딥 뉴럴 네트워크(DNN) 모델은 비디오 스트리밍 콘텐츠를 분석해야 하는 애플리케이션에서 일상적으로 사용됩니다. 여기에는 개체 감지, 분류 및 세분화가 포함될 수 있습니다. 일반적으로 이러한 모델은 NVIDIA DGX1과 같은 독립형 서버나 데이터센터 또는 프라이빗 클라우드에서 사용 가능한 서버 또는 하이엔드 GPU가 탑재된 서버에서 학습됩니다.
이러한 시스템은 종종 부동 소수점 32비트 산술을 사용하여 가중치에 대해 더 넓은 동적 범위를 활용합니다. 하지만 모델을 학습한 후에는 컴퓨팅 리소스가 적은 하드웨어의 엣지에 배포해야 하는 경우가 많습니다. 대부분의 경우 가중치에 8비트 정수를 사용하는 것이 유리합니다. 문제는 학습 후 가중치를 반올림하기만 하면 특히 가중치의 동적 범위가 넓은 경우 정확도가 낮아질 수 있다는 것입니다.
이 게시물에서는 INT8 가중치에 최적화된 학습 모델에 대해 알아봅니다. 학습 중에 시스템은 QAT(양자화 인식 학습)라는 바람직한 결과를 인식합니다.
모델 양자화
양자화는 딥 러닝 모델을 변환하여 매개변수와 계산을 더 낮은 정밀도로 사용하는 프로세스입니다. 통상적으로 DNN 학습 및 추론은 IEEE 단정밀도 부동 소수점 형식에 의존해 32비트에서 부동 소수점 모델 가중치와 활성화 텐서의 영향을 나타냅니다. 자세한 내용은 자동 혼합 정밀도를 참조하십시오.
대부분의 DNN은 컴퓨팅 성능이 굉장히 크고 전력 예산이 훨씬 큰 NVIDIA V100 또는 A100 GPU를 사용하여 데이터센터나 클라우드에서 학습되기 때문에 학습 시에는 이 예산을 받아들일 수 있습니다. 그러나 배포 중에 이러한 모델은 컴퓨팅 리소스와 엣지의 전력 예산이 훨씬 적은 디바이스에서 실행해야 하는 경우가 많습니다. 엣지의 컴퓨팅, 메모리, 전력 제약을 고려하면 32비트 전체 표현을 사용한 DNN 추론을 실행하는 것은 실시간 분석에는 실용적이지 않습니다.
컴퓨팅 예산을 줄이는 동시에 모델의 구조와 매개변수 수에 영향을 미치지 않고 낮은 정밀도로 추론을 실행할 수 있습니다. 처음에 양자화된 추론은 텐서와 가중치를 16비트 부동 소수점 숫자로 표현하면서 반포인트 정밀도로 실행되었습니다. 그 결과 컴퓨팅이 약 1.2~1.5배 절감되었지만, 여전히 활용할 수 있는 컴퓨팅 예산과 메모리 대역폭이 일부 있었습니다. 대신 모델은 이제 가중치 및 텐서에 대한 8비트 정수 표현을 통해 훨씬 낮은 정밀도로 정수화됩니다. 그 결과 메모리 용량이 4배 더 적고 처리량이 약 2~4배 빠른 모델이 됩니다.
8비트 양자화는 컴퓨팅 및 메모리 예산을 절약한다는 점에서 매력적이지만 손실이 많은 프로세스입니다. 양자화 중에 작은 범위의 부동 소수점 번호가 고정된 수의 정보 버킷에 압착됩니다. 이로 인하여 정보가 손실됩니다.
32비트 표현을 사용하여 원래 해결할 수 있던 미세한 차이가 이제는 8비트 표현으로 동일한 버킷으로 양자화되기 때문에 손실됩니다. 이는 소수 숫자를 정수로 표시할 때 만나는 반올림 오류와 같습니다. 추론 중에 낮은 정밀도로 정확도를 유지하기 위해서는 이러한 정보 손실로 인해 발생하는 오류를 완화하려고 시도해야 합니다.
NVIDIA TAO Toolkit은 두 가지 방법인 PTQ(Post-Training Quantization) 및 QAT라는 두 가지 방법으로 양자화를 통해 이러한 정보 손실을 모델링하려고 시도합니다.
학습 후 양자화
이름에서 알 수 있듯이 이 메서드는 TAO Toolkit에서 학습된 후 모델에 적용됩니다. 학습은 32비트 부동 소수점 숫자로 표시된 가중치와 활성화를 통해 발생합니다. 만족스러운 모델 정확도로 학습이 완료된 후 모델은 TensorRT INT8 엔트로피 보정기를 사용하여 보정됩니다.
TensorRT의 IInt8EntropyCalibratorV2는 INT8 엔진을 제작할 때 모델을 보정합니다. TensorRT가 INT8 스케일 파일을 생성하는 방법에 대한 자세한 내용은 C++를 사용한 INT8 보정을 참조하십시오. 모델 학습 후 보정 방법에 대한 자세한 내용은 TAO Toolkit 사용 설명서를 참조하십시오.
PTQ는 양자화 오류를 쉽게 모델링하는 방법을 제공하지만 학습된 모델의 가중치를 효과적으로 더 작은 범위로 확장할 수 있다는 내재된 가정이 있습니다. 하지만 이 스케일링이 모델 가중치의 통계를 보존할 수 없는 경우도 있습니다. 그러한 예시 중 하나는 NGC의 PeopleNet 모델 입니다. 이 모델은 FP32 모드로 표현되는 텐서로 학습되었으며 TensorRT INT8 엔트로피 보정기를 사용하여 보정되었습니다. 하지만 그 결과 TensorRT 엔진은 그림 1에서 볼 수 있듯이 여러 개의 가짜 바운딩 상자를 만들어 모델 정확도에 회귀를 일으켰습니다.

양자화 인식 학습
QAT에서는 DNN이 학습된 후 텐서 활성화를 위한 컴퓨팅 확장 요소와는 반대로, 모델을 학습할 때 양자화 오류가 고려됩니다. 학습 그래프는 학습 프로세스의 포워드 패스에서 낮은 정밀도 동작을 시뮬레이션하기 위해 수정되었습니다. 이를 통해 학습 손실의 일부로 양자화 오류가 발생하며, 이 오류는 최적화 도구를 학습 중에 최소화하려고 시도합니다. 따라서 QAT는 학습 중에 양자화 오류를 모델링하는 데 도움이 되며 배포 시 모델의 정확도에 미치는 영향을 완화합니다.
그러나 낮은 정밀도 동작을 시뮬레이션하기 위해 학습 그래프를 수정하는 프로세스는 복잡합니다. 학습 코드를 수정하여 DNN 계층의 가중치에 대해 FakeQuantization 노드를 삽입하고 QDQ(Quantize-Dequantize) 노드를 중간 활성화 텐서로 수정하여 동적 범위를 계산해야 합니다.
또한 모델의 학습 기능에 영향을 미치지 않도록 이러한 QDQ 노드의 배치도 중요합니다. 이러한 모델은 TensorRT 추론 플랫폼을 통해 배포하기 위한 것이기 때문에 융합 컴퓨팅 블록의 끝에만 QDQ 노드를 포함하도록 주의하세요. 예를 들어, TensorRT는 Conv -> Bias -> ReLU 및 Conv -> Bias -> BatchNmalization -> ReLU 컴퓨팅 블록을 결합합니다. 이 경우 QDQ 레이어를 추가하는 것은 ReLU 활성화의 출력 Tensor에만 의미가 있습니다. 자세한 내용은 양자화 인식 학습을 참조하세요.
모든 활성화 계층 유형이 양자화에 적합한 것은 아닙니다. 예를 들어 회귀 계층이 있는 네트워크는 일반적으로 이러한 계층의 출력 Tensor를 8비트 양자화 범위로 연결하지 말아야 하며, 8비트 양자화가 제공할 수 있는 것보다 표현에서 더 미세한 세분화를 필요로 할 수 있습니다. 이러한 계층은 양자화에서 제외되는 경우에 가장 잘 작동합니다.
TAO Toolkit을 사용하여 양자화 인식 교육 실행하기
TAO Toolkit으로 모델을 학습하는 데에는 코드 개발이 필요하지 않습니다. TAO Toolkit은 효과적인 QAT 그래프 구현의 모든 요구 사항을 추상화합니다. 양자화 인식으로 학습하려면 학습 사양 파일의 training_config 구성 요소에 플래그를 추가합니다. 이렇게 하면 train 명령이 모델 그래프를 구문 분석하고 수정하도록 트리거하여 포워드 패스 중에 가중치 및 활성화의 양자화를 활성화하고 모델을 효과적으로 학습합니다. 그림 2는 QAT에서 INT8 배포 가능한 모델을 생성하는 권장 워크플로우를 보여줍니다.
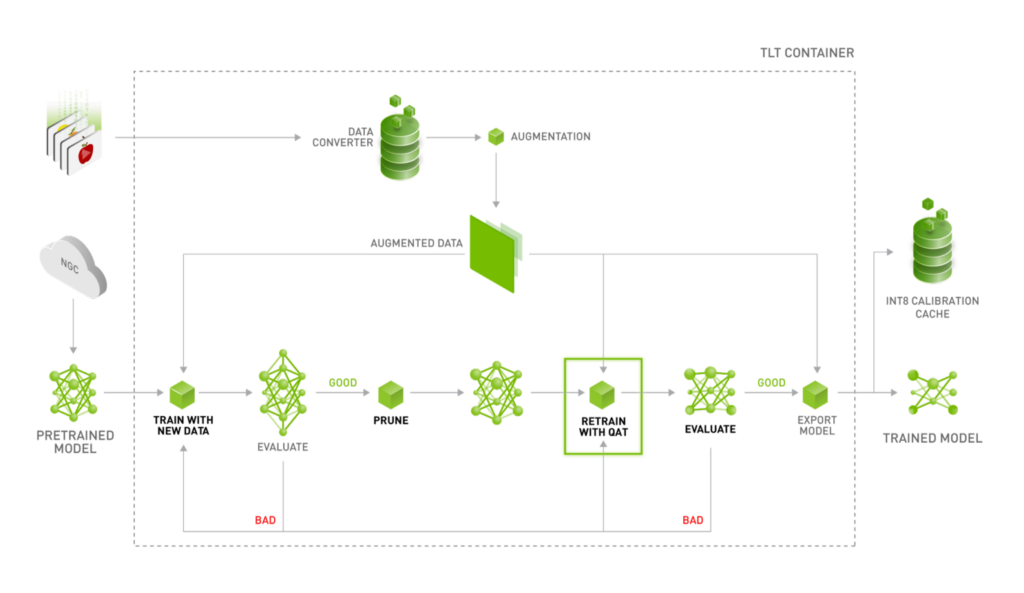
- 가지치기 되지 않은 개체 감지 모델을 학습합니다.
- 학습된 모델을 가지치기하여 정확도를 저하시키지 않고 가능한 한 컴퓨팅 절감을 얻을 수 있습니다.
- QAT가 활성화된 상태로 이 모델을 다시 학습합니다.
- 다시 학습된 모델을 평가하여 가지치기되지 않은 모델에서 회복된 정확도를 확인합니다.
- 모델을 내보내서 DeepStream SDK 또는 컨버터가 읽을 수 있는 .etlt 파일 및 INT8 보정 캐시를 생성하여 TensorRT 엔진을 생성합니다. 내보내기 도중에도 TensorRT 엔진을 생성할 수 있지만, 이 엔진은 내보내가 실행된 하드웨어에만 배포할 수 있습니다.
- 검증 세트에서 생성된 TensorRT 엔진을 평가합니다. QAT는 분류 및 MaskRCNN 모델에 지원되지 않습니다.
예를 들어 사용 사례로서 정수 정밀도(8비트 표현)를 통해 배포에 적합한 TAO Toolkit PeopleNet 모델의 QAT 지원 버전을 학습하는 방법에 대해 논의합니다. PeopleNet 모델을 사전 학습된 가중치로 사용하는 DetectNet_v2 모델을 학습하는 것에 대한 자세한 내용은NVIDIA TAO Toolkit으로 맞춤형 사전 학습된 모델을 사용한 학습을 참조하십시오.
단계에 따라 가지치기되지 않은 DetectNet_v2 모델을 학습하고 가지치기하여 훨씬 작은 가지치기된 모델을 생성하는 것이 좋습니다.
가지치기된 모델이 생성되면 재학습 사양 파일의 model_config 구성 요소를 업데이트하여 다음을 수행합니다.
- 가지치기된 모델을 사전 학습된 가중치로 포함합니다.
- 새로 가지치기한 모델 구조를 가져오도록 load_graph 플래그를 true로 설정합니다.
다음 코드 예제에서는 업데이트된 모델 구성을 보여줍니다.
model_config {
pretrained_model_file: "/path/to/pruned/model"
load_graph: true
num_layers: 34
arch: "resnet"
use_batch_norm: true
objective_set {
bbox {
scale: 35.0
offset: 0.5
}
cov {
}
}
training_precision {
backend_floatx: FLOAT32
}
}다음으로 재학습 사양 파일의 training_config 구성 요소를 업데이트하여 enable_qat 플래그를 설정합니다.
training_config {
batch_size_per_gpu: 24
num_epochs: 120
enable_qat: true
learning_rate {
soft_start_annealing_schedule {
min_learning_rate: 5e-06
max_learning_rate: 0.0005
soft_start: 0.1
annealing: 0.7
}
}
regularizer {
type: L1
weight: 3e-09
}
optimizer {
adam {
epsilon: 9.9e-09
beta1: 0.9
beta2: 0.999
}
}
cost_scaling {
initial_exponent: 20.0
increment: 0.005
decrement: 1.0
}
checkpoint_interval: 10
}나머지 사양 파일 구성 요소는 가지치기되지 않은 모델을 학습할 때의 사양 파일과 동일하게 남을 수 있습니다.
dataset_configevaluation_configaugmentation_configpostprocessing_configbbox_rasterizer_configcost_function_config
이러한 구성 요소에 대한 자세한 내용은 NVIDIA TAO Toolkit을 사용한 커스텀 사전 학습 모델로 학습하기 및 TAO Toolkit 시작하기 가이드를 참조하십시오.
이 모델에 대한 학습을 실행하려면 업데이트된 사양 파일로 train 명령을 사용합니다. train 명령에 대한 샘플 명령줄 사용은 다음과 같습니다.
tao train detectnet_v2 -e $spec_file_path \
-r $experiment_dir_pruned_qat \
-k $KEY \
-n $model_file_string \
--gpus $N다음 변수가 정의됩니다.
- $KEY: 모델을 로드할 키 문자열입니다.
- $experiment_dir_pruned_qat: 출력 결과 디렉터리에 대한 UNIX 스타일 경로입니다.
- $N: 학습 중에 사용할 GPU 수입니다.
- $spec_file_path: UNIX 스타일의 학습 사양 파일 경로입니다.
- $model_file_string: 학습 실행이 완료된 후에 저장되는 최종 모델 파일의 문자열 이름입니다.
- 모델 출력은 $experiment_dir_pruned_qat/weights/$model_file_string.tlt에서 확인할 수 있습니다.
학습이 완료되면 evaluate 명령을 사용하여 검증 데이터세트에서 모델을 평가하여 이 모델의 정확도를 확인할 수 있습니다.
tao evaluate detectnet_v2 \
-e $spec_file_path \
-m $experiment_dir_pruned_qat/weights/$model_file_string.tlt \
-k $KEY \클래스당 평균 정밀도(AP)는 Pascal VOC 챌린지에서 언급된 Pascal VOC 평가 지침에 따라 계산되고 모델의 평균 정밀도(mAP) 메트릭과 함께 터미널에서 출력됩니다. QAT 및 QAT 이외의 학습되지 않은 모델의 컴파일된 결과에 대한 자세한 내용은 이 게시물의 결과 섹션을 참조하세요.
여기서 계산되는 mAP는 QAT를 활성화하지 않고 학습한 모델의 mAP에 가깝습니다. 모델이 만족스러운 것으로 간주된 후에는 export 명령을 사용하여 내 보낼 수 있습니다. export 명령은 양자화된 노드를 찾는 모델 그래프를 구문 분석하고 정리하여 중간 활성화 텐서용 동적 범위 확장 요소를 포함하는 해당 calibration_cache 파일과 함께 .etlt 모델 파일을 생성합니다. etlt_model 파일과 calibration_cache 파일은 컨버터에 의해 소비되어 저정밀도(8비트) TensorRT 엔진을 생성하거나 DeepStream SDK로 직접 사용될 수 있습니다.
다음 코드 예제에서는 export 명령에 대한 사용을 보여줍니다.
tao export detectnet_v2
-m $experiment_dir_pruned_qat/weights/$model_file_string.tlt \
-o $output_model_path \
-k $KEY \
--data_type int8 \
--batch_size N \
--cal_cache_file $calibration_cache_file \
--engine_file $engine_file_path다음 변수가 정의됩니다.
- $output_model_path: 출력 .etlt 모델 파일의 UNIX 경로입니다.
- $KEY: 모델을 로드하고 .etlt 모델 파일을 저장하는 문자열 키입니다.
- –data_type: TensorRT 파일의 정밀도(보정 캐시를 생성하기 위해 INT8로 설정될 예정).
- N: 출력 TensorRT 엔진의 배치 크기 값입니다.
- $calibration_cache_file: 활성화 Tensor를 위한 스케일을 포함하는 출력 캐시 파일의 UNIX 경로입니다.
- $engine_file_path: 출력 TensorRT 엔진 파일의 UNIX 경로입니다.
export 명령을 사용하여 생성된 엔진은 export 명령이 실행된 플랫폼에서 추론을 실행하는 데만 사용할 수 있습니다. 이 모델을 다른 플랫폼에 배포하려면 .etlt 모델 파일을 calibration_cache와 함께 사용하여 추론 플랫폼에서 컨버터를 실행합니다.
Jetson 플랫폼에서 배포할 때, 텍스트 편집기에서 calibration_cache 파일의 첫 번째 행을 편집하여 해당 JetPack 빌드의 TensorRT 버전을 반영합니다. 예를 들어 JP4.4의 경우 첫 번째 라인의 TensorRT 버전 번호를 7000에서 7100으로 업데이트합니다.
QAT 생성 보정 캐시 파일은 외장 x86 기반 GPU(NVIDIA T4, V100 및 A100) 및 NVIDIA Jetson 플랫폼(AGX Xavier 및 Xavier NX)에서만 배포할 수 있습니다.
이전에 사용한 export 명령을 사용하여 생성된 모델은 DLA의 INT8 모드에서 배포하는 것에 대해 호환되지 않습니다. DLA로 이 모델을 배포하려면 QAT 학습 .tlt 모델 파일에서 PTQ를 사용하여 보정 캐시 파일을 생성해야 합니다. 그렇게 하려면 export 실행 시 명령줄에 force_ptq 플래그를 설정합니다. DetectNet_v2 모델을 내보내기 위한 이 플래그 세트가 있는 샘플 export 명령은 다음 예시와 같습니다.
tao export detectnet_v2 \
-e $spec_file_path \
-m $experiment_dir_pruned_qat/weights/$model_file_string.tlt \
-o $output_model_path \
-k $KEY \
--data_type int8 \
--batch_size N \
--cal_cache_file $calibration_cache_file \
--engine_file $engine_file_path \
--force_ptqforce_ptq 옵션을 사용하면 모델의 스케일 팩터를 생략하고 QAT 학습 모델에서 TensorRT IInt8EntroplyCalibrator2를 사용하여 스케일 팩터를 생성합니다. 이 메서드는 모델의 모든 중간 텐서에 대한 스케일을 생성합니다. GPU와 달리, DLA는 현재 Conv-> Bias -> ReLU 및 Conv -> Bias -> BatchNormalization -> ReLU 블록을 단일 연산자로 융합하지 않습니다. 따라서 모든 중간 텐서에는 양자화 스케일이 필요합니다. detectnet_v2 서브태스크 학습, 평가, 가지치기, 내보내기 및 컨버터의 사용에 대한 자세한 내용은 TAO Toolkit Getting Started Guide를 참조하세요.
INT8 모드를 사용하여 DLA에 PeopleNet v2.0 모델을 배포하기 위해 export의 force_ptq 모드를 사용하여 양자화 스케일을 생성하고 evaluate를 사용하여 모델을 평가했습니다. 그 결과는 용도에 맞게 제작된 모델 표로 만들어집니다.
결과
표 1은 PTQ를 사용하여 INT8 모드에 배포된 FP32 학습 모델과 비교하여 QAT로 학습된 INT8 모델에 대한 정확도 비교를 보여줍니다. 숫자는 기준 FP32 정확도에 대해 비교됩니다.
QAT를 사용하여 학습을 받은 경우 기준 FP32와 관련해 정확도 차이가 1% 이내입니다. 동일한 모델에서 PTQ를 적용하면 정확도가 크게 떨어져 모델을 사용할 수 없게 됩니다. QAT는 INT8 정밀도로 추론을 실행하기 위한 효과적인 학습 기술입니다.
| 기준 FP32 mAP | PTQ를 통한 INT8 mAP | QAT를 통한 INT8 mAP | |
| PeopleNet-ResNet18 | 78.37 | 59.06 | 78.06 |
| PeopleNet-ResNet34 | 80.2 | 62 | 79.57 |
표 1. QAT 학습 INT8 모델과 비교한 PTQ INT8 모델의 정확도 비교.
동일한 모델 아키텍처에 대해 INT8 모델과 유사한 정확도를 유지할 수 있다는 것은 동일한 하드웨어에서 상당한 추론 성능 향상을 제공합니다. 표 2는 FP16 및 INT8 정밀도를 위한 두 PeopleNet 모델의 T4 추론 성능을 비교합니다. 이 두 모델에서 평균적으로 추론 FPS가 2배 가까이 증가한 것을 볼 수 있습니다. 즉, 모델 아키텍처나 GPU를 변경하지 않고 배포 플랫폼의 스트림 수를 효율적으로 두 배로 늘릴 수 있습니다.
| FP16 추론 성능(FPS) | INT8 추론 성능(FPS) | |
| PeopleNet-ResNet18 | 762 | 1517 |
| PeopleNet-ResNet34 | 513 | 1038 |
표 2. INT8 추론 성능과 비교한 FP16.
여기에 포함된 샘플 예측은 그림 1과 동일한 이미지를 보이지만 QAT를 활성화한 상태로 학습된 INT8 모델에서 추론을 실행하고 있습니다. 가짜 감지는 이제 제거되었고 정확도가 크게 향상되었습니다.

결론
양자화 인식 교육은 정확도를 저하시키지 않고 더 낮은 정밀도의 INT8 배포를 위해 DNN을 학습하는 데 도움이 됩니다. 이는 학습 중에 양자화 오류를 모델링하여 FP16 또는 FP32에 비해 정확도를 유지하는 데 도움이 됩니다. PTQ도 여전히 TAO Toolkit을 통해 지원되지만 INT8 정밀도를 사용하여 배포할 계획이면 QAT를 사용한 교육을 권장합니다.
이 게시물에서는 PeopleNet 모델이 QAT를 사용하여 모델을 학습하는 프로세스 안내 샘플로 사용되었지만, TAO Toolkit에서 지원되는 다른 개체 감지 모델 과 함께 사용할 수도 있습니다. QAT에 대한 자세한 내용은 TAO Toolkit 사용 설명서의 모델 학습시키기를 참조하십시오.
이 블로그에 열거된 SDK의 대부분의 독점 액세스, 얼리 액세스, 기술 세션, 데모, 교육 과정, 리소스는 NVIDIA 개발자 프로그램 회원은 무료로 혜택을 받으실 수 있습니다. 지금 무료로 가입하여 NVIDIA의 기술 플랫폼에서 구축하는 데 필요한 도구와 교육에 액세스하시고 여러분의 성공을 가속화 하세요.