JSON is a popular format for text-based data that allows for interoperability between systems in web applications as well as data management. The format has been in existence since the early 2000s and came from the need for communication between web servers and browsers. The standard JSON format consists of key-value pairs that can include nested objects. JSON has grown in usage for storing web transaction information, and can contain values that could be very large – sometimes over 1 GB per record. At first, parsing and validating JSON is not a task that would be associated with GPU acceleration because the text format has irregularities in size and no default ordering. However, with the usage of JSON in many enterprise data applications, the need for acceleration has grown.
For a Fortune 100 retail company, the JSON format is leveraged to store essential inventory data. The JSON format allows for unstructured data related to product categorization and inventory. The processing of JSON for the clickstream data included large queries processing tens of terabytes of JSON data in a single Spark workload.
GPU acceleration in production at a retailer
The results were noticeable for the retailer when applied to their production workloads running on GPUs. The GPU runtime reduced from 16.7 hours to 3.8 hours, which is a 4x speedup and 80% cost savings on GPUs relative to a comparable CPU cluster in their production environment.
The nodes in the cluster are GCP n1-standard-16 instances with a single NVIDIA T4 GPU attached to each node.

The Spark get_json_object function
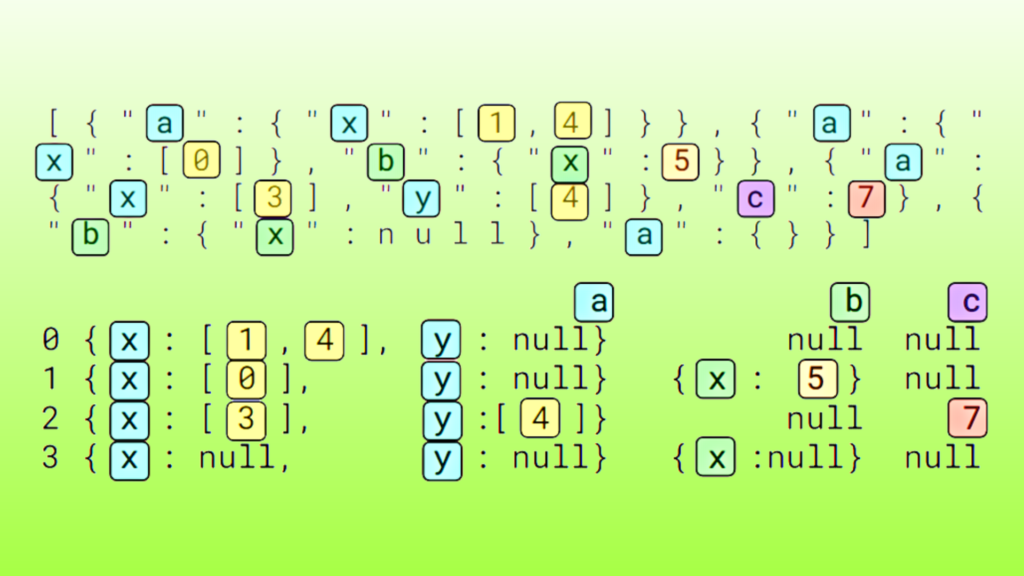
GPU processing for JSON has existed in the RAPIDS Accelerator for Apache Spark since the 22.02 release, but there have been challenges in accelerated processing. In working with the retailer, specific processing of JSON records using Spark’s get_json_object function required parsing JSON on the fly within a SQL query. The format of JSON allows for embedding objects with hierarchy, such as arrays:

The purpose of the get_json_object function is to extract an object from the JSON record string based on the path provided. Here is a simple example SQL query where the get_json_object function is used to extract nested elements:
SELECT get_json_object('[{"a":"b1"}, {"a":"b2"}]', '$[*].a')
["b1","b2"]
In real world use cases, the function will allow for selecting nested objects inside a JSON record that are relevant for additional processing in an ETL pipeline.
The challenge of large strings in JSON
In the retailer workload, with a moderately wide output table, a single SQL query statement could result in the get_json_object function being called up to 50 times. The strings themselves were long, multiple KiB, on average. When you add in the frequency of calls along with the long JSON strings, there could be significant memory pressure put on the GPU when processing the data. This is especially true for the GPUs L1 cache. The initial implementation on the GPU would parallelize processing on the GPU per record to accelerate processing with a record-per-thread default. This resulted in the L1 cache trying to hold multiple records and we ended up thrashing the cache. Additionally, if threads diverge within a thread block, the processing time slows down because the thread block will pause other threads when it needs to process a divergent thread. The original results for a test 30 TB workload was 16 hours runtime on a CPU cluster, and 16.7 hours runtime on a comparable GPU cluster.

In diving into the retailer’s query and dataset, it was observed the data contained sparse fields inside the JSON objects. This means the probability a field would appear in a given record was very low; specifically, over 85% of the fields showed up in less than 0.01% of the records. Because of the sparseness, threads would be very likely to diverge early on in processing. The ideal scenario is for a given set of threads in the same warp to operate on similar data that is processed.
From the CUDA programming guide:
A warp executes one common instruction at a time, so full efficiency is realized when all 32 threads of a warp agree on their execution path. If threads of a warp diverge via a data-dependent conditional branch, the warp executes each branch path taken, disabling threads that are not on that path. Branch divergence occurs only within a warp; different warps execute independently regardless of whether they are executing common or disjoint code paths.
The initial slowness on GPU for processing the frequent get_json_object calls in the retailer queries was confirmed to be due to thread divergence and so the work to optimize this type of processing began.
Improving JSON processing on GPUs
To solve the problem of optimizing the JSON processing with large strings specifically with sparse data, we had to improve the way data was processed inside a warp to increase the probability of similar data being processed by the threads. To progress in performance, we traversed a path of successive optimizations to help work towards an accelerated workload for the retailer.
To provide a test environment to validate our optimizations, we executed single-node benchmarks to demonstrate the effect of the optimization efforts. The environment for the local benchmarks includes AMD Ryzen Threadripper PRO 5975WX with 32-Cores (CPU) and NVIDIA RTX A6000 48GB (GPU). The data used for our benchmarks is five columns and 200,000 rows of generated JSON data based on an approximation of the retailer’s JSON data. The benchmark data is about 9.2 GB uncompressed and 6.4 GB when stored as Parquet with snappy compression. Note that the compression ratio is very low because much of the data is randomly generated. The number of get_json_object calls varies from one to over 50 per column. Both the data and the paths are complex having a nesting level over ten and using array indexes and wildcards.
On a single-node with an NVIDIA GPU which represented a GPU the retailer was using, the benchmarks with the generated JSON data with large strings grew from initially being slightly faster than CPU processing, to over 5x faster after a series of optimizations.

The first technique applied was combining multiple queries for the same data in the same warp. If a large record was being queried across fields in different threads, we could intentionally group them in the same warp to balance thread divergence and reduce the cache pressure. This helped improve our local benchmarks by 3.2x so we already had a big win.

However, we noticed thread divergence could still occur when subsequent queries of the same JSON path happened in the SQL query across warps. That led us to sort the queries lexigraphically. This helped reduce the thread divergence even more because the queries had a higher probability of similarity within the same warp. Once that optimization was implemented, the local benchmarks improved by an additional 10% for a 3.6x speedup.
Lastly, we have started down the path of leveraging a more data-parallel tokenizer from the RAPIDS cuDF library to move away from single character parsing to move diversified string parsing when processing JSON objects. Benchmarks are showing this optimization to be another 50% improvement for an overall 5.6x speedup. The implementation will be released this year.

Key takeaways
Processing large amounts of string data can be a challenge for the GPU, so special optimization is required. The RAPIDS Accelerator for Apache Spark along with cuDF has enhanced JSON processing for improved speedups on GPUs.
Getting started with Apache Spark on GPUs
Enterprises can take advantage of the RAPIDS Accelerator for Apache Spark to seamlessly transition existing Spark workloads to NVIDIA GPUs with zero code change. RAPIDS Accelerator for Apache Spark leverages GPUs to accelerate processing by combining the power of cuDF and the scale of the Spark distributed computing framework.
Get hands-on with JSON processing and the RAPIDS Accelerator for Apache Spark with this Colab notebook, and check out this upcoming GTC 2025 session to learn more.
Future work
Additional optimizations for string processing on GPUs is planned to leverage similar techniques that were used in accelerating JSON to more expressions and functionality.
To follow along or to help contribute, check out the open-source work for RAPIDS Accelerator for Apache Spark and cuDF.
