
NVIDIA가 OptiX 9.0을 출시하면서 ‘코퍼러티브 벡터(cooperative vectors)’라는 새로운 기능이 추가됐습니다. 이 기능은 레이 트레이싱 커널 안에서 AI 워크플로우를 구현할 수 있게 해주며, NVIDIA RTX 텐서 코어를 활용해 셰이딩 중에 하드웨어 가속 행렬 연산과 신경망 계산을 수행합니다. 이를 통해 NVIDIA RTX Neural Shaders나 RTX Neural Texture Compression(NTC) 같은 AI 렌더링 기술을 사용할 수 있게 되어, 실시간 렌더링에서도 영화급의 사실적인 소재 표현이 가능해지고 있습니다.
코퍼러티브 벡터 API는 OptiX뿐 아니라 DirectX, NVAPI, Slang, Vulkan에서도 함께 도입되고 있습니다. 이번 글에서는 모든 API에 공통적으로 적용되는 코퍼러티브 벡터 개념을 살펴보고, OptiX API를 사용한 예제를 통해 이를 어떻게 활용할 수 있는지 알아봅니다.
왜 행렬 연산인가요?
다층 퍼셉트론(MLP)은 많은 신경망 알고리즘의 기본 구성 요소입니다. 연구에 따르면, MLP는 학습한 효과를 매우 정밀하게 재현할 수 있습니다. 실시간으로 동작할 수 있을 만큼 작더라도, 물리 기반 셰이딩 같은 복잡한 효과를 다룰 수 있으며, 기존 셰이딩 네트워크보다 더 빠르고 메모리 사용도 적을 수 있습니다..
MLP는 일반적으로 입력 벡터, 여러 개의 완전 연결 레이어, 그리고 출력 벡터로 구성됩니다. 각 레이어의 벡터 크기는 반드시 같을 필요는 없습니다.

MLP의 각 계층이 추론을 수행할 때는 두 가지 단계가 있습니다. 먼저 이전 계층의 값을 가중치와 편향을 적용해 선형 결합한 다음, 선택적으로 비선형 활성화 함수를 적용합니다. 이 가중치와 편향을 적용한 선형 결합은 결국 행렬-벡터 곱셈에 편향 벡터를 더하는 형태, 즉 어파인 변환(affine transform)으로 볼 수 있습니다.
두 개의 어파인 변환을 연속해서 적용하면 결과도 여전히 어파인 변환이기 때문에, 만약 각 계층이 이 선형 변환만 수행한다면 전체 MLP는 단 하나의 어파인 변환으로 축약될 수 있습니다. 하지만 MLP는 각 계층의 어파인 결과에 비선형 활성화를 적용하기 때문에 훨씬 더 복잡하고 표현력이 뛰어납니다.
완전 연결 MLP에서는 각 뉴런이 이전 계층의 모든 뉴런 값을 입력으로 받아 계산합니다. 이는 그림 1에서 볼 수 있으며, 한 계층의 전체 계산 과정을 도식화한 예는 그림 2에 나와 있습니다.

왜 코퍼레이티브 벡터일까요?
코퍼러티브 벡터의 주요 목표 중 하나는 NVIDIA 텐서 코어를 활용해 행렬 연산을 가속하는 것입니다. 일반적으로 CUDA의 SIMT(Single Instruction, Multiple Threads) 프로그래밍 모델은 전체 워프(warp)의 스레드가 활성화돼 있어야 텐서 코어를 사용할 수 있습니다. 하지만 레이 트레이싱 프로그래밍 모델에서는 각 스레드가 독립적으로 처리되기 때문에 워프 전체가 활성화된다는 보장이 없습니다. 또한, 텐서 코어는 기본적으로 행렬-행렬 곱셈에 최적화돼 있지만, 레이 트레이싱의 각 스레드는 보통 벡터-행렬 곱셈만 필요로 해 텐서 코어의 성능을 제대로 활용하지 못하는 문제가 생깁니다.
게다가 CUDA API는 특정 하드웨어 아키텍처를 대상으로 코드를 작성해야 하며, 아키텍처가 바뀔 때마다 호환성을 보장받기 어렵다는 점도 제약입니다. CUDA 기반의 멀티스레드 행렬 곱셈 접근 방식에 대해 더 알고 싶다면, Matrix Multiplication Background User’s Guide를 참고하면 됩니다.
이러한 한계를 해결하기 위해 코퍼러티브 벡터는 다음과 같은 기능을 제공하는 API를 도입했습니다:
- 일부 스레드가 비활성화된 워프에서도 행렬 연산 수행 가능
- 다양한 아키텍처 간 전방 및 후방 호환성 제공
- 한 스레드에서 벡터 데이터를 지정하되, 텐서 코어를 효율적으로 활용하도록 연산을 재매핑
코퍼러티브 벡터는 워프 내에서 데이터나 실행 경로가 갈라지는 경우도 처리할 수 있지만, 이때는 성능이 다소 떨어질 수 있습니다. 가장 좋은 성능을 내려면 워프 내 모든 스레드가 동일한 MLP 가중치를 사용하고, 워프가 완전히 채워진 상태여야 합니다. 셰이더 실행 재정렬(Shader Execution Reordering, SER)을 활용하면 이러한 조건을 만족시키기 쉬워집니다.
MLP 계산은 기본적으로 연속적인 벡터-행렬 곱셈으로 이뤄지는데, 워프 내 모든 스레드가 동일한 MLP를 나란히 평가할 때, 코퍼러티브 벡터 API는 이 연산들을 하나의 워프 단위 어파인 연산으로 묶어 행렬-행렬 곱셈에 편향 벡터를 더하는 방식으로 처리할 수 있습니다. 바로 이 점이 ‘코퍼러티브(cooperative)’의 의미입니다 — 여러 스레드가 협력해 개별 벡터-행렬 연산들을 하나의 행렬-행렬 연산으로 통합하는 거죠.
출력 매트릭스 = 입력 매트릭스 × 가중치 매트릭스 + 바이어스 매트릭스
outputMatrix = inputMatrix × weightsMatrix + biasMatrix
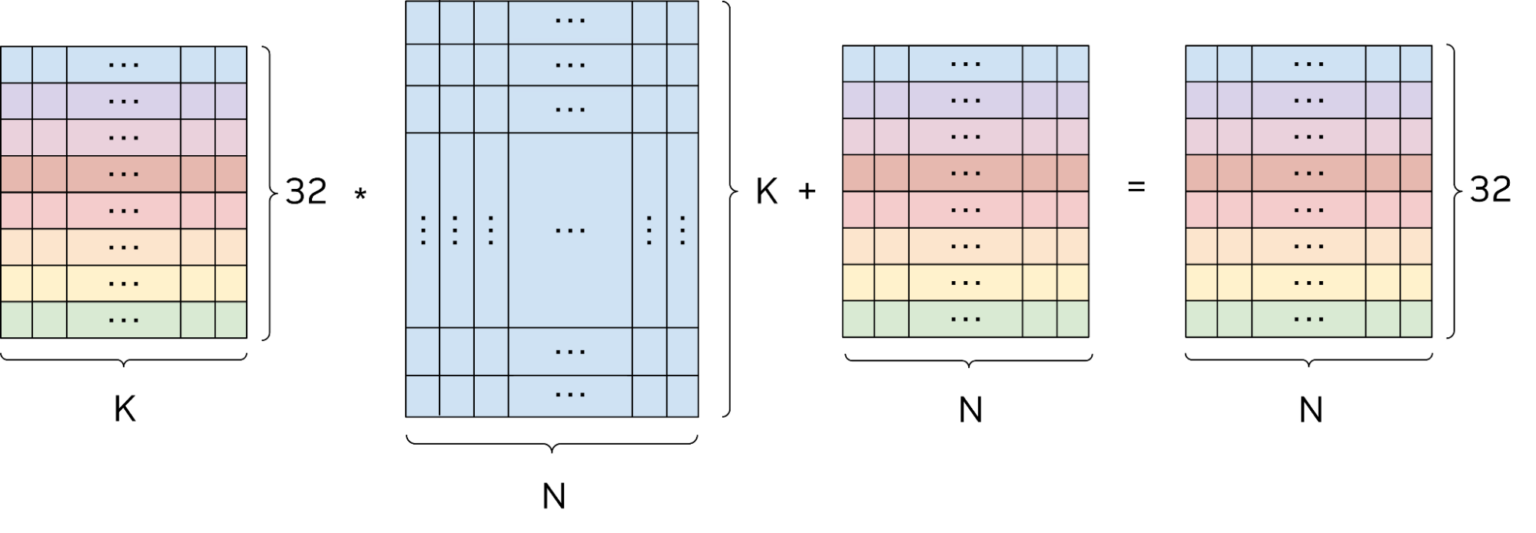
여기서 가중치 행렬을 제외한 모든 행렬은 32행이며 입력, 출력 및 바이어스 행렬의 각 행은 별도의 스레드에 대한 데이터를 나타냅니다.
OptiX에서 협동 벡터 사용하기
코퍼러티브 벡터는 기본적으로 배열 클래스와 유사한 불투명한 벡터 타입으로, 길이에 제한 없이 자유롭게 설정할 수 있습니다. OptiX에서는 이 코퍼러티브 벡터를 OptixCoopVec이라는 이름으로 구현해 제공합니다. OptiX에서의 코퍼러티브 벡터는 MLP나 소형 신경망의 연산을 가속하는 데 특화된, 제한된 연산 집합만을 지원합니다.
코퍼러티브 벡터 API에서는 벡터-행렬 곱셈과 편향 적용을 optixCoopVecMatMul 함수로 처리하는데, 이 함수가 각 계층의 어파인 연산을 담당합니다. 다양한 계층에서 서로 다른 활성화 함수를 사용하는 경우가 많기 때문에, 활성화는 이 연산 이후 별도로 적용합니다. 활성화 함수는 코퍼러티브 벡터 API가 제공하는 다양한 벡터 함수들을 조합해 구성할 수 있습니다.
출력 벡터 = 입력 벡터 × 행렬 + 바이어스
outputVector = inputVector × matrix + bias

코퍼러티브 벡터는 모든 RTX 장치와 일부 서버급 GPU에서 OptiX를 통해 지원됩니다. 해당 기능의 지원 여부는 optixDeviceContextGetProperty 함수에 OPTIX_DEVICE_PROPERTY_COOP_VEC 속성을 전달해 확인할 수 있습니다. 코퍼러티브 벡터는 지원되지 않는 장치에서는 대체 방식 없이 오류가 발생하므로, 사용 전 반드시 지원 여부를 확인해야 합니다.
구현 예제
이 섹션에서는 OptiX 셰이더에서 추론, 즉 MLP 계층 평가를 수행할 때 사용하는 코퍼러티브 벡터 API를 살펴봅니다. 여기서 다룰 예제는 OptiX SDK에 포함된 optixNeuralTexture 샘플을 기반으로 합니다. 이 샘플은 NTC SDK를 사용하며, NTC SDK는 텍스처를 학습(압축)하고, 가중치와 편향을 지정된 파일 형식으로 저장하며, 다양한 셰이딩 언어 환경에서 추론(압축 해제)을 시연합니다. 사용자는 NTC SDK를 활용해 자신만의 텍스처를 압축하고, 이를 optixNeuralTexture를 통해 확인할 수 있습니다.
코퍼러티브 벡터를 사용하는 코드는 C++ 템플릿을 광범위하게 활용합니다. 템플릿은 정적인 배열 크기와 데이터 타입을 컴파일 타임에 명확히 지정해 성능이 뛰어난 코드를 생성하도록 도와줍니다. 자주 사용하는 타입들은 미리 정의해두면 코드 가독성을 높일 수 있습니다.
using T_OUT = OptixCoopVec<float, 16 /*output channels*/>;
...
T_OUT texel = inferTexel<T_OUT> (
latents, weights, x, y, ... );
이 방식을 사용하면 OptixCoopVec<>와 같은 템플릿 타입 대신 T_OUT과 같은 축약형 타입을 활용할 수 있습니다.evalMLP 함수는 화면 상의 특정 픽셀에 대해 전체 MLP를 평가하는 역할을 수행합니다. 의사 코드 기준으로, 해당 함수는 먼저 MLP에 필요한 입력을 구성한 뒤, 각 레이어를 순차적으로 평가하고, 마지막 레이어의 출력을 반환합니다.
template <class T_OUT>
evalMLP( T_OUT& outLayer, latents, mlpWeights, x, y )
{
using T_IN = OptixCoopVec<half, 48 /* input vec size */ >;
using T_HID = OptixCoopVec<half, 64 /* hidden layer size */ >;
T_IN networkInputs = prepareNetworkInputs_FP16<T_IN>(x, y, latents);
T_HID hiddenOut1 = evalLayer<T_IN, T_HID>(
networkInputs, mlpWeights, 0, scaleBiasOffset, hiddenOut1);
T_HID hiddenOut2 = evalLayer<T_HID, T_HID>(
hiddenOut1, mlpWeights, weightOffset1, scaleBiasOffset, hiddenOut2);
T_HID hiddenOut3 = evalLayer<T_HID, T_HID>(
hiddenOut2, mlpWeights, weightOffset2, scaleBiasOffset, hiddenOut3 );
outLayer = evalLayer<T_HID, T_OUT>(
hiddenOut3, mlpWeights, weightOffset3, scaleBiasOffset, outLayer);
return true;
}
각 레이어 평가의 출력이 다음 레이어 평가의 입력이 되는 방식에 주목하세요. 레이어 평가를 자세히 살펴보세요:
template <class T_IN, class T_OUT> evalLayer(
T_IN& inputArray,
uint8_t* weights,
uint32_t weightsOffsetInBytes,
uint32_t& biasOffsetInBytes,
T_OUT& outputArray )
{
outputArray = optixCoopVecMatMul <
T_OUT,
T_IN,
OPTIX_COOP_VEC_ELEM_TYPE_FLOAT8_E4M3, // inputInterpretation
MAT_LAYOUT, // matrixLayout
false, // transpose
T_OUT::size, // N
T_IN::size, // K
OPTIX_COOP_VEC_ELEM_TYPE_FLOAT8_E4M3, // matrixElementType
OPTIX_COOP_VEC_ELEM_TYPE_FLOAT16 // biasElementType
>(
inputArray, // inputVector
weights, // matrix base ptr
weightsOffsetInBytes, // matrix offset
weights, // bias base ptr, same as weights
biasOffsetInBytes // bias offset
);
// increment offset to the next layer
biasOffsetInBytes += T_OUT::size * sizeof( T_OUT::value_type );
outputArray = activate<T_OUT>( outputArray );
}
단일 계층 평가 함수는 사실상 optixCoopVecMatMul을 감싸는 간단한 래퍼에 가깝습니다. 행렬 곱셈이 끝나면 다음 계층을 준비하기 위해 편향 벡터의 오프셋 값을 업데이트합니다. 이때 편향 오프셋은 참조로 전달되기 때문에 함수 내부에서 바로 갱신됩니다. 그런 다음 해당 계층에 활성화 함수를 적용합니다.
코드 예제를 자세히 살펴보면, evalLayer 함수를 여러 번 호출할 때마다 동일한 가중치(base) 포인터를 반복해서 전달하고 있다는 점을 눈치채셨을 수도 있습니다. 흥미로운 부분은, 이 포인터가 가중치와 편향 양쪽 데이터를 모두 참조하는 데 사용된다는 점입니다. 각 계층에서 필요한 데이터를 가져올 때는, 이 base 포인터에 상수 오프셋(weightsOffsetInBytes, biasOffsetInBytes)을 더하는 방식으로 접근합니다.
이런 방식으로 코드를 작성하는 데는 두 가지 이유가 있습니다. 첫째, NTC 포맷으로 저장된 파일을 읽을 때 API는 모든 가중치 행렬과 편향 벡터를 하나의 연속된 메모리 블록에 담아서 제공합니다. 그래서 각 계층의 데이터를 단순한 산술 연산으로 순차적으로 접근할 수 있게 됩니다. 두 번째 이유는, 코퍼레이티브 벡터 API가 동일한 가중치 베이스 포인터를 반복해서 사용할 경우 optixCoopVecMatMul을 연속으로 호출하는 상황에서 최적화를 수행하기 때문입니다. 컴파일러는 base 포인터가 재사용되는 것을 감지하고(상수 오프셋이 달라도), 계층 간에 불필요한 셔플(shuffle) 및 언셔플(unshuffle) 연산이 일어나지 않도록 프로그램을 자동으로 최적화합니다.
마지막으로, 활성화 함수의 구현도 함께 살펴보겠습니다:
template<class T_IN>
VecT activate(const T_IN& x, bool scaleActivation=true)
{
T_IN tmp = optixCoopVecFFMA( x, T_IN( 1.0f/3.0f ), T_IN( 0.5f ) );
tmp = optixCoopVecMin( optixCoopVecMax( tmp, 0.0f ), 1.f ); // clamp
T_IN result = optixCoopVecMin( x, 3.0f );
result = optixCoopVecMul( result, tmp );
if( scaleActivation )
result = optixCoopVecFFMA( result, T_IN(invStep), T_IN(bias) );
return result;
}
MLP의 활성화 함수는 각 계층의 출력 벡터 요소마다 비선형 매핑을 적용하므로, 앞서 소개한 코드에서 호출되는 코퍼러티브 벡터 함수들은 모두 벡터 연산이며, 행렬 연산은 아닙니다. 활성화는 일반적으로 계층 가중치 행렬을 적용하는 것에 비해 훨씬 작고 계산 비용이 낮은 연산입니다. 코퍼러티브 벡터에서 사용할 수 있는 내장 벡터 함수는 제한적이지만, MLP에서 흔히 쓰이는 활성화 함수들을 커버할 수 있는 수준으로 구성돼 있습니다. 예를 들어 tanh, log2, exp2, min, max, ffma 등 다양한 연산이 기본으로 제공됩니다.
일부 함수는 스칼라 매개변수를 받을 수 있는 변형 버전도 제공하지만, 모든 함수가 그런 것은 아닙니다. 그래서 경우에 따라 스칼라 값을 상수 벡터로 변환해 전달해야 할 때도 있습니다. 예를 들어, T_IN(0.5f)처럼 OptixCoopVec 생성자를 사용해 모든 요소가 0.5인 벡터를 만들어 optixCoopVecFFMA에 넘긴 방식이 그 예입니다. 이 특정 활성화 함수는 NTC SDK에서 제공하는 방식이지만, 자신만의 네트워크를 설계할 때는 훨씬 단순하게 구성할 수도 있습니다. 예를 들어 잘 알려진 ReLU 활성화를 흉내 내고 싶다면, optixCoopVecMax만 호출해도 충분합니다.
뉴럴 그래픽
코퍼러티브 벡터는 RTX 뉴럴 셰이더와 RTX Neural Texture Compression (NTC) 구현에 사용되며, 이 두 기술은 NVIDIA RTX Kit의 일부로 제공됩니다. RTX Kit은 이러한 기술들을 보다 쉽게 사용하고 통합할 수 있도록 구성된 오픈 소스 레포지토리 모음입니다. RTX Kit을 빠르게 시작하고 싶다면, 각 레포지토리에 대한 링크와 참고 자료가 정리된 “Get Started with Neural Rendering Using NVIDIA RTX Kit” 문서를 확인해보세요.

그림 5에 나오는 드래곤 모델은 GeForce RTX 5080 GPU의 16GB 비디오 메모리에 적재하기 위해 텍스처 압축이 필수였습니다. 이 드래곤 하나만 해도 100개 이상의 8K UDIM 텍스처를 가지고 있으며, 각 텍스처는 5개의 레이어로 구성되어 있습니다. 텍스처를 파일에서 메모리로 풀어서 사용할 경우, VRAM 32GB 이상을 차지하게 되며, 이는 5080 GPU의 용량을 두 배 넘게 초과합니다.
하지만 NTC(Neural Texture Compression)를 사용하면 텍스처 메모리 사용량이 3GB 이하로 줄어듭니다. 이는 BC 압축 텍스처보다도 약 두 배나 작게 줄어든 수치입니다. 덕분에 나머지 씬의 텍스처는 물론, 지오메트리, 애니메이션, BVH, 셰이더까지 충분히 메모리에 적재할 수 있으며, 이렇게 거대한 프로덕션 규모의 씬도 단일 5080 GPU에서 실시간 렌더링이 가능해집니다.
뉴럴 셰이더는 RTX Neural Shading SDK를 통해 확인할 수 있으며, 이 SDK는 사용자가 직접 뉴럴 셰이딩 네트워크를 학습시키고, 이를 그래픽 렌더링 파이프라인에서 추론에 활용하는 방법을 익힐 수 있도록 예제와 함께 제공됩니다. 코퍼러티브 벡터는 이러한 실시간 뉴럴 표현 모델(Real-Time Neural Appearance Models)을 구현하는 데 유용한 수단이 될 수 있습니다.
성능 고려 사항
최상의 성능을 위해 다음 사항들을 고려해야 합니다:
- 셔플 및 언셔플 처리: Tensor Core를 활용하려면
optixCoopVecMatMul호출 전 워프 내 데이터가 셔플되고, 이후에는 다시 언셔플됩니다. 이때 두 함수 호출 사이에서 지원되는 벡터 연산만 사용할 경우, 언셔플과 셔플 단계를 생략할 수 있어 성능이 향상됩니다. - 풀 워프 사용: 전체 워프를 사용할 때 가장 좋은 성능을 얻을 수 있습니다. SER(Single Execution Region)을 활용해 스레드를 병합(coalesce)하고, 동적 조건문 안에서
optixCoopVecMatMul을 호출하는 것은 피하세요. - 메모리 레이아웃: 가중치 행렬의 메모리 배치는 성능에 큰 영향을 미칩니다. OptiX는 추론과 학습을 위한 최적의 메모리 레이아웃을 지원하므로, 이를 사용하는 것이 좋습니다. 행렬을 최적 레이아웃으로 변환하려면
optixCoopVecMatrixConvert를 사용하세요.
OptiX 협력 벡터를 활용한 교육
OptiX는 코퍼레이티브 벡터를 활용한 학습도 지원하며, 여기에는 순전파와 역전파 과정이 모두 포함됩니다. 자세한 내용은 OptiX Programming Guide를 참고하세요. 특히 디바이스 측에서 제공되는 두 가지 내장 함수인 optixCoopVecReduceSumAccumulate와 optixCoopVecOuterProductAccumulate는 각각 바이어스 벡터와 가중치 행렬에 대한 손실 값 누적에 활용됩니다.
시작하기
코퍼레이티브 벡터는 NVIDIA OptiX에서 제공하는 데이터 타입 및 API로, OptiX 셰이더 프로그램 내에서 고성능 벡터 및 행렬 연산을 수행할 수 있도록 설계되었습니다. 이러한 벡터 및 행렬 연산은 MLP(다층 퍼셉트론) 같은 대표적인 머신러닝 알고리즘의 핵심이며, cooperative vector는 이를 보다 효율적으로 구현할 수 있게 해줍니다. 기존에는 Tensor Core를 활용하려면 워프 내 스레드 간 동기화와 명시적인 협업이 필요했지만, 코퍼레이티브 벡터를 사용하면 이러한 복잡한 동기화 없이 단일 스레드 기반의 간단한 코드 스타일로 고성능의 행렬-벡터 곱 연산을 수행할 수 있습니다.
코퍼레이티브 벡터는 NVIDIA OptiX SDK 9.0부터 사용 가능하며, 2025년 4월 말 Agility SDK 프리뷰를 통해 DirectX에도 도입되고 있습니다. Vulkan과 Slang에서도 지원이 예정되어 있어, 하드웨어 가속 레이 트레이싱이 가능한 거의 모든 환경에서 활용할 수 있습니다. API에 대한 자세한 설명은 온라인과 SDK에 포함된 PDF 문서 형태의 OptiX Programming Guide에서 확인할 수 있습니다.
OptiX SDK에는 RTX Neural Texture Compression의 추론 예제로 optixNeuralTexture 샘플이 포함되어 있습니다. 이 예제에서는 코퍼레이티브 벡터를 활용해 셰이딩 과정 중 신경망 기반 압축 텍스처를 실시간으로 복원하며, 이는 기존 BC5나 BC6 압축 포맷 대비 약 20배, 그리고 압축되지 않은 텍스처에 비해 최대 80배의 메모리 사용량 절감을 가능하게 합니다.
앞으로 코퍼레이티브 벡터를 활용한 새로운 활용 사례들이 등장할 것으로 기대됩니다. 더 많은 정보를 얻고 본인의 경험을 공유하고 싶다면 NVIDIA 개발자 포럼의 OptiX 섹션에서 커뮤니티에 참여해 보세요.
관련 리소스
- GTC 세션: 실시간 및 프로덕션 렌더링을 위한 레이 트레이싱의 미래
- GTC 세션: 사실적인 합성 데이터를 생성하여 NVIDIA Omniverse Replicator로 AI 모델을 강화하기
- GTC 세션: GPU 공유 컨테이너를 사용한 범용 NIM 가속화(Lablup 발표)
- SDK: OptiX
- SDK: Neural VDB
- SDK: RTX NTC-신경망 텍스트 압축