JSON은 시스템 간에 상호 운용 가능한 텍스트 기반 정보에 널리 채택되는 형식으로, 특히 웹 애플리케이션 및 거대 언어 모델(LLM)에 자주 사용됩니다. JSON 형식은 사람이 읽을 수 있지만, 데이터 사이언스 및 데이터 엔지니어링 도구로 처리하기에는 복잡합니다.
JSON 데이터는 데이터 세트의 여러 레코드를 나타내기 위해 줄 바꿈으로 구분된 JSON Lines(NDJSON이라고도 함)의 형태를 취하는 경우가 많습니다. JSON Lines 데이터를 DataFrame으로 읽어 들이는 것은 데이터 처리에서 흔히 볼 수 있는 첫 단계입니다.
이 게시물에서는 다음 라이브러리를 사용하여 JSON Lines 데이터를 DataFrame으로 변환하는 Python API의 성능과 기능을 비교합니다.
- pandas
- DuckDB
- pyarrow
- RAPIDS cuDF pandas 가속기 모드
특히 복잡한 스키마를 가진 데이터에 대해 cudf.pandas의 JSON 리더를 사용하여 우수한 확장성과 높은 데이터 처리량을 보여줍니다. 또한 Apache Spark와 호환성을 높이고, Python 사용자가 따옴표 정규화, 잘못된 레코드, 혼합된 유형 및 기타 JSON 이상 현상을 처리할 수 있도록 지원하는 cuDF의 여러 JSON 리더 옵션 세트도 함께 살펴봅니다.
JSON 파싱 vs JSON 읽기
JSON 데이터 처리와 관련하여 파싱(parsing)과 읽기(reading)를 구별하는 것이 중요합니다.
JSON parser
simdjson과 같은 JSON parser는 문자 데이터의 버퍼를 토큰의 벡터로 변환합니다. 이러한 토큰은 필드 이름, 값, 배열 시작/끝, 맵 시작/끝 등을 포함하여 JSON 데이터의 논리적 구성 요소를 나타냅니다. 파싱은 JSON 데이터에서 정보를 추출하는 첫 번째 핵심 단계이며, 높은 파싱 처리량을 달성하기 위한 중요한 연구가 진행되어 왔습니다.
데이터 처리 파이프라인에서 JSON Lines의 정보를 사용하려면 토큰을 Dataframe 또는 Apache Arrow와 같은 열 형식으로 변환해야 하는 경우가 많습니다.
JSON readers
pandas.read_json과 같은 JSON 리더는 입력 문자 데이터를 열과 행으로 구성된 Dataframe으로 변환합니다. 리더 프로세스는 파싱 단계로 시작하여 레코드 경계를 감지하고, 최상위 열과 중첩된 구조체 또는 리스트 하위 열을 관리하며, 누락 필드나 null 필드를 처리하고, 데이터 유형을 추론하는 등의 작업을 수행합니다.
JSON 리더는 비정형 문자 데이터를 정형화된 Dataframe으로 변환하여, JSON 데이터를 다운스트림 애플리케이션과 호환되도록 합니다.
JSON Lines reader 벤치마킹
JSON Lines는 데이터를 표현하기 위한 유연한 형식입니다. JSON 데이터의 몇 가지 중요한 속성은 다음과 같습니다.
- 파일당 레코드 수
- 최상위 열 개수
- 각 열의 구조체 또는 리스트 중첩의 깊이
- 값의 데이터 유형
- 문자열 길이 분포
- 누락된 키 비율(Fraction)
이 연구에서는 레코드 수를 200K에서 고정하고, 열 수를 2개에서 200개로 만들어 광범위하고 복잡한 스키마를 살펴보았습니다. 사용되는 4가지 데이터 유형은 다음과 같습니다.
- 두 개의 하위 요소가 있는
list<int>및list<str> - 단일 하위 요소가 있는
struct<int>및struct<str>
표 1은 list<int>, list<str>, struct<int>, struct<str> 등의 데이터 유형에 대한 처음 두 개의 레코드 중, 첫 두 열을 보여줍니다.
| 데이터 유형 | 레코드 예제 |
list<int> | {"c0":[848377,848377],"c1":[164802,164802],...\n{"c0":[732888,732888],"c1":[817331,817331],... |
list<str> | {"c0":["FJéBCCBJD","FJéBCCBJD"],"c1":["CHJGGGGBé","CHJGGGGBé"],...\n{"c0":["DFéGHFéFD","DFéGHFéFD"],"c1":["FDFJJCJCD","FDFJJCJCD"],... |
struct<int> | {"c0":{"c0":361398},"c1":{"c0":772836},...\n{"c0":{"c0":57414},"c1":{"c0":619350},... |
struct<str> | {"c0":{"c0":"FBJGGCFGF"},"c1":{"c0":"ïâFFéâJéJ"},...\n{"c0":{"c0":"éJFHDHGGC"},"c1":{"c0":"FDâBBCCBJ"},... |
표 1은 list<int>, list<str>, struct<int>, struct<str> 등의 데이터 유형에 대한 처음 두 개의 레코드 중, 첫 두 열을 보여줍니다.
성능 통계는 cuDF의 25.02 브랜치와 다음 라이브러리 버전인 pandas 2.2.3, duckdb 1.1.3, pyarrow 17.0.0으로 수집되었습니다. 실행 하드웨어는 NVIDIA H100 Tensor 코어 80GB HBM3 GPU와 2TiB RAM이 장착된 Intel Xeon Platinum 8480CL CPU를 사용했습니다. 초기화 오버헤드를 방지하고 입력 파일 데이터가 OS 페이지 캐시에 존재하도록 하기 위해 3번 반복 중 3번째에서 타이밍이 수집되었습니다.
코드 변경이 없는 cudf.pandas 외에도, libcudf CUDA C++ 연산 코어를 위한 Python API인 pylibcudf의 성능 데이터도 수집했습니다. pylibcudf 실행은 RAPIDS Memory Manager(RMM)를 통해 CUDA 비동기 메모리 리소스를 사용했습니다. 처리량 값은 JSONL 입력 파일 크기와 세 번째 반복의 리더 런타임을 사용하여 계산되었습니다.
JSON Lines 리더를 호출하기 위한 여러 Python 라이브러리의 몇 가지 예시가 있습니다.
# pandas and cudf.pandas import pandas as pd df = pd.read_json(file_path, lines=True) # DuckDB import duckdb df = duckdb.read_json(file_path, format='newline_delimited') # pyarrow import pyarrow.json as paj table = paj.read_json(file_path) # pylibcudf import pylibcudf as plc s = plc.io.types.SourceInfo([file_path]) opt = plc.io.json.JsonReaderOptions.builder(s).lines(True).build() df = plc.io.json.read_json(opt)JSON Lines 리더 성능
전반적으로 Python에서 사용할 수 있는 JSON 리더의 성능 특성은 광범위했으며, 전체 런타임은 1.5초에서 약 5분까지 다양합니다.
표 2는 총 파일 크기 8.2GB의 28개 입력 파일을 처리할 때 7개의 JSON 리더 구성의 타이밍 데이터의 합계를 보여줍니다.
- JSON 읽기에 cudf.pandas를 사용하면 기본 엔진을 사용하는 pandas에 비해 약 133배, pyarrow 엔진을 사용하는 pandas에 비해 60배 속도가 향상됩니다.
- DuckDB 및 pyarrow도 우수한 성능을 보였는데, DuckDB의 경우 총 60초 정도, 블록 크기 조정이 있는 pyarrow의 경우 6.9초가 걸립니다.
- 가장 빠른 시간은 1.5초의 pylibcudf로, block_size 조정을 사용하면 pyarrow 대비 약 4.6배 속도 향상을 보입니다.
| 리더 라벨 | 벤치마크 런타임 (초) | 코멘트 |
| cudf.pandas | 2.1 | Using -m cudf.pandas from the command line |
| pylibcudf | 1.5 | |
| pandas | 281 | |
| pandas-pa | 130 | Using the pyarrow engine |
| DuckDB | 62.9 | |
| pyarrow | 15.2 | |
| pyarrow-20MB | 6.9 | Using a 20 MB block_size value |
표 2에는 입력 열 수 2, 5, 10, 20, 50, 100, 200과 데이터 유형 list<int>, list<str>, struct<int>, struct<str>가 포함되어 있습니다.
데이터 유형과 열 수별로 데이터를 살펴본 결과, JSON 리더 성능이 입력 데이터 세부 정보와 데이터 처리 라이브러리에 따라 광범위하게 달라지는 것을 알 수 있습니다. CPU 기반 라이브러리의 경우 40MB/s에서 3GB/s까지, GPU 기반 cuDF의 경우 2~6GB/s까지 다양한 성능을 보였습니다.
그림 1은 200K 행과 2~200개 열의 입력 크기를 기반으로 한 데이터 처리 처리량을 보여줍니다. 입력 데이터 크기는 약 10MB에서 1.5GB까지 다양합니다.
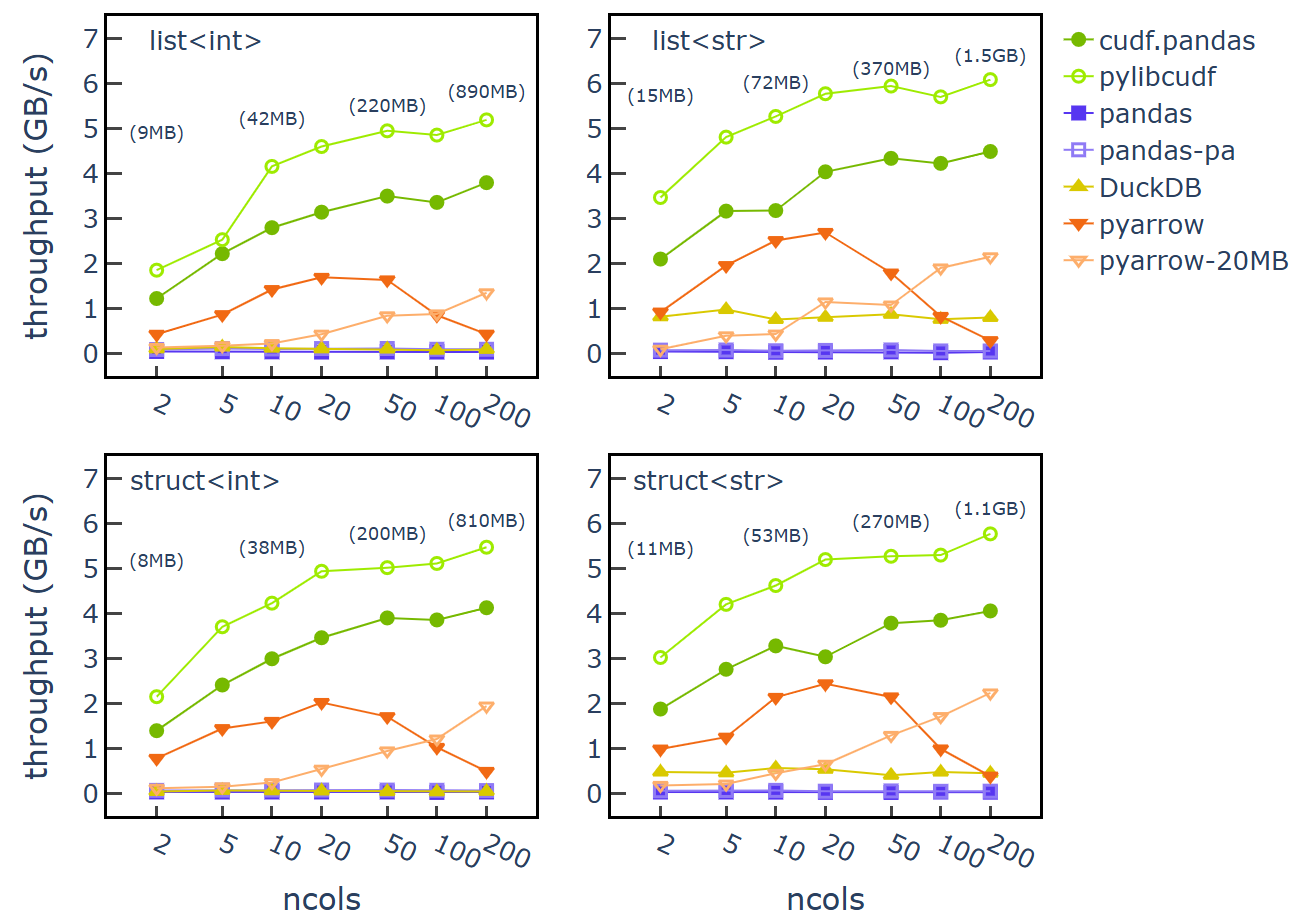
그림 1의 각 하위 도표는 입력 열의 데이터 유형에 해당합니다. 파일 크기 주석은 x축에 표시됩니다.
cudf.pandas read_json은 2–5GB/s의 처리량이 관찰되었으며, 열 수와 입력 데이터 크기가 늘어날수록 증가했습니다. 또한 열 데이터 유형이 처리량에 큰 영향을 미치지 않는 것도 관찰되었습니다. pylibcudf 라이브러리는 Python 및 pandas 시맨틱 오버헤드가 낮아 cuDF-python보다 약 1~2GB/s 높은 처리량을 보여줍니다.
pandas read_json의 경우 기본 UltraJSON 엔진(“pandas-uj”로 레이블이 지정됨)에 대해 약 40~50MB/s 처리량을 측정했습니다. pyarrow 엔진(engine="pyarrow")을 사용하면 더 빠른 파싱(pandas-pa)으로 인해 최대 70–100MB/s까지 처리량이 증가했습니다. pandas JSON 리더의 성능은 표의 각 요소에 대해 Python 리스트와 딕셔너리 개체를 만들어야 한다는 점에서 제한된 것으로 보입니다.
DuckDB read_json의 경우 list<str> 및 struct<str> 처리에 대해 약 0.5~1GB/s의 처리량을 보였으며, list<int> 및 struct<int>에서는 더 낮은 0.2GB/s 미만의 처리량을 나타냈습니다. 데이터 처리량은 열 개수 범위 내에서 일정하게 유지되었습니다.
pyarrow read_json의 경우, 5~20개의 열에 대해 최대 2–3GB/s의 데이터 처리량을 측정했으며, 열 수가 50개 이상으로 늘어나면 처리량 값이 낮아졌습니다. 데이터 유형은 열 개수나 입력 데이터 크기에 비해 리더 성능에 미치는 영향이 상대적으로 적었습니다. 열 수가 200개이고 레코드 크기가 행당 최대 5KB인 경우, 처리량은 약 0.6GB/s로 감소했습니다.
pyarrow block_size 리더 옵션을 20MB(pyarrow-20MB)로 높이면 열 수가 100개 이상인 경우 처리량이 증가했지만, 열 수가 50개 이하인 경우 처리량이 저하되었습니다.종합적으로 살펴보면, DuckDB는 주로 데이터 유형에 따라 처리량 가변성을 보였던 반면 cuDF 및 pyarrow는 주로 열 수와 입력 데이터 크기로 인한 처리량 가변성을 보였습니다. GPU 기반 cudf.pandas 및 pylibcudf는 복잡한 리스트 및 구조체 스키마, 특히 50MB 이상의 입력 데이터 크기에 대해 가장 높은 데이터 처리 처리량을 보였습니다.
JSON Lines 리더 옵션
JSON 형식의 텍스트 기반 특성을 감안할 때, JSON 데이터에는 유효하지 않은 JSON 레코드가 발생하거나 dataframe에 잘 매핑되지 않는 이상 현상이 포함되는 경우가 많습니다. 작은따옴표로 묶인 필드, 잘리거나 손상된 레코드, 구조체나 리스트 유형의 혼합 등이 이러한 JSON 이상 현상의 예시입니다. 데이터에 이러한 패턴이 발생하면 파이프라인의 JSON 리더 단계가 중단될 수 있습니다.
이러한 JSON 이상 현상의 몇 가지 예시가 있습니다.
# 'Single quotes'
# field name "a" uses single quotes instead of double quotes
s = '{"a":0}\n{\'a\':0}\n{"a":0}\n'
# ‘Invalid records'
# the second record is invalid
s = '{"a":0}\n{"a"\n{"a":0}\n'
# 'Mixed types'
# column "a" switches between list and map
s = '{"a":[0]}\n{"a":[0]}\n{"a":{"b":0}}\n'cuDF의 고급 JSON 리더 옵션을 활용하려면 cuDF-Python(import cudf) 및 pylibcudf를 워크플로우에 통합하는 것이 좋습니다. 작은따옴표로 묶인 필드 이름이나 문자열 값이 데이터에 나타나면 cuDF는 작은따옴표를 큰따옴표로 정규화할 수 있는 리더 옵션을 제공합니다. cuDF는 Apache Spark에서 기본적으로 활성화된 allowSingleQuotes 옵션과 호환되도록 이 기능을 지원합니다.
데이터에 유효하지 않은 레코드가 있으면 cuDF 및 DuckDB 모두 이러한 레코드를 null로 교체하는 오류 복구 옵션을 제공합니다. 오류 처리가 활성화되면 레코드 파싱 중 오류가 발생할 경우, 해당 행의 모든 열이 null로 표시됩니다.
혼합된 리스트와 구조체 값이 데이터의 동일한 필드 이름과 연결되어 있는 경우, cuDF는 데이터 유형을 문자열로 강제 변환하는 dtype 스키마 재지정 옵션을 제공합니다. DuckDB는 JSON 데이터 유형을 추론함으로써 비슷한 접근 방식을 사용합니다.
혼합된 유형의 경우, pandas 라이브러리는 Python 리스트 및 딕셔너리 개체를 사용하여 입력 데이터를 가장 정확하게 표현하는 접근 방식을 취합니다.
다음은 열 이름 “a”에 대한 dtype 스키마 재설정을 포함하여 리더 옵션을 보여주는 cuDF-Python 및 pylibcudf의 예시입니다. 자세한 내용은 cudf.read_json 및 pylibcudf.io.json.read_json을 참조하세요.
pylibcudf의 경우 JsonReaderOptions 개체는 build 함수 전이나 후에 구성할 수 있습니다.
# cuDF-python
import cudf
df = cudf.read_json(
file_path,
dtype={"a":str},
on_bad_lines='recover',
lines=True,
normalize_single_quotes=True
)
# pylibcudf
import pylibcudf as plc
s = plc.io.types.SourceInfo([file_path])
opt = (
plc.io.json.JsonReaderOptions.builder(s)
.lines(True)
.dtypes([("a",plc.types.DataType(plc.types.TypeId.STRING), [])])
.recovery_mode(plc.io.types.JSONRecoveryMode.RECOVER_WITH_NULL)
.normalize_single_quotes(True)
.build()
)
df = plc.io.json.read_json(opt)표 3은 몇 가지 일반적인 JSON 이상 현상에 대해 Python API를 사용하는 여러 JSON 리더의 동작을 요약합니다. X 표시는 리더 함수가 예외를 발생시켰음을 나타내고, 체크 표시는 라이브러리가 Dataframe을 성공적으로 반환했음을 나타냅니다. 라이브러리의 향후 버전에서 이러한 결과가 변경될 수 있습니다.
| 작은따옴표 | 유효하지 않은 레코드 | 혼합된 유형 | |
| cuDF-Python, pylibcudf | ✔️ 큰따옴표로 정규화 | ✔️ null로 설정 | ✔️ 문자열로 표현 |
| pandas | ❌ 예외 | ❌ 예외 | ✔️ Python 개체로 표현 |
| pandas (engine=”pyarrow“) | ❌ 예외 | ❌ 예외 | ❌ 예외 |
| DuckDB | ❌ 예외 | ✔️ null로 설정 | ✔️ JSON 문자열 유사 유형으로 표현 |
| pyarrow | ❌ 예외 | ❌ 예외 | ❌ 예외 |
cuDF는 Apache Spark 규칙과 호환되는 데 중요한 몇 가지 추가 JSON 리더 옵션을 지원하며, 이제 Python 사용자도 사용할 수 있습니다. 이러한 옵션 중 일부는 다음과 같습니다.
- 숫자 및 문자열에 대한 유효성 검증 규칙
- 사용자 정의 레코드 구분자
- dtype에 제공된 스키마에 의한 열 제거
- NaN 값 사용자 지정
자세한 내용은 json_reader_options에 대한 libcudf C++ API 문서를 참조하세요.
여러 개의 작은 JSON Lines 파일을 효율적으로 처리하기 위한 멀티 소스 읽기 또는 대용량 JSON Lines 파일을 분할하기 위한 바이트 범위 지원에 대한 자세한 내용은 RAPIDS를 사용한 GPU 가속 JSON 데이터 처리를 참조하세요.
요약
RAPIDS cuDF는 Python에서 JSON 데이터를 처리하기 위한 강력하고 유연하며 가속화된 도구를 제공합니다.
24.12 릴리스부터 RAPIDS Accelerator For Apache Spark에서 GPU 가속화 JSON 데이터 처리를 사용할 수 있습니다. 자세한 내용은 GPU로 Apache Spark JSON 처리 가속화를 참조하세요.
자세한 내용은 다음 리소스를 참조하시기 바랍니다.
- cuDF 문서
- /rapidsai/cudf GitHub 저장소
- RAPIDS Docker 컨테이너 (릴리스 및 야간 빌드에 사용 가능)
- 코드 변경 없이 데이터 사이언스 워크플로우 가속화 DLI 과정
- GPU 가속화를 위한 cudf.pandas 프로파일러 마스터
관련 리소스
- DLI 과정: RAPIDS cuDF로 DataFrame 연산 속도 향상
- GTC 세션: Python으로 CUDA 커널을 작성하는 1,001가지 방법
- GTC 세션: 최상의 속도로 비디오 처리 최적화
- SDK: DGL 컨테이너
- SDK: PyTorch Geometric(PyG) 컨테이너
- SDK: RAPIDS