
새로운 Mistral 3 오픈 모델 패밀리는 뛰어난 정확도, 효율성, 맞춤형 기능을 갖춰 개발자와 기업 모두에게 최적의 선택지를 제공합니다. 이 모델은 NVIDIA GB200 NVL72부터 엣지 플랫폼까지 폭넓게 최적화되어 있으며, 구성은 다음과 같습니다:
- 총 675B 파라미터 규모의 최첨단 스파스 멀티모달 및 다국어 전문가 혼합(MoE) 거대 모델
- 3B, 8B, 14B 크기의 고성능 소형 덴스 모델 시리즈(Ministral 3), 각각 Base, Instruct, Reasoning 버전으로 구성된 총 9개 모델
모든 모델은 NVIDIA Hopper GPU에서 학습되었으며, 현재 Hugging Face의 Mistral AI를 통해 제공됩니다. 개발자는 다양한 NVIDIA GPU 환경에 맞춰, 모델 정밀도와 오픈소스 프레임워크 호환성에 따라 자유롭게 배포 방식을 선택할 수 있습니다 (표 1 참고).
| Mistral Large 3 | Ministral-3-14B | Ministral-3-8B | Ministral-3-3B | |
| 총 파라미터 수 | 675B | 14B | 8B | 3B |
| 활성 파라미터 수 | 41B | 14B | 8B | 3B |
| 컨텍스트 윈도우 | 256K | 256K | 256K | 256K |
| Base | – | BF16 | BF16 | BF16 |
| Instruct | – | Q4_K_M, FP8, BF16 | Q4_K_M, FP8, BF16 | Q4_K_M, FP8, BF16 |
| Reasoning | Q4_K_M, NVFP4, FP8 | Q4_K_M, BF16 | Q4_K_M, BF16 | Q4_K_M, BF16 |
| 지원 프레임워크 | ||||
| vLLM | ✔ | ✔ | ✔ | ✔ |
| SGLang | ✔ | – | – | – |
| TensorRT-LLM | ✔ | – | – | – |
| Llama.cpp | – | ✔ | ✔ | ✔ |
| Ollama | – | ✔ | ✔ | ✔ |
| NVIDIA 하드웨어 | ||||
| GB200 NVL72 | ✔ | ✔ | ✔ | ✔ |
| Dynamo | ✔ | ✔ | ✔ | ✔ |
| DGX Spark | ✔ | ✔ | ✔ | ✔ |
| RTX | – | ✔ | ✔ | ✔ |
| Jetson | – | ✔ | ✔ | ✔ |
표 1. Mistral 3 모델 사양
Mistral Large 3, NVIDIA GB200 NVL72에서 최고 수준의 성능 달성
NVIDIA로 가속된 Mistral Large 3는 최신 대규모 MoE 모델에 최적화된 통합 최적화 스택을 기반으로, NVIDIA GB200 NVL72에서 업계 최고 수준의 성능을 발휘합니다. 그림 1은 상호작용 목표에 따라 GB200 NVL72와 NVIDIA H200의 성능 효율을 파레토 프런티어 형태로 비교한 결과를 보여줍니다.
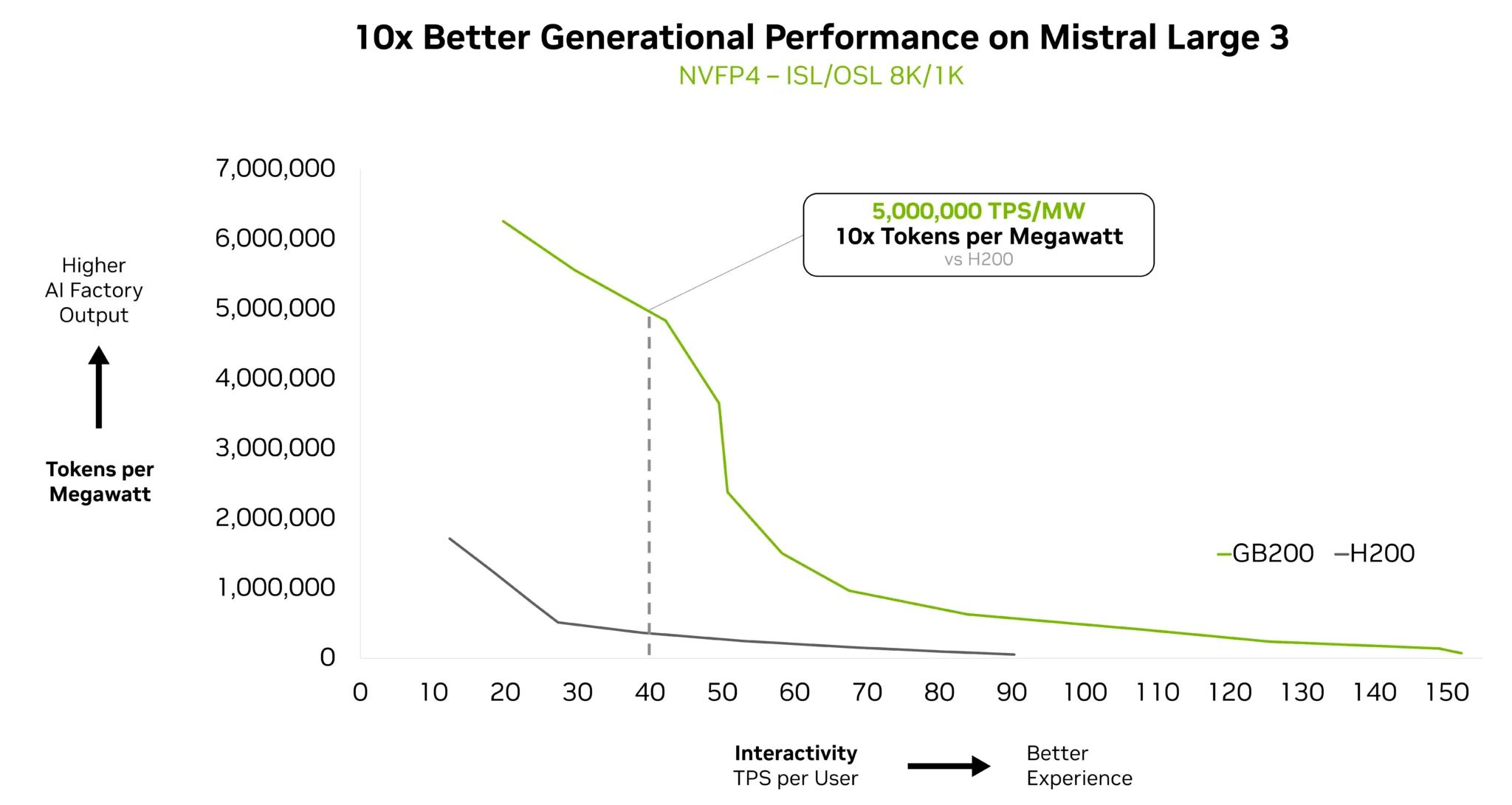
실제 AI 시스템에서는 뛰어난 사용자 경험(UX)과 비용 효율적인 확장성을 동시에 제공해야 합니다. 이러한 요구를 충족하기 위해 GB200은 이전 세대인 H200 대비 최대 10배 높은 성능을 발휘하며, 사용자당 초당 40토큰 기준으로 메가와트(MW)당 500만 토큰 이상의 처리 성능을 구현합니다.
이러한 세대 간 성능 향상은 더 나은 UX, 토큰당 비용 절감, 그리고 에너지 효율 개선으로 이어집니다. 이러한 이득은 다음과 같은 추론 최적화 스택의 구성 요소들에 의해 가능해졌습니다:
- NVIDIA TensorRT-LLM Wide Expert Parallelism(Wide-EP): NVL72의 일관된 메모리 도메인을 최대한 활용할 수 있도록 최적화된 MoE 전용 GroupGEMM 커널, 전문가 분산 및 로드 밸런싱, 전문가 스케줄링 기능을 제공합니다. 특히 주목할 점은 Wide-EP가 다양한 거대 MoE 아키텍처 변화에 강인하게 대응할 수 있다는 점입니다. 예를 들어, Mistral Large 3는 DeepSeek-R1의 절반 수준인 레이어당 128명의 전문가만 사용하지만, NVIDIA NVLink 패브릭이 제공하는 고대역폭, 저지연, 논블로킹 특성을 그대로 활용할 수 있습니다.
- 정확도를 유지하면서 효율을 극대화한 저정밀 추론: NVFP4를 활용해 효율성과 정확도를 동시에 달성했으며, SGLang, TensorRT-LLM, vLLM이 이를 지원합니다.
- NVIDIA Dynamo: Mistral Large 3는 NVIDIA의 저지연 분산 추론 프레임워크인 Dynamo를 활용해 프리필(prefill)과 디코드(decode) 단계를 분리하고 처리 속도를 일치시킴으로써, 8K/1K와 같은 장문 컨텍스트 워크로드에서 성능을 대폭 향상시킵니다(그림 1 참고).
모든 모델과 마찬가지로, 멀티토큰 예측(MTP)을 활용한 스페큘레이티브 디코딩(speculative decoding)과 EAGLE-3 같은 향후 성능 최적화 기술은 Mistral Large 3의 성능을 더욱 끌어올릴 것으로 기대됩니다. 이를 통해 모델의 잠재력을 한층 더 활용할 수 있습니다.
NVFP4 양자화
Mistral Large 3는 오픈소스 llm-compressor 라이브러리를 사용해 오프라인 양자화된 NVFP4 체크포인트를 통해 연산 최적화 배포가 가능합니다. 이는 NVFP4의 고정밀 FP8 스케일링 요소와 정밀한 블록 단위 스케일링을 활용하여 양자화 오차를 효과적으로 제어하면서 연산 및 메모리 비용을 절감할 수 있도록 합니다.
이 방법은 MoE 가중치에만 NVFP4 양자화를 적용하고, 나머지 구성 요소는 기존 체크포인트의 정밀도를 유지합니다. NVFP4는 Blackwell 아키텍처에 기본 탑재된 기능이기 때문에, GB200 NVL72에서 원활하게 배포할 수 있습니다. NVFP4의 FP8 스케일링 요소와 세밀한 블록 스케일링을 통해 정확도 손실을 최소화하면서 연산 및 메모리 비용을 줄일 수 있습니다.
오픈소스 추론 지원
이 모델들은 오픈소스 추론 프레임워크에서도 자유롭게 사용할 수 있습니다. TensorRT-LLM은 거대 MoE 모델을 위한 최적화를 적용해 GB200 NVL72 시스템에서 성능을 극대화하며, 사전 구성된 Docker 컨테이너를 통해 바로 시작할 수 있습니다.
또한 NVIDIA는 vLLM과 협력하여 EAGLE 기반 speculative decoding, NVIDIA Blackwell 아키텍처, 추론 단계 분리(disaggregation), 확장된 병렬 처리 등의 커널 통합을 지원하도록 기능을 확장했습니다. 시작하려면 NVIDIA 클라우드 GPU에서 실행 가능한 vLLM 기반 런처를 사용할 수 있습니다. 모델 서빙을 위한 기본 코드와 대표적인 API 호출 예시는 “Running Mistral Large 3 675B Instruct with vLLM on NVIDIA GPUs” 문서에서 확인할 수 있습니다.
그림 2는 Mistral Large 3 및 Ministral 3 모델을 배포할 수 있는 NVIDIA 빌드 플랫폼의 다양한 GPU 옵션을 보여줍니다. 요구 사항에 맞는 GPU 종류와 구성을 선택해 사용할 수 있습니다.

NVIDIA는 SGLang과 협업해, Mistral Large 3의 추론 단계 분리(disaggregation) 및 speculative decoding 기능이 포함된 구현도 개발했습니다. 자세한 내용은 SGLang 문서를 참고하세요.
Ministral 3 모델: 속도, 유연성, 정확성을 갖춘 경량 고성능 모델
Ministral 3 모델은 엣지 환경에 최적화된 소형 고성능 덴스 모델로, 3B, 8B, 14B의 세 가지 파라미터 크기와 각각 Base, Instruct, Reasoning 세 가지 버전으로 제공되어 다양한 요구에 유연하게 대응할 수 있습니다. 이 모델들은 NVIDIA GeForce RTX AI PC, NVIDIA DGX Spark, NVIDIA Jetson 등의 엣지 플랫폼에서 사용할 수 있습니다.
로컬 개발 환경에서도 NVIDIA 가속의 이점을 그대로 누릴 수 있습니다. NVIDIA는 Llama.cpp, Ollama와 협력해 더 빠른 반복, 낮은 지연 시간, 향상된 데이터 프라이버시를 제공합니다. 예를 들어, Ministral-3B 모델은 NVIDIA RTX 5090 GPU에서 최대 초당 385토큰의 빠른 추론 속도를 구현할 수 있습니다. 시작은 Ollama 또는 Llama.cpp로 간편하게 할 수 있습니다.
Jetson 개발자의 경우, Ministral-3-3B-Instruct 모델을 NVIDIA Jetson Thor에서 vLLM 컨테이너를 활용해 실행할 수 있으며, 단일 동시성 기준으로 초당 52토큰, 동시성 8에서는 최대 273토큰까지 확장 가능합니다.
NVIDIA NIM을 통한 실사용 배포 준비 완료
Mistral Large 3와 Ministral-14B-Instruct는 NVIDIA API 카탈로그 및 프리뷰 API를 통해 바로 사용해볼 수 있으며, 최소한의 설정만으로 빠르게 시작할 수 있습니다. 곧 기업 개발자들은 NVIDIA NIM 마이크로서비스를 다운로드하여 GPU 가속 인프라 전반에 손쉽게 배포할 수 있게 될 예정입니다.
오픈소스 AI 개발, 지금 시작하세요
NVIDIA 가속으로 구현된 Mistral 3 오픈 모델 패밀리는 오픈소스 커뮤니티, 특히 Transatlantic AI 분야에서 큰 도약을 의미합니다. 거대 MoE 모델부터 엣지에 최적화된 덴스 트랜스포머까지 폭넓은 유연성을 갖춘 이 모델들은, 개발자의 환경과 워크플로우에 자연스럽게 녹아들 수 있도록 설계되었습니다.
NVIDIA의 성능 최적화, NVFP4와 같은 고급 양자화 기술, 다양한 프레임워크 지원을 통해 개발자는 클라우드부터 엣지까지 탁월한 효율성과 확장성을 구현할 수 있습니다. 시작하려면 Hugging Face에서 Mistral 3 모델을 다운로드하거나, build.nvidia.com/mistralai에서 배포 없이 직접 테스트해 보세요.




