
사람의 피드백을 통한 강화 학습(RLHF)은 사람의 가치와 선호도에 부합하는 AI 시스템을 개발하는 데 필수적입니다. RLHF를 통해 ChatGPT, Claude, Nemotron 제품군을 포함한 가장 뛰어난 성능의 LLM이 탁월한 응답을 생성할 수 있습니다.
사람의 피드백을 학습 프로세스에 통합함으로써 RLHF는 모델이 보다 미묘한 행동을 학습하고 사용자의 기대를 더 잘 반영하는 의사 결정을 내릴 수 있도록 지원합니다. 이러한 접근 방식은 AI가 생성하는 응답의 품질을 향상시키고 AI 애플리케이션에 대한 신뢰와 안정성을 높여줍니다.
AI 커뮤니티가 모델을 구축하고 커스터마이징하기 위해 RLHF를 쉽게 채택할 수 있도록 NVIDIA는 LLM에서 생성된 응답에 점수를 매기는 최첨단 리워드 모델인 Llama 3.1-Nemotron-70B-Reward를 출시했습니다. 이러한 점수는 LLM 응답 품질을 개선하는 데 사용되어 인간과 AI 간의 상호 작용을 더욱 긍정적이고 영향력 있게 만들 수 있습니다.
NVIDIA 연구원들은 이 리워드 모델을 활용하여 Arena Hard 리더보드의 상위 모델 중 하나인 Llama 3.1-Nemotron-70B-Instruct 모델을 훈련시켰습니다.
최고의 리워드 모델
리워드 모델의 능력, 안전성 및 함정을 평가하는 Hugging Face RewardBench 리더보드에서 현재 Llama 3.1-Nemotron-70B-Reward 모델이 1위를 차지하고 있습니다.
이 모델은 전체 리워드 벤치에서 94.1%의 점수를 받았으며, 이는 94%의 확률로 사람의 선호도와 일치하는 응답을 식별할 수 있음을 의미합니다.
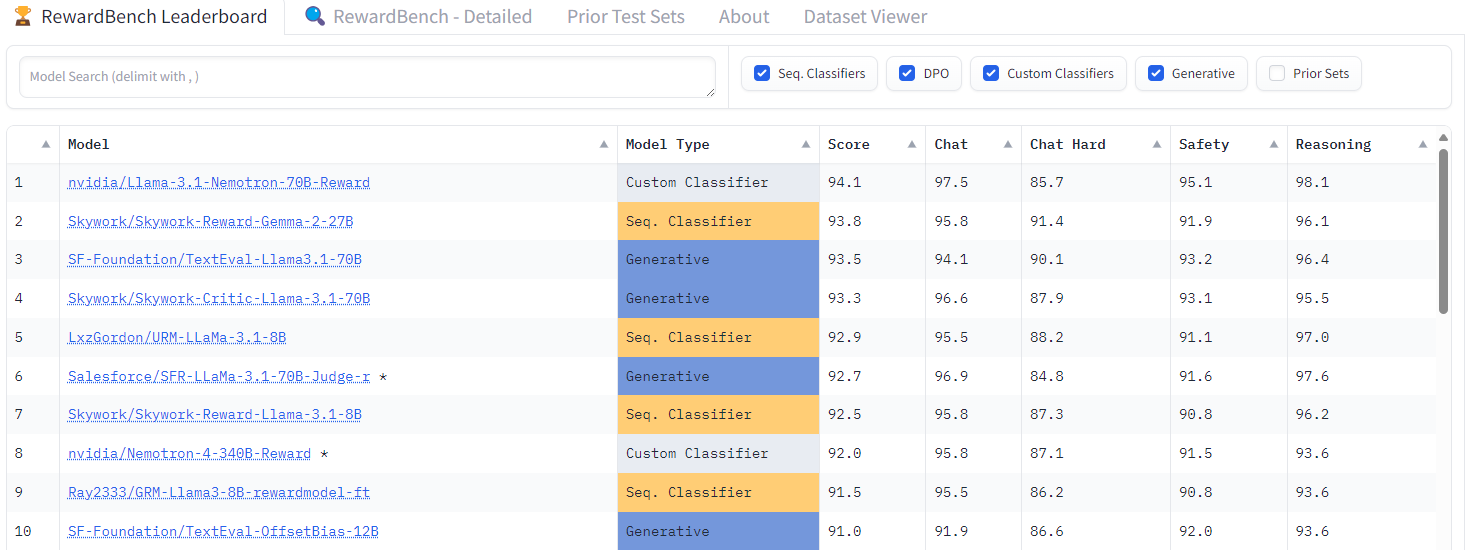
이 모델은 네 가지 카테고리 모두에서 높은 점수를 받았습니다: 채팅, 채팅-하드, 안전 및 추론(Chat, Chat-Hard, Safety, and Reasoning). 특히 안전과 추론에서 각각 95.1%와 98.1%의 정확도를 달성하며 놀라운 성능을 보였습니다. 즉, 이 모델은 잠재적으로 안전하지 않은 응답을 안전하게 거부하고 수학 및 코드와 같은 영역에서 RLHF를 지원할 수 있습니다.
Nemotron-4 340B Reward의 5분의 1 크기에 불과한 이 모델은 뛰어난 정확도와 함께 높은 컴퓨팅 효율성을 제공합니다. 또한 이 모델은 CC-BY-4.0 라이선스가 부여된 HelpSteer2 데이터에 대해서만 학습되므로 엔터프라이즈 사용 환경에 적합합니다.
구현
이 모델을 학습시키기 위해 두 가지 인기 있는 접근 방식을 결합하여 두 가지 장점을 모두 활용했습니다:
HelpSteer2에서 공개한 데이터를 사용하여 두 가지 접근 방식을 모두 학습시켰습니다. 모델 성능에 중요한 기여를 하는 것은 높은 데이터 품질로, 모두를 위한 AI를 발전시키기 위해 세심하게 큐레이션한 후 공개했습니다.
선도적인 거대 언어 모델
훈련된 리워드 모델과 HelpSteer2-Preference 프롬프트를 RLHF 훈련에 사용하면(특히 REINFORCE 알고리즘과 함께) 인스트럭션 튜닝 LLM을 위한 인기 있는 자동 평가 도구인 Arena Hard에서 85점을 받는 모델을 생성할 수 있습니다. 이는 추가적인 테스트 시간 계산이 필요하지 않은 모델 중 Arena Hard 리더보드에서 가장 우수한 모델입니다.
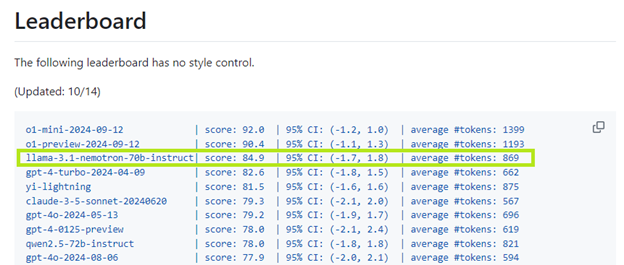
Llama-3.1-Nemotron-70B-Instruct 모델은 Llama-3.1 라이선스와 함께 제공되므로 연구 및 기업에서 이 모델을 애플리케이션에 쉽게 커스터마이징하고 통합할 수 있습니다.
NVIDIA NIM을 통한 간편한 배포
Nemotron Reward 모델은 클라우드, 데이터센터, 워크스테이션 등 어디서나 NVIDIA 가속 인프라 전반에 걸쳐 생성형 AI 모델의 배포를 간소화하고 가속화할 수 있도록 NVIDIA NIM 추론 마이크로서비스로 패키징되어 있습니다.
NIM은 추론 최적화 엔진, 업계 표준 API 및 사전 빌드된 컨테이너를 사용하여 수요에 따라 확장되는 높은 처리량의 AI 추론을 제공합니다.
시작하기
지금 바로 브라우저에서 Llama 3.1-Nemotron-70B-Reward 모델을 체험하거나, 완전히 가속화된 스택에서 실행되는 NVIDIA 호스팅 API 엔드포인트를 통해 대규모로 테스트하고 개념 증명(PoC)을 구축하세요. Llama 3.1-Nemotron-70B-Instruct 모델도 여기에서 액세스할 수 있습니다.
ai.nvidia.com에서 무료 NVIDIA 클라우드 크레딧으로 시작하거나 Hugging Face에서 모델을 다운로드하세요.
모델 학습 방법 및 RLHF에 사용할 수 있는 방법에 대한 자세한 내용은 HelpSteer2-Preference: 기본 설정으로 평가 보완하기를 참조하세요.
이 블로그는 2024년 10월 21일에 업데이트되었습니다.
관련 리소스
GTC 세션: KTO를 통한 더 좋고, 더 저렴하고, 더 빠른 LLM 구현
GTC 세션: 다양성 속의 조화: 거대 언어 모델의 분리된 가치 구현
GTC 세션: 더 빠르고 정확한 비지도 개체 검색을 위한 파인 튜닝 리워드 제공
NGC 컨테이너: Nemotron-4-340B-Reward
NGC 컨테이너: Mistral-Nemo-12B-Instruct
웨비나: AI를 통한 의료 워크플로우 혁신: CLLM에 대한 심층 분석