 데이터의 인코딩된 범주 입력을 수학 계층 또는 멀티레이어 퍼셉트론(MLP)에서 처리할 수 있는 수치 값에 매핑하는 데 사용됩니다.
임베딩은 딥 러닝 추천자 모델에서 대부분의 매개변수를 구성하며 대규모로서 테라바이트 규모에도 도달 가능합니다. 트레이닝 시에는 단일 GPU의 메모리에 맞추기 어려울 수 있습니다.
따라서, 최신 추천자는 합리적인 트레이닝 시간을 달성하고 사용 가능한 GPU 컴퓨팅을 최대한 활용하기 위해 모델 병렬 및 데이터 병렬 분산 트레이닝 접근법의 조합을 필요로 할 수 있습니다.
TensorFlow 2의 모델(예: 추천자)을 기반으로 대규모 임베딩을 트레이닝하기 위한 라이브러리인 NVIDIA Merlin 분산 임베딩을 사용하면 단 몇 줄의 코드만으로 쉽게 달성할 수 있습니다.
배경
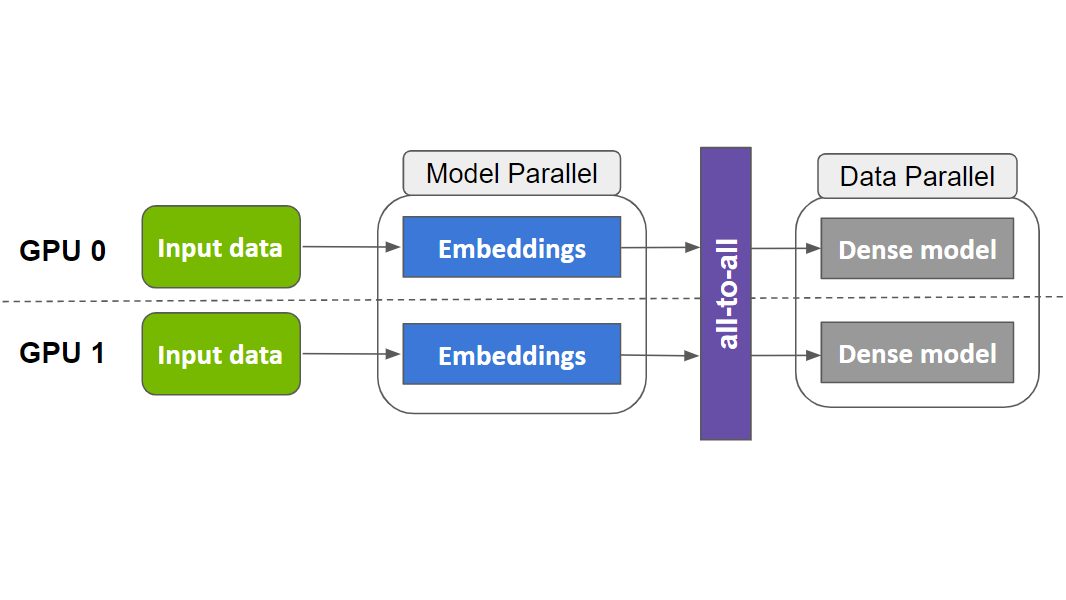
GPU에서의 데이터 병렬 분산 트레이닝을 통해 전체 모델이 각 GPU 작업자에서 복제됩니다. 데이터 배치는 트레이닝 중에 여러 GPU 간에 분할되며 각 디바이스는 자체 데이터 조각에서 독립적으로 작동합니다.
이로써 더 큰 배치를 통해 연산을 더 많은 수량의 데이터로 확장할 수 있습니다. 역전파 중에 계산된 그래디언트는 동기 매개변수 업데이트를 위해 감소 연산(예: horovod.tensorflow.allreduce)을 사용하여 모든 디바이스에 누적됩니다.
모델 병렬 분산 트레이닝을 사용하면 모델 매개변수가 다양한 작업자 간에 분할됩니다. 이는 대형 임베딩 테이블을 배포하는 더 적합한 방법입니다. 트레이닝에는 작업자가 파티션에 없는 매개변수에 액세스할 수 있도록 올 투 올 통신 프리미티브(예: horovod.tensorflow.alltoall)를 사용해야 합니다.
Tomasz는 관련된 이전 게시물인 TensorFlow 2에서 매개변수가 100B 이상인 DGX A100의 추천 시스템 트레이닝에서 여러 NVIDIA GPU에 걸쳐 1,130억 개의 매개변수 DLRM 모델을 위한 임베딩을 분산시키는 것이 CPU 전용 솔루션에 대해 672배 빠른 속도를 달성하는 데 어떻게 도움이 되는지에 대해 논의했습니다. 이렇게 현저히 개선된 점을 통해 잠재적으로 며칠에서 몇 분으로 트레이닝 시간을 단축할 수 있습니다! 이는 모델 병렬화로 임베딩 테이블을 분산하고 데이터 병렬화로 훨씬 작은 수학 집약적 MLP 계층 계산을 수행함으로써 가능합니다.
이 하이브리드 접근 방식은 임베딩을 CPU 메모리에 저장하는 것과 비교할 때 메모리 바운드되는 임베딩 룩업에 GPU 메모리의 고메모리 대역폭을 사용할 수 있도록 합니다. 또한 여러 GPU 디바이스의 컴퓨팅 성능을 사용하여 MLP 계층을 가속화합니다. 참고로 NVIDIA A100-80GB GPU에는 2TB/s 이상의 대역폭을 갖춘 80GB HBM2 메모리가 있습니다.
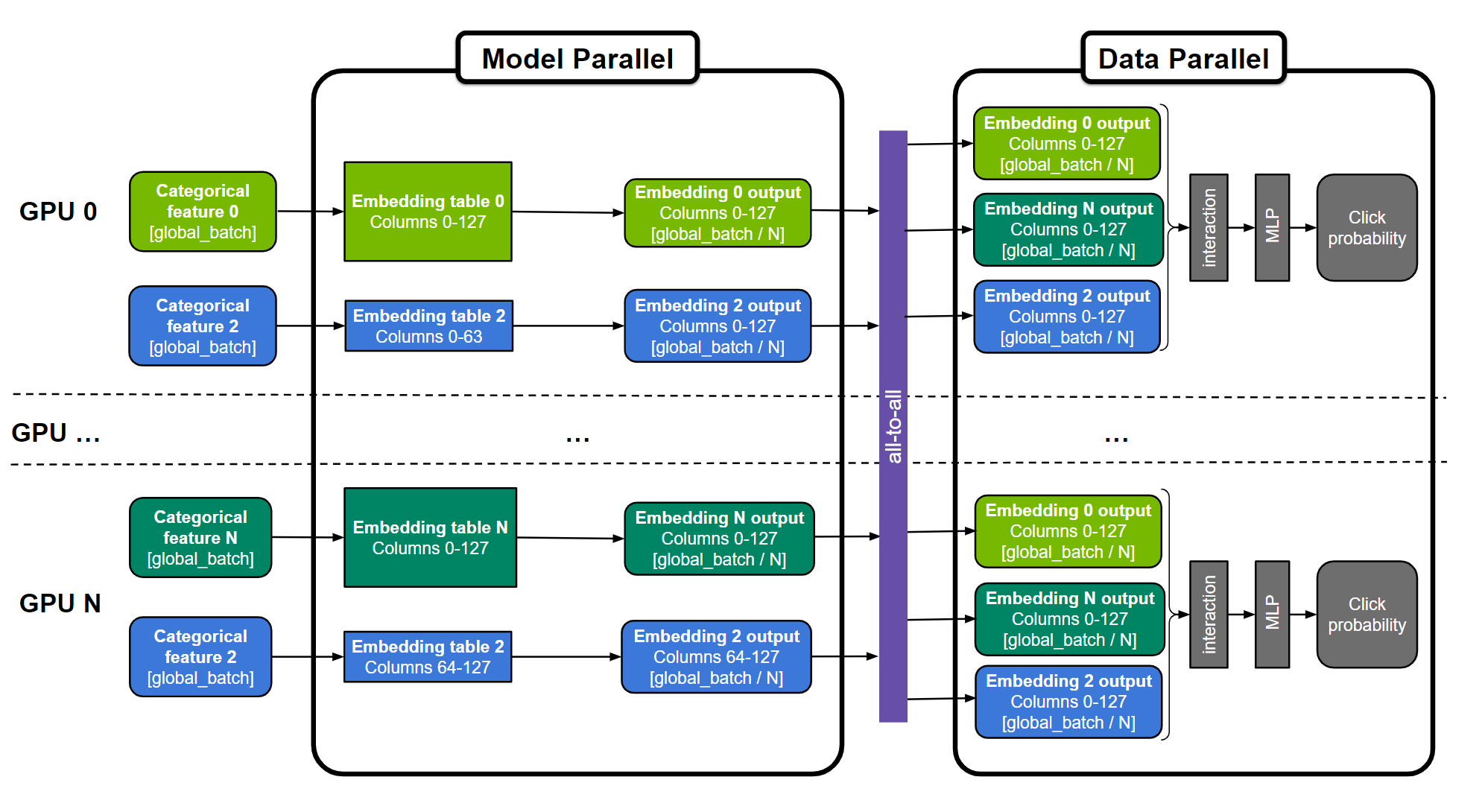
임베딩 테이블은 ‘테이블별’(예: 임베딩 테이블 0 및 N), ‘열별’(예: 임베딩 테이블 2) 또는 ‘행별’로 분할될 수 있습니다. MLP 레이어는 모든 GPU에서 복제됩니다. 수치 특성은 MLP 계층에 직접 공급될 수 있으며 해당 그림에 표현되지 않습니다.
그러나 이러한 복잡한 하이브리드 병렬 트레이닝 접근 방식을 구현하는 것은 쉽지 않으며, 해당 분야의 전문가가 트레이닝을 개발하고 최적화하기 위해 수백 줄의 저수준의 코드를 엔지니어링해야 합니다.
보다 폭넓게 액세스할 수 있도록 NVIDIA Merlin 분산 임베딩 라이브러리는 단 세 줄의 Python 코드만으로 TensorFlow 2에서 모델 병렬화를 대중화하기 위해 사용하기 쉬운 래퍼를 제공합니다. 임베딩 테이블을 여러 GPU에 자동으로 배포하는 확장 가능한 모델 병렬 래퍼와 더불어 TensorFlow의 임베딩 기능을 다루고 확장하는 효율적인 임베딩 연산을 제공합니다. 하이브리드 병렬화를 지원하는 방법은 다음과 같습니다.
분산된 모델 병렬
NVIDIA Merlin 분산 임베딩은 distributed_embeddings.dist_model_parallel 모듈을 제공합니다. 복잡한 코드 없이 여러 GPU 작업자 전체에 임베딩을 배포하도록 지원하여 all2all과 같은 프리미티브와의 교차 작업자 통신을 처리할 수 있습니다. 다음 코드 예제에서는 이 API의 사용을 보여줍니다.
import dist_model_parallel as dmp
class MyEmbeddingModel(tf.keras.Model):
def __init__(self, table_sizes):
...
self.embedding_layers = [tf.keras.layers.Embedding(input_dim, output_dim) for input_dim, output_dim in table_sizes]
# 1. Add this line to wrap list of embedding layers used in the model
self.embedding_layers = dmp.DistributedEmbedding(self.embedding_layers)
def call(self, inputs):
# embedding_outputs = [e(i) for e, i in zip(self.embedding_layers, inputs)]
embedding_outputs = self.embedding_layers(inputs)
...Horovod를 사용하여 데이터 병렬 방식으로 고밀도 계층을 실행하려면 Horovod의 분산 그래디언트테이프 및 브로드캐스트 방법을 분산 임베딩에서 동급으로 대체하세요. 다음 예는 Horovod 문서에서 직접 가져와 알맞게 수정되었습니다.
@tf.function
def training_step(inputs, labels, first_batch):
with tf.GradientTape() as tape:
probs = model(inputs)
loss_value = loss(labels, probs)
# 2. Change Horovod Gradient Tape to dmp tape
# tape = hvd.DistributedGradientTape(tape)
tape = dmp.DistributedGradientTape(tape)
grads = tape.gradient(loss_value, model.trainable_variables)
opt.apply_gradients(zip(grads, model.trainable_variables))
if first_batch:
# 3. Change Horovod broadcast_variables to dmp's
# hvd.broadcast_variables(model.variables, root_rank=0)
dmp.broadcast_variables(model.variables, root_rank=0)
return loss_value이러한 사소한 변경 사항을 통해 모든 것이 하이브리드 병렬 트레이닝 단계로 설정됩니다!
또한 Criteo 1TB 클릭 로그 데이터를 통해 DLRM 모델을 트레이닝하는 전체 예제와 모델 크기를 최대 22.8TiB까지 확장하는 합성 데이터도 제공합니다.
성능
NVIDIA Merlin 분산 임베딩을 사용하는 이점을 시연하기 위해 Criteo 1TB 데이터세트에서 훈련된 DLRM 모델과 최대 3TiB 임베딩 테이블 크기로 다양한 합성 모델에 대한 벤치마크를 보여줍니다.
Criteo 데이터세트에 대한 DLRM 벤치마크
벤치마크에 따르면 NVIDIA는 훨씬 간단한 API를 사용하여 전문가 엔지니어링 코드와 유사한 성능을 유지한다는 것을 알 수 있습니다. TensorFlow 2를 사용하는 NVIDIA DeepLearningExamples DLRM 코드도 이제 NVIDIA Merlin 분산 임베딩과 하이브리드 병렬 트레이닝을 활용하도록 업데이트되었습니다. 자세한 내용은 이전 게시물인 TensorFlow 2에서 1000억 개 이상의 매개변수가 있는 DGX A100의 추천 시스템 트레이닝하기을 참조하세요.
README의 벤치마크 섹션은 성능 수치에 대한 더 많은 인사이트를 제공합니다.
1130억 개의 매개변수(421 GiB 모델 크기)가 있는 DLRM 모델은 다음과 같은 세 가지 하드웨어 설정에 걸쳐 Criteo Terabyte Click Logs 데이터세트에서 트레이닝되었습니다.
- CPU로만 구성된 솔루션입니다.
- CPU 메모리를 사용하여 가장 큰 임베딩 테이블을 저장하는 단일 GPU 솔루션입니다.
- 8개의 GPU가 탑재된 NVIDIA DGX A100-80GB를 사용하는 하이브리드 병렬 솔루션입니다. 이는 NVIDIA Merlin 분산 임베딩에서 제공하는 모델 병렬 래퍼 및 임베딩 API를 활용합니다.
| 하드웨어 | 설명 | 트레이닝 처리량(샘플/초) | CPU에 대한 속도 향상 |
| 2개의 AMD EPYC 7742 | MLP 계층과 임베딩 모두 CPU | 17.7k | 1x |
| 1개의 A100-80GB, 2개의 AMD EPYC 7742 | 대형 임베딩은 CPU, 나머지는 GPU | 768k | 43개 |
| DGX A100(8xA100-80GB) | NVIDIA Merlin 분산 임베딩을 통한 하이브리드 병렬, 전체 모델은 GPU | 12.1M | 683x |
NVIDIA는 DGX-A100의 분산 임베딩 솔루션이 CPU 전용 솔루션보다 무려 683배 더 빠른 속도를 제공한다는 점을 확인했습니다! 또한 단일 GPU 솔루션보다 성능이 크게 향상되는 것을 알 수 있습니다. 이는 GPU 메모리에 모든 임베딩을 유지하면 CPU-GPU 인터페이스에 대한 임베딩 룩업의 오버헤드가 없어지기 때문입니다.
합성 모델 벤치마크
솔루션의 확장성을 더욱 입증하기 위해 다양한 크기의 합성 DLRM 모델을 만들었습니다(표 2). 모델 생성 방법론과 트레이닝 스크립트에 대한 자세한 내용은 NVIDIA-Merlin/분산 임베딩 GitHub 리포지토리를 참조하세요.
| 모델 | 총 임베딩 테이블 수 | 총 임베딩 크기(GiB) |
| 초소형 | 55 | 4.2 |
| 소형 | 107 | 26.3 |
| 중형 | 311 | 206.2 |
| 대형 | 612 | 773.8 |
| 초대형 | 1,022 | 3,109.5 |
각 합성 모델은 하나 이상의 DGX-A100-80GB 노드, 글로벌 배치 크기 65,536개 및 Adagrad 최적화 도구를 사용하여 트레이닝되었습니다. 표 3에서 볼 수 있는 것은 NVIDIA Merlin 분산 임베딩이 수백 개의 GPU에서 테라바이트 규모의 모델을 쉽게 트레이닝할 수 있다는 것입니다.
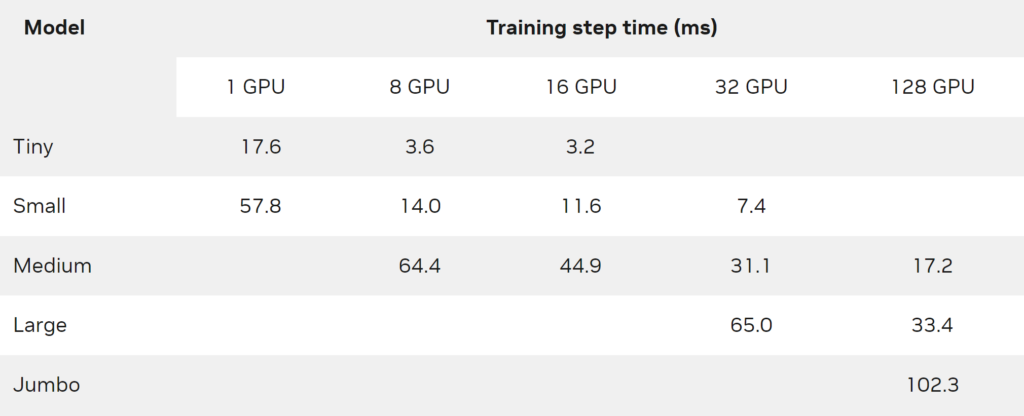
한편, 단일 GPU에 맞출 수 있는 모델의 경우에도 분산 임베딩의 모델 병렬화는 기존의 데이터 병렬화에 비해 멀티 GPU로 상당한 가속을 제공합니다. 이는 표 4에서 초소형 모델이 DGX A100-80GB에서 실행되는 모습을 통해 볼 수 있습니다.

이 실험에서 글로벌 배치 크기는 65,536이며 Adagrad 최적화 도구를 사용했습니다.
결론
이 게시물에서는 몇 줄의 코드만으로 NVIDIA GPU에서 임베딩 기반 딥 러닝 모델의 확장 가능하고 효율적인 모델 병렬 트레이닝을 지원하는 NVIDIA Merlin 분산 임베딩 라이브러리를 소개했습니다. 시작하려면 합성 데이터로 확장 가능한 트레이닝과 Criteo 데이터에서 DLRM 모델을 트레이닝하는 예제를 시도해 보세요.
이 블로그에 열거된 SDK의 대부분의 독점 액세스, 얼리 액세스, 기술 세션, 데모, 교육 과정, 리소스는 NVIDIA 개발자 프로그램 회원은 무료로 혜택을 받으실 수 있습니다. 지금 무료로 가입하여 NVIDIA의 기술 플랫폼에서 구축하는 데 필요한 도구와 교육에 액세스하시고 여러분의 성공을 가속화 하세요.